


 2.4万
2.4万
在全球 AI 高性能芯片市场中,英伟达的芯片产品采用最前沿半导体工艺和创新 GPU 架构保持行业的领先地位。目前,英伟达的 A100 芯片在主流 AI 大模型训练中占据重要市场份额,H100 虽性能强劲但被各种限制。AI 高性能芯片未来将不断迭代升级,持续推动大模型性能和能力的持续提升。
在国内,AI 高性能芯片近年来发展速度加快。其中,华为昇腾主要包括 310 和 910 两款主力芯片,其中昇腾 910的 FP16 计算能力,其能效比在行业中处于领先水平,因为不能上市,所以不做过多讨论。寒武纪是中国具有代表性的另一本土 AI 芯片厂商,公司先后推出了思元 290 和思元 370 芯片及相应的云端智能加速卡系列产品、训练整机。公司已经登陆科创板,并且市值居于芯片行业前列。
2025年,随着国产大模型的持续迭代升级,用户对调用量的不断提升,国内大厂对GPU的需求将会持续提升。外围采购受限制,只能国产当自强。今日,我们就来梳理一下国内还未上市的本土GPU芯片企业,看一看这些企业的竞争实力,未来谁会超越寒武纪,谁能成为下一个“中国英伟达”。
选取的企业主要有:摩尔线程、壁仞科技为最类似英伟达的企业;燧原科技、沐曦科技最接近AMD的企业;算能有望成为博通这类专注ASIC类的企业;昆仑芯、平头哥、登临科技、天数智芯等也会成为各自领域GPU的领头羊。
一、主要GPU公司介绍
1、燧原科技
1.1、公司介绍
燧原科技成立于 2018 年 03 月 19 日,是国内第一家同时拥有高性能云端训练和云端推理产品的创业公司,也是国内首个发布第二代人工智能训练产品组合的公司。公司专注于人工智能领域的云端算力平台,提供具有自主知识产权的高算力、高能效比、可编程的通用人工智能训练和推理产品。
1.2、发展历程与成果
2018 年 8 月获腾讯领投的 Pre-A 轮融资 3.4 亿元人民币。2019 年 6 月完成 A 轮 3 亿元人民币融资,同年 12 月发布 “云燧 T10”。2020 年 5 月完成 B 轮 7 亿元人民币融资,同年 12 月发布 “云燧 i10”。2021 年 1 月完成 C 轮融资 18 亿元人民币,同年 7 月发布第二代人工智能训练产品组合。2022 年 9 月发布云燧智算机;2023 年以 110 亿人民币的企业估值入选《2023胡润胡润全球独角兽榜》,排名 668。

图|燧原科技发展历程,来源:公司官网
1.3、创始人介绍
赵立东先生是燧原科技创始人、董事长/CEO,拥有美国犹他州立大学电子与计算机硕士学位和清华大学电子工程学士学位。
赵立东先生2007至2014年服务于AMD,历任计算事业部高级总监,负责CPU/APU产品规划,市场分析及拓展;产品工程部高级总监,负责CPU/GPU/APU及多个相关核心IP的研发,团队规模超过千人,并参与成立中国研发中心。2014年12月加入紫光通信科技集团有限公司担任副总裁,主管半导体投资相关工作。2015年3月兼任紫光集团旗下锐迪科微电子公司总裁,董事。2017年3月任紫光集团有限公司副总裁,负责重大专项的谈判和筹建。2018年3月成立燧原科技,主要负责公司的战略规划、融资和业务运营。
张亚林先生是燧原科技创始人兼COO,2018年3月成立燧原科技,主要负责公司的产品规划、研发和生产运营。
张亚林先生2000至2007年服务于上海奇码数字信息有限公司,担任设计部主管。领导团队开发了ZJ1.0/ZJ2.0/ZJ2.A系列机顶盒芯片,主要负责内部架构和嵌入式处理器设计。2008年加入AMD,历任资深芯片经理、技术总监。曾经作为全球芯片研发主要负责人之一,在AMD上海研发中心成功领导开发并量产了多颗世界级芯片,拥有丰富的工程和产品化实战经验。领导开发了全球目前最大的融合芯片APU,并一次量产成功,该款芯片成功用于小霸王最新发布的Z+游戏电脑。
2、壁仞科技
2.1、公司简介
壁仞科技成立于 2019 年,总部位于上海。该公司专注于计算机图形芯片设计,旗下拥有壁砺™100P 系列和壁砺™104 系列等产品,产品适用于人工智能深度学习等通用计算领域。
2.2、发展历程与成果
2020 年 6 月完成 A 轮融资 11 亿元人民币;2021 年3月完成B轮融资,累计融资额超 47 亿元人民币。2022 年 3 月点亮首款通用 GPU,创国产芯片算力纪录,8 月发布首款通用 GPU 芯片,创全球算力新纪录,9 月在权威 AI 评测 MLPerf 获多项全球第一。2023 年产品获 “中国芯” 优秀技术创新产品荣誉,还加入了多个产业联盟和获得多项合作认证。2024年3月,壁仞科技加入大模型应用生态共同体。
2.3、创始团队
团队由国内外芯片和云计算领域核心专业人员、研发人员组成,在GPU、DSA(专用加速器)和计算机体系结构等领域具有深厚的技术积累和独到的行业洞见。
创始人:张文
拥有哈佛大学法学博士学位,早年华尔街资深投资人,2011年出任映瑞光电科技公司CEO,2018年担任商汤科技总裁。张文并非技术出身,但具有敏锐的商业洞察力和强大的资源整合能力。他成功组建了壁仞科技的核心团队,带领公司在短时间内获得了大量融资,并推动了首款通用GPU芯片BR100系列的研发和发布,使壁仞科技成为国产高端GPU芯片领域的重要企业。
CEO:李新荣
毕业于美国密苏里大学,获得电子工程硕士学位。在GPU领域拥有超过30年的丰富经验,曾在AMD就职15年,担任全球副总裁、中国研发中心总经理,负责AMD大中华区的研发建设和管理工作,构建了规模达数千人的研发团队,并实现了团队研发能力从单项目到覆盖“端到端”完整项目流程的重大突破。2021年8月,加入壁仞科技,出任联席CEO,专注组织、管理及产品设计端。
洪洲
曾担任海思自研GPU负责人和首席架构师,还就职于英伟达,拥有30年GPU架构设计经验。在海思负责自研GPU的项目,主导了GPU团队的组建,并成功推出了全球领先的自主IP GPU芯片。加入壁仞科技后,在芯片架构设计和技术研发方面发挥了重要作用,为公司首款通用GPU芯片BR100的成功研发做出了重要贡献。
2.4、主要产品
2.4.1、模组
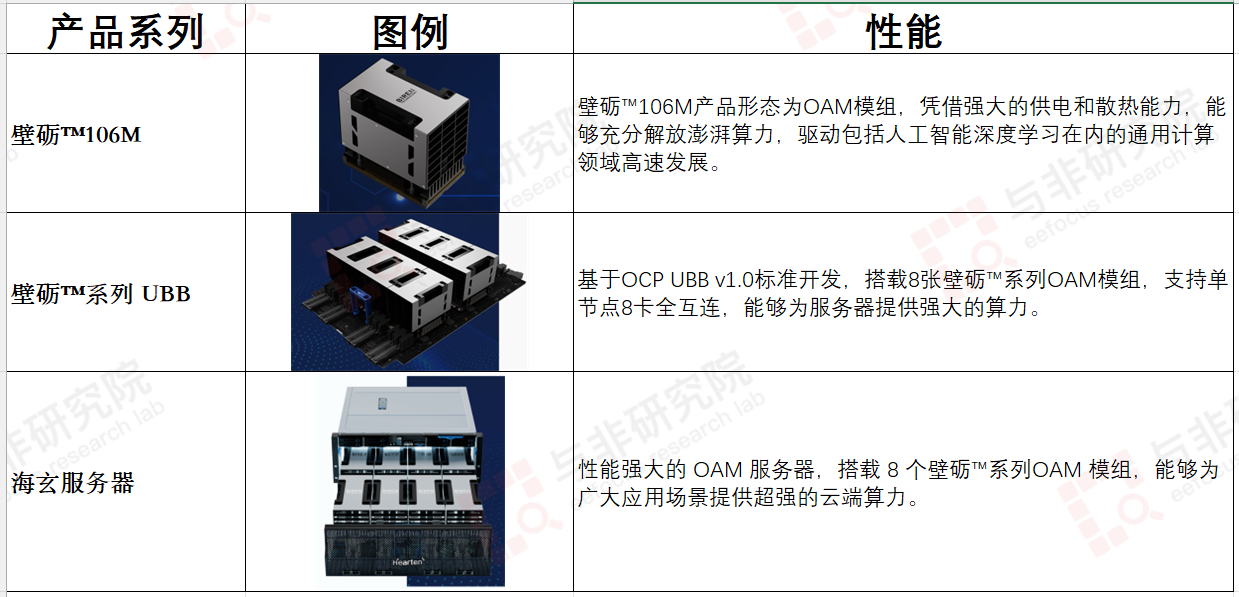
图|壁仞科技主要产品,来源:与非研究院整理
2.4.2、软件开发平台

图|BIRENSUPA平台框图,来源:公司官网
BIRENSUPA™是一个具有完整功能架构的软件开发平台,包括硬件抽象层、壁仞原创BIRENSUPA™编程模型和BRCC编译器,深度学习和通用计算加速库、工具链,支持主流深度学习框架和自研推理加速引擎,并配备针对不同场景的应用SDK等,能够为开发者提供高效的应用开发平台,软硬件协同,探索未来的无限可能。
3、摩尔线程
3.1、公司简介
摩尔线程成立于 2020 年 10 月,总部位于北京,以全功能 GPU 为核心,致力于向全球提供加速计算的基础设施和一站式解决方案,为各行各业的数智化转型提供强大的 AI 计算支持。
创始人张建中,本科毕业于南京理工大学计算机系,后曾在戴尔、惠普等IT巨头公司担任要职。2005年加入英伟达,成为全球副总裁兼中国区总经理。其任职期内,不断开拓英伟达GPU在中国的生态系统,英伟达GPU在中国的市占率从2008年的不到50%,升到了2020年的80%。
3.2、产品与服务
摩尔线程专注于研发设计全功能 GPU 芯片及相关产品,支持 AI 计算加速、 3D 图形渲染、超高清视频编解码、物理仿真与科学计算等多种组合工作负载。
摩尔线程构建了从芯片到显卡到集群的智算产品线,依托全功能 GPU 的多元计算优势,旨在满足不断增长的大模型训练和推理需求,以绿色、安全的智能算力,大力推动大模型、AIGC、科学计算、数字孪生、物理仿真、元宇宙等应用的落地和千行百业的高质量发展。

图|从芯片到集群,加速国产算力规模化供给能力,来源:公司官网
3.3、发展历程与成果
2021 年获国家高新技术企业认定,完成两轮融资数十亿,还完成 20 亿的 A 轮融资。2022 年提出 “元计算” 概念,发布 MUSA 统一系统架构、第一代多功能 GPU 芯片苏堤及多款显卡,还推出了 AlphaCore 的 GPU 物理引擎等。2023 年举办夏季发布会推出新产品与技术更新,获评 “2022-2023 年半导体与集成电路最具投资价值公司 TOP10” 等,还完成了 UE5 在国产显卡上的首次适配。

图|夸娥 (MTT KUAE) 全功能 GPU 智算集群,来源:公司官网
3.4、夸娥全栈解决方案
夸娥(MTT KUAE)是摩尔线程智算中心全栈解决方案,基于大模型智算加速卡和 AI 大模型训推一体机,以一体化交付的方式解决大规模 GPU 算力的建设和运营管理问题。
夸娥(MTT KUAE)是以全功能 GPU 为底座,软硬一体化、完整的系统级算力解决方案,包括以夸娥计算集群为核心的基础设施、夸娥集群管理平台(KUAE Platform)以及夸娥大模型平台(KUAE ModelStudio),旨在以一体化交付的方式解决大规模 GPU 算力的建设和运营管理问题。
3.5、MTT KUAE Platform
夸娥集群管理平台除了包含 Kubernetes 集群的标准能力,还针对智算场景创新地提供了大量功能。
深度集成全功能 GPU 计算、网络和存储,可批量管理 GPU 驱动,降低适配和运维成本
通过虚拟集群、企业空间、项目为不同组织及人员提供多维度的隔离方式。支持 GPU 共享,内置多 GPU 感知调度最佳实践,提升资源利用率并最大化业务性能。提供物理机、存储、网络、集群组件、工作负载的统一可观测平台,加快问题定位,降低解决成本。深度整合业务与设备数据,通过自动巡检及细粒度的监控告警,提前发现潜在问题
3.6、MCCX D800集群计算单元

图|集群计算单元 MCCX 一体机,来源:公司官网
3.7、摩尔线程全功能显卡
智娱摩方,体现了「智」「娱」两个方面,基于该平台,不仅可以尽情享受游戏的乐趣,也能够拥有探索和实践 AI 的机会,让更多的玩家和开发者能够更方便、更畅快地体验到摩尔线程显卡。目前,智娱摩方搭载了摩尔线程 MTT S80 / S70 游戏显卡,不仅为游戏玩家提供强大的的 3D 渲染能力,还可以为学生和研究人员等提供在智能计算、通用计算和多媒体处理等方面的完整 GPU 能力。
智娱摩方搭载摩尔线程 MTT S80 / S70 全功能显卡,其拥有完整的四大功能引擎,能够在 PC 环境下支持 3D 图形渲染、H.265 / H.264 等主流视频格式的编解码、通用计算等多种组合工作负载,同时提供计算机视觉、自然语言理解等经典 AI 模型加速。

图|MTT S4000大模型智算加速卡,来源:公司官网
摩尔线程大模型智算加速卡 MTT S4000,采用第三代 MUSA 架构,配备了 128 个 Tensor 核心,单卡支持 48GB 显存和 768GB/s 的显存带宽。基于摩尔线程自研 MTLink 技术,MTT S4000 可以支持多卡互联,支持千卡集群基础设施建设,加速千亿参数大语言模型计算。同时,MTT S4000 提供先进的图形渲染能力、视频编解码能力和超高清 8K HDR 显示能力,助力 AI 计算、图形渲染、多媒体等综合应用场景的落地。
尤为重要的是,基于摩尔线程自研的全功能 GPU MUSA 生态架构,MTT S4000 可以充分兼容现有软件生态,实现代码零成本迁移到 MUSA 平台。
4、天数智芯
4.1、公司简介
上海天数智芯半导体有限公司成立于 2015 年,是中国领先的通用GPU 高端芯片及超级算力系统提供商。天数智芯致力于开发自主可控、国际领先的高性能通用GPU产品,探索通用GPU赶超发展道路,加快建设自主产业生态,为全产业提供高端算力解决方案。
4.2、发展历程与成果
2018年2月完成A轮融资,6月正式启动通用GPU芯片设计。2019 年完成B轮融资,发布首款云端先进制程 GPGPU 产品 “天垓 100”,是国内首款自主研发的、基于 Chiplet 技术的先进制程GPGPU 芯片。2020年5月"天垓100芯片"启动流片,12月"天垓100芯片"成功点亮。2021 年完成数亿元 C轮融资,"天垓100芯片"及"天垓100加速卡"正式发布,其产品在云计算、人工智能等领域得到应用,为相关企业提供算力支持。2022年4月,"天垓100"系列产品累计订单接近2亿人民币,5月"智铠100芯片"成功点亮,8月DeepSpark开源社区成立及百大应用开放平台正式上线,12月“智铠100系列加速卡”正式发布。
4.3、主要产品
4.3.1、加速卡

图|公司主要产品,来源:与非研究院整理
4.3.2、软件栈
天数智芯软件栈是一个针对天数智芯硬件平台打造的高性能异构计算平台兼容国内外主流生态,针对深度学习和通用计算应用的开发和部署提供了一套完善而高效的软件栈工具。

图|软件栈架构,来源:公司官网
5、登临科技
5.1、公司介绍
通用计算领军企业登临科技,成立于2017年底,专注于芯片研发与技术创新,致力于打造云边端一体、软硬件协同的前沿芯片产品和平台化基础系统软件。公司自主创新的GPU+(基于GPGPU的软件定义的片内异构计算架构),在兼容CUDA/OpenCL在内的编程模型和软件生态的基础上,通过架构创新,完美解决了通用性和高效率的双重难题。
作
为国内首个实现规模化商业落地的GPU企业,登临首款基于GPU+的创新AI计算加速器-Goldwasser已规模化运用在各个应用场景,成功填补了国内GPGPU领域技术、产品及商业方面的空白。

图|公司产品亮点,来源:公司官网
未来,登临将继续秉承核心IP全自研的架构实现,以AI计算为主线,以创新为灵魂,加强核心IP自主研发,加速产品在高级自动驾驶,图形加速等相关领域的开拓创新和商业化进程。
5.2、发展历程与成果
在智能安防领域,登临科技的芯片被广泛应用于视频监控设备中,能够实现实时的目标检测、行为分析等功能;在智能驾驶领域,其芯片为汽车的自动驾驶系统提供算力支持,帮助车辆实现环境感知、决策规划等任务。
5.3、主要产品
登临科技自主创新的GPU+体系结构(软件定义的异构人工智能计算平台),完美地解决了通用性和高效率的双重难题,在提供具备CUDA/OpenCL硬件加速能力的前提下,不仅全面支持各类流行的人工智能网络框架及底层算子,且相对于国际主流推理卡在功效上有3倍以上的提升。

图|公司主要产品,来源:与非研究院整理

图|主要应用场景,来源:公司官网
6、沐曦科技
6.1、基本信息
沐曦集成电路(上海)股份有限公司,于2020年9月成立于上海,并在北京、南京、成都、杭州、深圳、武汉和长沙等地建立了全资子公司暨研发中心。沐曦拥有技术完备、设计和产业化经验丰富的团队,核心成员平均拥有近20年高性能GPU产品端到端研发经验,曾主导过十多款世界主流高性能GPU产品研发及量产,包括GPU架构定义、GPU IP设计、GPU SoC设计及GPU系统解决方案的量产交付全流程。
沐曦致力于为异构计算提供全栈GPU芯片及解决方案,可广泛应用于智算、智慧城市、云计算、自动驾驶、数字孪生、元宇宙等前沿领域,为数字经济发展提供强大的算力支撑。
6.2、团队构成:
陈维良:创始人、董事长 & CEO,清华大学微电子学研究所硕士,曾任 AMD 全球 GPGPU 设计总负责人。
杨建:联合创始人、CTO 兼首席软件架构师,浙江大学博士,曾是 AMD 大中华区第一位科学家(Fellow)。
彭莉:联合创始人、CTO 兼首席硬件架构师,上海交通大学电子工程系硕士,AMD 全球首位华人女科学家。
周昆:图形计算首席科学家,浙江大学计算机辅助设计与图形学国家重点实验室主任。
6.3、发展历程与成果
2020 年:陈维良与彭莉和杨建共同在上海自贸区临港新片区创立了沐曦。
2021 年:高性能通用 GPU 芯片设计公司沐曦集成电路(上海)有限公司宣布完成由光速中国和经纬中国联合领投的 PreA + 轮融资。同年,沐曦科技(北京)有限公司、沐曦科技(成都)有限公司成立。
2022 年:1 月,沐曦首款采用先进制程的异构 GPU 推理芯片 “曦思 N100” 正式流片。8 月,曦思 N100 回片并完成测试。
2023 年:“曦云 C500” 于 6 月完成点亮及回片,并在 2023 世界计算大会上获评 “世界计算大会专题展优秀成果”;10 月,美国升级 AI 芯片和半导体设备禁令,沐曦在代工方面受到一定影响。
2024 年:11 月 29 日,沐曦与加佳科技共同启动曦源一号 sada 万卡集群算力项目,其第一期千卡集群在上海正式落地。
6.4、主要产品
沐曦打造全栈GPU芯片产品,推出曦思®N系列GPU产品用于智算推理,曦云®C系列GPU产品用于通用计算,以及曦彩®G系列GPU产品用于图形渲染,满足“高能效”和“高通用性”的算力需求。
沐曦产品均采用完全自主研发的GPU IP,拥有完全自主知识产权的指令集和架构,配以兼容主流GPU生态的完整软件栈(MXMACA®),具备高能效和高通用性的天然优势,能够为客户构建软硬件一体的全面生态解决方案,是“双碳”背景下推动数字经济建设和产业数字化、智能化转型升级的算力基石。
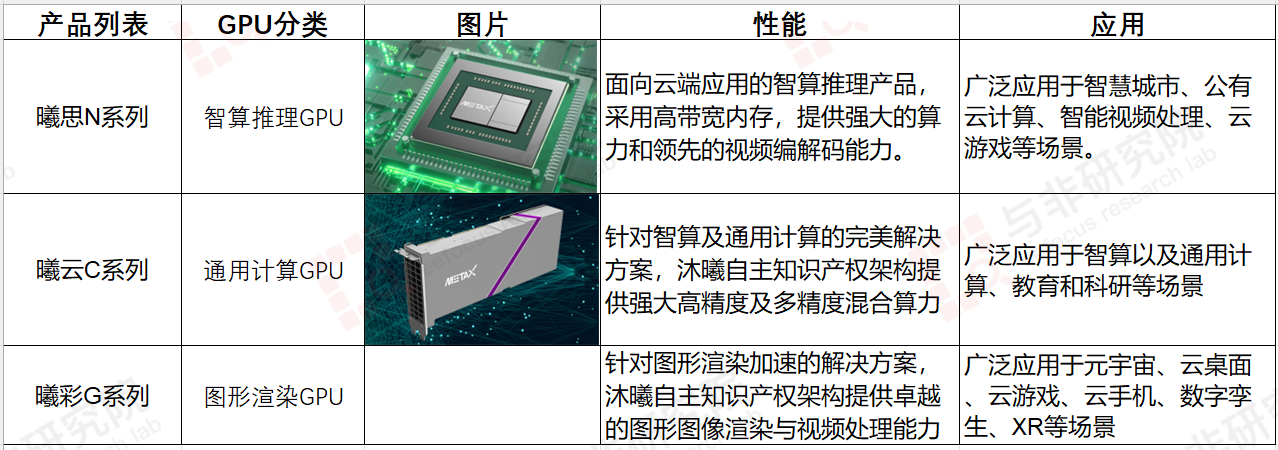
图|公司主要产品,来源:与非研究院整理
6.4、MXMACA运算平台
MXMACA是由沐曦推出的一种采用通用并行计算架构解决复杂计算问题的运算平台。它包含了自研指令集架构(ISA)以及GPU内部的并行计算引擎,集成了通用计算和机器学习框架,为科学家、研究员以及各个应用领域的行业专家们提供了高灵活性和高性能的开放式软件平台。
MXMACA异构计算平台支持多种开源技术,包括AI神经网络框架(TensorFlow/PyTorch等)、库(Blas/DNN等)和Linux Kernel支持等,通过不断地优化来实现更高的性能和可扩展性,帮助用户更好地用AI赋能社会。同时,MXMACA运算平台提供了丰富的系统和应用管理工具,方便用户能够更高效地进行灵活的开发、验证、环境部署及质量监控等。
7.算能
7.1基本信息
北京算能科技有限公司成立于2020年,专注于RISC-V、TPU处理器等算力产品的研发和推广应用。公司秉持全面开源开放的生态理念,引领智算技术创新,打造覆盖“云、边、端”全场景产品矩阵,在城市运营、智能制造、大模型应用、智能终端等多元场景得到了广泛应用和用户认可。
自2016年以来,旗下品牌算丰SOPHON系列产品已完成多次迭代,每代产品相较于前代产品均实现了能耗比倍数级提升。在RISC-V领域,算能备受关注,稳居行业领先地位。 公司在北京、上海、深圳、青岛等国内10多个城市及新加坡等国家设有研发中心,研发人员占比超过73%,其中硕博士占比超过78%。
在 AI 芯片领域有一定的技术积累和市场份额,专注于为人工智能应用提供高性能、低功耗的算力芯片,产品涵盖了云端、边缘端和终端等多个场景。
7.2、发展历程与成果
在云端计算方面,算能的芯片为数据中心的人工智能训练和推理任务提供了高效的算力支持;在边缘计算领域,其芯片能够在靠近数据源的地方进行实时的数据处理和分析;在终端设备上,算能的芯片也被应用于一些智能安防、智能家居等产品中。

图|公司发展历程,来源:公司官网
7.3、主要产品
7.3.1、处理器

图|公司处理器产品
来源:公司官网
7.3.2、服务器

图|公司服务器产品
来源:公司官网
7.3.3、模组卡&卡

图|公司模组卡产品
来源:公司官网
8、昆仑芯
8.1、基本信息
昆仑芯(北京)科技有限公司前身为百度智能芯片及架构部,于2021年4月完成独立融资,首轮估值约130亿元。公司团队在国内最早布局AI加速领域,深耕十余年,是一家在体系结构、芯片实现、软件系统和场景应用均有深厚积累的AI芯片企业。
8.2、发展历程与成果
2011年启动FPGA AI加速器;2015年FPGA部署超过5千片;2017年FPGA部署超过1.2万片(业内最多),在Hot Chips 2017发布昆仑芯XPU架构。2018年正式启动昆仑芯AI芯片产品研发;2020年昆仑芯1代系列产品大规模部署,昆仑芯2代系列产品量产,性能大幅提升;2022年昆仑芯2代系列启动互联网及各行业客户交付。
独立分拆后,昆仑芯公司继续加大研发投入,推动芯片技术的不断创新和发展,其产品在百度的搜索引擎、自动驾驶等业务中得到了广泛应用,同时也开始向其他企业提供算力服务。
8.3、主要产品

图|公司主要产品
来源:与非研究院整理
9、平头哥
9.1、基本信息
平头哥半导体有限公司于2018年9月宣布成立,是阿里巴巴集团的全资半导体芯片业务主体。平头哥拥有端云一体全栈产品系列,涵盖数据中心芯片、IoT芯片等,实现芯片端到端设计链路全覆盖。
9.2、发展历程与成果
2019 年发布首款 AI 芯片含光 800,在性能和能效比方面表现出色,为阿里云的人工智能业务提供了强大的算力支持。
9.3、主要产品

图|公司主要产品
来源:与非研究院整理
含光800是平头哥发布的首颗数据中心芯片。含光800是一颗高性能人工智能推理芯片,基于12nm工艺, 集成170亿晶体管,性能峰值算力达820 TOPS。 在业界标准的ResNet-50测试中,推理性能达到78563 IPS,能效比达500 IPS/W。
含光800采用平头哥自研架构,通过软硬件协同设计实现性能突破。平头哥自主研发的人工智能芯片软件开发包,让含光800芯片在开发深度学习应用时可以获得高吞吐量和低延迟的高性能体验。含光800已成功应用在数据中心、边缘服务器等场景
主要应用
目前平头哥含光800云服务器已在阿里云上线,通过阿里云自研神龙虚拟化计算平台,在云上使用弹性裸金属含光800加速实例,可以实现更广泛地部署,从而提高生产率。广泛适用于语音、图片、视频等AI推理业务,能够为客户提供超高性价比的推理解决方案。
含光800支持多种智能搜索算法,如CVR、CTR等,基于含光800强大的推理算力,可以显著提升电商搜索算法效率。目前含光800已经实现了规模化商业落地,在2020年的双十一天猫节期间成功支撑了淘宝搜索等业务,为阿里巴巴双十一保驾护航。
以阿里妈妈为例,每天有超过50亿的推广流量和3亿的商品推广展现。含光800支持搜索定向广告、广告排序等多种电商智能营销业务场景的计算需求,并能实现计算性价比大幅提升。目前含光800已成功落地阿里妈妈,为业务提供可靠高效的算力支持。
二、主要对比
因数据未公开,营收、利润情况,以及毛利率、净利率、研发投入也无法进行对比。不过一般来说,处于发展初期的 AI 芯片公司,由于研发投入大、规模效应尚未完全形成,毛利率和净利率可能较低。
2.1、上市进程情况
燧原科技:2024 年 8 月 23 日,燧原科技同中金公司签署上市辅导协议,正式启动 A 股 IPO 进程。
壁仞科技:2024 年 9 月 12 日,壁仞科技已在上海证监局办理辅导备案登记,拟首次公开发行股票并上市,辅导券商为国泰君安。
摩尔线程:2024年11月中旬,摩尔线程也启动了A股IPO辅导备案。由于其创始人兼CEO张建中曾担任英伟达高层多年,摩尔线程也被打上了“中国英伟达”的标签。 根据相关信息,摩尔线程目前估值255亿元,启动上市前已完成数轮累积数十亿元的融资。投资方包括中国移动、深创投、中银国际、建银国际、招商局创投、红杉资本等知名国资和风投机构。
天数智芯:截至目前,没有天数智芯关于上市准备的公开消息,其仍专注于产品研发和市场拓展等业务。
登临科技:目前没有公开信息表明登临科技启动了上市准备工作,公司主要精力可能放在智能安防、智能驾驶等领域的技术研发和产品推广上。
沐曦科技:据 2025 年 1 月 2 日消息,沐曦已在 2024 年底完成股份制改革,将择机启动后续资本市场规划,且已与中金、华泰等多家投行深度接触,拿到上市绿色通道。
算能:算能在 AI 芯片领域有一定市场份额,但目前没有关于其上市准备情况的公开报道,可能在专注于业务发展和技术创新以提升自身实力。
昆仑芯:截至 2025 年 1 月 7 日,没有确切的昆仑芯上市准备和进展的公开信息,其母公司百度在相关领域有一定影响力,未来昆仑芯的上市情况可能受多种因素影响。
平头哥:2023 年有传言称平头哥将从阿里巴巴集团 “剥离”,从属于阿里云智能集团旗下,而阿里云智能集团计划在未来 12 个月从阿里集团完全分拆并完成上市,但目前没有关于平头哥单独上市的明确消息。
2.2、研发人员对比
各公司都汇聚了一批优秀的研发人才。摩尔线程的创始人及核心技术人员来自英伟达等企业,拥有丰富的 GPU 研发经验;燧原科技、壁仞科技等也吸引了众多来自国内外知名企业和科研机构的专业人才;平头哥作为阿里旗下公司,能吸引到行业内的顶尖人才。
2.3、主要应用场景对比
燧原科技、壁仞科技、摩尔线程、天数智芯、沐曦科技:在人工智能训练和推理、云计算、大数据处理等领域有广泛应用,为数据中心提供算力支持,也可用于一些对计算性能要求高的科研、工业等场景。
登临科技:重点应用于智能安防领域的视频监控设备,以及智能驾驶领域的汽车自动驾驶系统。
算能:覆盖了云端计算、边缘计算和终端设备等多个场景,如数据中心的人工智能训练和推理、智能安防摄像头、智能家居设备等。
昆仑芯:应用于百度的搜索引擎、智能语音助手小度等业务,同时也在拓展其他人工智能应用场景。
平头哥:含光 800 主要用于人工智能推理,在阿里巴巴的电商、云计算等业务中发挥作用,其 RISC-V 芯片可应用于物联网、自动驾驶等领域。
三、总结
目前,国内的GPU公司大多处于发展初期阶段,尚未实现大规模盈利。燧原科技、壁仞科技、摩尔线程等企业在获得多轮融资后,有资金投入研发和市场拓展。昆仑芯依托百度的业务,平头哥作为阿里巴巴旗下公司,其芯片业务的营收和利润将受益于互联网大厂。
从各公司创始人员的过往历程,以及各公司的产品布局结构等综合对比来看,摩尔线程、壁仞科技为最类似英伟达的企业,未来上市后有望成为新的GPU明日之星,也就是“中国英伟达”。燧原科技、沐曦科技创始人出自AMD,可能为最接近AMD的企业。算能有望成为博通这类专注ASIC类的企业。昆仑芯、平头哥脱胎于互联网大厂的公司,还无对标企业。登临科技则成为视频安防GPU新赛道领头羊。天数智芯GPGPU将成为智算中心国内龙头。







