


















 3657
3657
日前举行的“中国计算机学会芯片大会”上,英特尔研究院副总裁、英特尔中国研究院院长宋继强博士发表了题为“坚持半导体底层技术创新,激发算力千倍级提升”的主题演讲。在演讲中,针对“突破算力瓶颈,满足多元计算需求”这一产学研界所普遍关注的热门话题,分享了英特尔的最新洞察,以及在相关领域所取得的技术进展。
传统计算架构面临瓶颈
“数字经济增长十分依赖底层基础设施支持,包括计算能力、计算效率,如何把目前行业的传统做法通过数字化技术、智能化技术来更新,会对数字经济的增长带来量和质的变化”,宋继强表示。
如果把数字经济的基础设施看成一个底座,那么,如何更好地分配算力、如何进行调度以应对不同的应用,以及对延时、计算量、并发以及不同加速类型、数据类型的要求,实际上构成了一个很复杂的算力网络。近年来,我国提出把计算和网络融合起来,尤其是“东数西算”工程,从技术方面来看,实际上就是在构造一个以能源、计算能效性为优先综合布局的新型算力网。
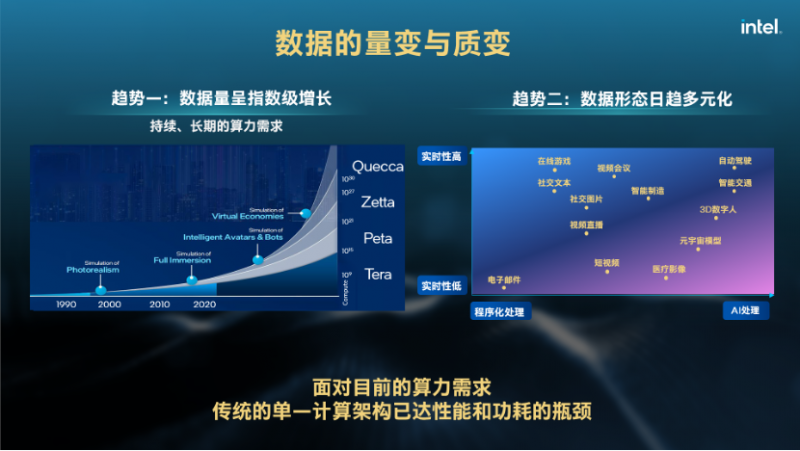
未来,各种应用要在数字化转型中真正达到好的效果,都要依靠数据全生命周期的运转,从采集到预处理、分析,再到决策、交付。而在数字化转型的过程中,数据将继续呈指数型增长。并且,数据将有很多种不同的形态。
宋继强指出,未来的数据处理可以从实时性和智能化两个维度进行划分,可以发现很多数据都需要智能化处理,并且相关的应用对延时要求都比较高,这意味着未来的数据处理,无论是算力还是网络构造,都面临着非常独特的要求。从数据量和质的演变来看,传统的单一计算架构肯定会遇到性能和功耗的瓶颈。
打破算力瓶颈,应对数据处理挑战
如何应对未来数据处理的挑战?宋继强指出,突破算力的瓶颈是第一步,即通过不同方式来解决多样化数据的计算有效性;第二步就是对现有算力进行提升,同时还需考虑到绿色计算这个因素,未来的计算方式能耗不能太大,也就是说,需要以能量优化的方式去解决未来的数据处理问题。
“异构计算和异构集成是我们解决这些问题的新抓手”,宋继强解释说,“异构计算就是用不同的架构处理不同类型的数据,真正做到‘用好的工具解决好的问题’;异构集成则是帮助我们用更好的集成组合方式,把不同工艺下优化好的模块更好地集成到未来的解决方案中,从而更加高效地处理复杂计算。”
英特尔的异构计算布局——“XPU+oneAPI
在未来的异构计算体系中,软硬件结合变得越来越重要。宋继强强调,硬件实现了不同的架构积累,也需要有一套方便且好用的软件,只需上层应用者指定功能需求,下层就可以随着异构变化。

具体到英特尔自身的异构计算布局,体现为“XPU+oneAPI”,既有全面的硬件架构布局,覆盖从终端到边缘再到服务器,在CPU、GPU、IPU、FPGA、AI加速器等领域,都有具有代表性的成熟产品,又有oneAPI这一开放统一的跨架构编程模型,让现有的和未来将出现的新硬件都能很好地发挥能力。
异构集成,实现异构计算的关键技术
此外,实现异构计算常常需要将不同制程节点的芯片封装在同一个大封装里,这时就需要应用异构集成,也就是先进封装技术,来满足尺寸、成本、带宽等方面的要求。宋继强介绍,英特尔在异构集成上主要有两项技术,2.5D封装技术EMIB能把在平面上集成的芯片很好地连接起来,3D封装技术Foveros则可以通过把不同尺寸的芯片在垂直层面上封装,进一步降低封装凸点的间距,提高封装集成的密度。
宋继强补充,Foveros Omni和Foveros Direct是英特尔在3D封装上未来会使用的两种技术。在上面是一个大的芯片,底下是几个小芯片的时候,Foveros Omni可以把不同芯片之间互连的接触点间距微缩到25微米,同时还可以通过封装边上的铜柱直接给上层芯片供电,和EMIB相比有接近4倍的密度提升。Foveros Direct则通过一种更高级的不需要焊料、直接让铜对铜键合的技术,实现更低电阻的互连,进一步缩小凸点间距到10微米以下,将整个互连的密度提升到新的数量级。
目前,英特尔迄今为止最复杂的高性能计算SoC Ponte Vecchio就运用了英特尔在异构计算和异构集成上的新技术,集成了来自5个不同制程节点的47种不同晶片,而下一代旗舰级数据中心GPU代号Rialto Bridge将进一步大幅提高计算密度、性能和效率,同时通过oneAPI提供软件一致性。

如何应对未来复杂芯片设计和应用?
芯片设计正变得越来越复杂,将实现不同晶片、不同制程节点的集成,并且这些复杂芯片还将组建成更为庞大的系统。未来芯片设计将出现哪些颠覆性的变革?针对这些复杂芯片如何降低应用门槛?
宋继强表示,对不同芯片进行封装集成,在硬连接方面首先面临挑战,不同生产厂商在凸点、连接点间距、电气特性,包括电阻、电容、焊锡制造的要求都不太一样,硬件连接方面还缺乏统一的标准。
其次还面临测试挑战。当不同厂商的芯片连接之后,如何测试?如何定位问题源头?这些问题都需要去解决。此外,未来如果做整个系统的设计,如果自己的芯片可能要和其他厂商的芯片封装在一起的,或是本身就要考虑多封装系统,是否在EDA工具方面就要把先进封装的特性构建其中,从而实现模拟验证?这也是未来的挑战。
至于如何降低复杂芯片的应用门槛?宋继强表示,新的架构还在涌现,包括未来架构的制程、接口涉及的内存控制等,都会发生变化。如果考虑通过先进封装的方式进行连接,未来的带宽、延迟特性可能和现在又不一样,所以需要面向未来去设计。
沿着“面向未来设计”的这一思路不难发现,英特尔在尽最大可能推动oneAPI的开放性。在异构计算设计体系中,必须要有更为全面的考虑和设计方法。宋继强指出,原来也有一些类似异构计算编程的框架或库,比如OpenCL也兼容CPU、GPU和FPGA,但oneAPI的好处在于它非常开放,行业内多家公司都在参与,除英特尔之外,甚至包括英伟达的GPU、AMD的x86处理器也有相应的Level Zero接口包含进来。总而言之,oneAPI能够比较全面地考虑已有的异构硬件,能够把它们比较好地调度起来,同时也在考虑如何把未来不同厂商的硬件,包括未来异构封装的技术,不论是数据的传输,还是控制方面的调度、协调等,都要进行充分考虑。
在英特尔的异构计算体系中,oneAPI可以理解为现在和未来硬件都能良好工作的统一框架。最底层是硬件抽象层,它定义统一的描述方法,把不同架构的硬件,以及来自不同厂商的硬件,用统一的方式向上层开发人员给出描述;再向上是底层高性能库,针对不同的、常用的计算内核分别做优化,同时,这一层还提供不同的语言,比如DPC++、SYCL,都可以支持并行编程。
以上两层是oneAPI主要的工作,基于这些就可以对接现在或未来应用开发领域比较流行的中间件和开发框架,从而很好地达到上层应用开发和底层异构硬件之间的解耦,很好地发挥出硬件能力。
据了解,oneAPI目前在全球都开展了开放式的合作,很多企业、初创公司、研究机构加入,在中国,英特尔和中科院计算所去年建立了中国首个oneAPI卓越中心。

宋继强补充,针对不同领域计算内核的加速库,有着非常多的工作量,因为不同领域有非常细分的性能加速库,未来还可能包含一些专门针对数据流加速的库。他强调,oneAPI是一个很复杂的、可以帮上层应用开发者降低开发门槛的工具,从它目前覆盖的广度来看,业界还没有能对标的工具。
摩尔定律坚定不移的推手——还需制程、器件创新
为了突破算力瓶颈,除了异构计算与异构集成技术之外,还需要坚持推进摩尔定律,打造功耗更低,性能更强的半导体。
宋继强介绍了英特尔的制程工艺革新和路线图。英特尔的制程工艺革新主要包括三大技术:在工具上,英特尔自Intel 4将开始使用下一代基于高数值孔径的极紫外光刻(EUV)技术,降低整个制程工艺的复杂度,提高良率;晶体管结构上,Intel 20A将使用全新的RibbonFET结构,进一步降低平面上晶体管所占面积,同时可以有更快的驱动速度,也增加驱动电流的强度;供电层面,Intel 20A将同样启用全新的PowerVia技术,实现底部给所有上层功能逻辑部件供电,把供电层和逻辑层完全分开,从而可以更有效地使用金属层,大幅减少绕线和能量消耗。
据了解,英特尔计划在四年内推进五个制程节点:Intel 7已经开始批量出货;Intel 4将于今年下半年投产,采用EUV技术,将晶体管的每瓦性能将提高约20%;Intel 3将于2023年下半年投产,在生产过程当中会更大量地使用EUV,在每瓦性能上实现约18%的提升;Intel 20A预计将于2024年上半年投产,通过RibbonFET和PowerVia这两项技术在每瓦性能上实现约15%的提升;最后,Intel 18A预计将于2024年下半年投产,在每瓦性能上将实现约10%的提升。宋继强表示,目前英特尔在Intel 18A和Intel 20A上都取得了不错的进展。

前沿研究正在带来新的可能性
展望未来,还有一些新兴、前沿研究领域有望为计算带来更多的可能性。宋继强分享了英特尔在以下三个领域所取得的主要进展:组件研究、神经拟态计算和集成光电。
组件研究向来都是英特尔生产、制造、研发部门很重要的一项研究工作,主要围绕三方面展开:第一,是提供更多的核心微缩技术,涵盖混合键合(hybrid bonding)技术、CMOS晶体管3D堆叠技术和对晶体管新材料的探索;第二,通过叠加新的晶体管材料和结构,给硅晶体管注入新的功能,包括增强模式的高K氮化镓晶体管和硅FinFET晶体管的组合技术,以及反铁电体材料的嵌入式内存;第三,是量子领域的工作,包括应用在逻辑计算的磁电自旋电子器件,磁畴壁电子器件和300毫米量子比特制程工艺流程。
神经拟态计算可以直接模拟人类神经元的形式构造芯片底层的计算单元,再通过脉冲神经网络的方式编程实现人工智能算法,与传统上主要使用CPU和GPU,靠堆乘加器的方式提供算力的模式相比,可以实现能效比千倍级以上的提升。宋继强介绍,目前英特尔的神经拟态计算芯片已经发展到了第二代Loihi 2,基于Intel 4制程工艺,速度比上一代提升了10倍,单个芯片里的神经元数量也提升了8倍,达到100万。同时,英特尔也推出了一套完整的开源的软件框架Lava对神经拟态计算的开发提供全面支持,并和北京大学、复旦大学、鹏城实验室、中科院自动化所、联想等近200家国内外合作伙伴一起提升计算的效率。
在集成光电上,英特尔则致力于大幅提高光电转换效率。在关键技术构建模块上,英特尔基于CMOS工艺,实现了在一个平台上集成所有的关键光学技术构建模块,包括光的产生、放大、检测、调制等等,大幅降低了尺寸和功耗;在器件层面,英特尔研制了一个集成在硅晶圆上的8波长激光器阵列,提升了准确性和能效比,为以后光电共封装和光互连器件的量产铺平了道路。此外,英特尔也继续和大学合作,在高速光互连、I/O技术、性能扩展和节能方面做广泛的研究。

 下载ECAD模型
下载ECAD模型




