


 2535
2535
2025年存储产业趋势
随着Deepseek等AI大模型应用的快速崛起,2025年的存储产业正在经历一场前所未有的变革。以深度学习为例,训练大型模型需要处理大量的原始数据,并将这些数据转化为可供模型学习的信息。这一过程不仅对计算能力提出了挑战,还要求存储系统提供高性能的数据存取和处理能力。
那么AI大模型对存储产业究竟带来哪些新的需求?存储技术在新需求的推动下又将出现哪些新的创新和突破?近日,在一年一度的闪存峰会(CFMS 2025)上,与非网记者接触采访到了国内、国外多家存储厂商代表,从晶圆厂、模组厂、到主控芯片厂商,让我们来看看这些存储厂商们如何看待AI产业带来的影响吧!
“我们必须要承认AI让存储变得更为的基础、更为的关键。”——CFM闪存市场总经理邰炜

存储产业市场趋势,来源:与非研究院整理
CFM闪存市场总经理邰炜表示AI已经对存储市场格局产生了明显的变化,其中高带宽内存(HBM)和高性能固态硬盘(SSD)将成为支撑AI计算的核心技术,而低延迟、大容量和高效能的存储将直接影响AI工作负载的处理速度和精度。
2025年存储产业呈现出显著的变化,主要体现在DRAM、NAND Flash、以及应用端的多元化需求上:
首先,DRAM产业面临结构性变化,HBM(高带宽内存)在DRAM市场的占比已接近30%,并在应用上持续增长,特别是在服务器领域,已经超过手机内存消耗。HBM在高性能计算(如AI)中广泛应用,预计随着英伟达GPU架构的升级,HBM将在2024年迎来爆发性增长,并推动从HBM3到HBM3e的过渡,最终在2026年进入HBM4阶段。
三星半导体软件开发团队执行副总裁吴文旭表示,HBM4的出现标志着存储行业在速度和定制化方面的进一步突破。与HBM3相比,HBM4引入了更多的可定制选项,允许客户将专业IP与HBM相融合,以满足特定应用需求。客户对于定制化HBM的需求越来越高,尤其是在AI领域,创新成为了行业发展的关键驱动力。他认为,DDR5内存正迎来更高容量的需求,客户需求已从传统的128GB扩展到256GB甚至更大容量。三星电子已投入大量资源,以提供市场上更大容量的DRAM产品。此外,MRDIMM(Multi-Rank DRAM)技术也在不断发展,从最初的实验性产品逐渐成为应对AI基础设施需求的关键技术。
吴文旭也认同,随着AI计算需求的增加,SSD的容量和性能不断提升,未来可能会达到128TB甚至更高。此外,针对AI技术的专用SSD已经开始出现,满足AI工作负载的特定要求,成为高性能计算系统的重要组成部分。存储容量的不断扩展是响应AI技术发展的重要趋势。从最初的15TB SSD到未来可能达到128TB甚至256TB的超大容量产品,存储产业正在不断满足AI计算、数据分析和训练等应用的需求。
在NAND Flash市场,QLC(四级单元)存储的需求迅速增长,2024年出现了供不应求的情况,预计QLC占市场的20%,并且企业级SSD的容量将大幅增长,像32TB、64TB、128TB等大容量SSD将迎来量产。QLC的市场渗透不仅限于服务器和PC,今年预计在手机中也将突破,512GB至1TB的QLC UFS预计将成为主流。2024年,NAND Flash市场规模达到700亿美元,尽管价格回归理性,但容量增长将持续,推动整个市场稳定发展。
随着服务器市场成为存储产业的核心驱动力,内存和存储需求快速增长。2024年,服务器内存容量增长了107%,并且AI服务器占比预计达到14%。2025年,服务器将进一步增长,预计达到1330万台,并且主流服务器平台全面支持DDR5和PCIe5.0技术,带来更高的计算性能和训练效率,特别是在AI应用中。特别值得注意的是,PCIe5.0的应用将加速,预计在2025年将有30%的厂商支持PCIe5.0。
从应用市场来看,手机市场在存储需求上有所平稳,但AI的发展为其带来了新的增长动力。预计2025年,AI手机将占到30%的市场份额,进一步推动LPDDR5X和未来LPDDR6的应用。随着AI技术的不断进步,手机存储需求不仅体现在更大的内存容量,还包括更高的性能要求。随着智能手机中集成了越来越多的大语言模型,UFS4.1能够为AI应用提供高速的数据传输,推动手机AI功能的发展。此技术支持更大的AI模型和处理能力,满足用户日常工作中的影像编辑、生成等多种需求。PC市场也正在快速迎接AI的到来,预计2025年AI PC将迎来质的飞跃,LPDDR5X和DDR5内存将成为主流,PCIE5技术将在PC中得到广泛应用,进一步提升计算能力和性能。智能汽车作为下一个重要的存储市场,随着智能驾驶技术的发展,存储在智能汽车中的应用将成为核心战略资源,迎来新的发展阶段。

存储产业技术趋势,来源:与非研究院整理
邰炜表示,由于AI的崛起,计算平台逐步从传统的CPU转向GPU和NPU为核心的架构,这推动了对高性能内存和存储的需求。AI的需求使得内存技术不断创新,例如基于低功耗内存的LPCAMM和SOCAMM等新型产品应运而生。这些新形态的产品,特别是在数据中心领域,强调低功耗、密度优化和高效能,以满足AI计算平台的需求。
CXL技术的逐步发展,特别是CXL3.0的推出,将为内存池化提供强大的技术支持。内存池化是一种通过硬件和软件协同工作,将多个内存模块进行统一管理的方式,它可以极大地提升内存资源的共享和灵活性。CXL3.0的应用将推动内存池化进入实际应用阶段,通过增加内存带宽、减少延迟,并优化内存配置,支持更大规模的内存系统,满足高性能计算平台对内存的需求。三星XX认为,尽管CXL市场尚未成熟,但它正在成为未来计算架构中的关键技术。CXL允许将大型DRAM通过网络共享,使不同的GPU、CPU和计算系统能够共同访问高性能存储资源。随着CXL生态系统的建设,存储和计算资源将更加高效地协同工作。
AI驱动下的闪存需求?
“我们认为AI对闪存的需求主要分为这三点:高性能、大容量、低功耗。”——长江存储市场负责人范增绪
作为国产存储颗粒的代表,长江存储近年来通过创新技术架构,特别是其“Xtacking”(晶栈)技术,针对AI对闪存的新需求,提出了多项解决方案。
长江存储市场负责人范增绪对与非网记者介绍,长江存储自2018年推出Xtacking架构以来,一直致力于提升存储性能、密度与可靠性。Xtacking架构通过将存储阵列与外围逻辑电路分开设计并采用混合键合技术,这使得存储产品在提高IO速度和存储密度的同时,也增强了产品的可靠性。这种架构的特点包括:
更高的IO速度:通过优化设计,Xtacking架构将NAND闪存的IO接口速度从800Mbps提升至3.6Gbps,大幅提高数据处理效率。
更高的存储密度:该架构使得每个存储芯片的容量得到了显著提升,从而更好地满足AI应用对大容量存储的需求。
更强的可靠性:Xtacking架构的设计提升了闪存的耐用性与稳定性,适应AI算法对数据存储的高要求。
长江存储的Xtacking4.0产品系列在多个方面做出了显著改进,以满足AI领域的需求:
512GB TLC产品:该产品IO速度提升50%,达到了3.6GB/s,存储密度提升了48%,并且在2024年上半年已经量产,展示了长江存储在存储密度和数据吞吐量上的进展。
1TB TLC产品:IO速度同样提升至3.6GB/s,存储密度比上一代提升了36%,并且该产品已经在2024年下半年规模上市。
2TB QLC产品:通过提升存储密度和并行度,Xtacking4.0的QLC产品的吞吐量比上一代提升了147%。此外,这款产品的寿命也比上一代提升了33%,进一步增强了闪存的耐用性,特别是在AI推理和数据处理等高强度应用场景中的表现。
长江存储不仅推出了创新的Xtacking产品,还根据不同应用场景提供了全系列的存储解决方案,满足云计算、AI、大数据等多领域需求:
嵌入式产品线:如UFS4.1、UFS3.1和UFS2.2等嵌入式存储产品,针对AI手机和物联网终端的需求,这些产品提供了高带宽、低功耗、优异的读写性能,适用于旗舰级AI手机等终端设备。
消费级产品线:包括PC550、PC450等PCIe 4.0和PCIe 5.0产品,支持AI PC的高效运算与长时间续航,满足高性能计算需求。
企业级产品线:长江存储的企业级SSD产品,如PE511,基于Xtacking4.0架构,提升了产品的耐用性和容量,适用于数据中心、AI推理和大数据存储等应用。企业级SSD相比传统机械硬盘,具备更低的延迟、更高的性能与更大的存储密度,能够显著提升数据处理效率,并降低数据中心的能耗和运维成本。
“在AI存储中选择SSD模块请大家选择这款122TB SSD”——铠侠电子中国有限公司的董事长兼总裁岡本成之
铠侠公司通过BiCS闪存技术的持续发展,迎合了AI对存储速度和容量的严格要求。BiCS系列闪存采用了CBA晶圆绑定架构,这种架构实现了存储单元的高密度整合,为高性能SSD提供了有力的支持。铠侠的BiCS10、BiCS9和BiCS8等技术不断提升闪存的性能和密度,以满足云计算和AI应用的需求。
铠侠电子中国有限公司的董事长兼总裁岡本成之表示,铠侠的BiCS10技术标志着SSD存储在速度、密度、功耗效率等方面的重大突破。这款产品不仅支持PCIe 6.0接口,还具备更高的切换速度和更低的功耗,预计在2025年投入市场。此外,BiCS9和BiCS8等产品也紧随其后,持续改进性能,尤其在写入性能、读取性能和功率效率方面表现卓越。尤其是BiCS8,通过改进后的电源效率,使得其顺序写入性能提高了50%,为用户提供了更为高效的存储解决方案。AI应用需要处理大量数据,这使得大容量、低成本的存储成为关键。铠侠的QLC(四级单元)闪存技术在这一需求中表现出色。尽管QLC闪存的性能相较于SLC和TLC略逊一筹,但随着内存技术的进步,QLC的性能在2025年已经显著提升,能够满足AI存储需求。特别是在GPU服务器系统中,QLC SSD能够提供大容量的存储,支持AI训练和数据存取的高速需求。铠侠通过减少QLC闪存的DWPD(驱动写入次数)来提高成本效益。虽然QLC的耐久性较低,但对于大多数企业应用,尤其是在AI领域,0.3DWPD的QLC SSD足以应对需求,同时降低了成本。这一举措使得QLC SSD能够在不牺牲过多性能的情况下,提供更具竞争力的价格。
铠侠还推出了容量达到122TB的QLC SSD,这在AI存储中具有重要意义。大容量SSD能够满足AI应用中对存储的庞大需求,同时通过高密度存储单元减少物理空间的占用。这一创新为云计算和AI应用提供了高性能、大容量的解决方案,进一步推动了数据中心基础设施的升级。“在AI存储中选择SSD模块请大家选择这款122TB SSD”,岡本成之表示。
此外,铠侠还通过BiCS闪存的进化,适应了从PCIe 5.0到PCIe 7.0的快速发展。PCIe接口的演变加速了SSD的速度,使得数据传输更加高效,符合AI服务器对于存储性能的要求。铠侠的BiCS10和BiCS8 SSD可以支持这些最新的接口技术,从而确保客户在未来几年的技术迭代中依旧能够获得优异的性能。
“ARM的AI加速器,可以支持每秒2048,并且支持原生加速,可以助力存储控制器本身变得更智能。”——Arm物联网事业部业务拓展副总裁马健
在AI时代,Arm的战略不仅集中在计算领域,还延伸到了存储领域。事实上,随着后摩尔时代来临,通过工艺提升算力性能的难度越来越高,除此之外只有两条路:一条是通过Chiplets架构来降低芯片成本,提升性能和能效,另一条就是打破存储墙,提升存储效率。
而ARM恰好在这两方面都有所布局。Arm物联网事业部业务拓展副总裁马健表示,Arm的Neoverse平台支持Chiplets架构,可以有效降低成本并提高AI计算性能。例如,AI模型可以通过高效的内存互联技术,实现CPU和AI加速器之间的数据共享,极大地提升了AI计算任务的吞吐率。此外,。Arm的处理器,如Cortex-R系列和M系列处理器,在实时处理、嵌入式存储和数据中心应用中发挥着重要作用。特别是在闪存控制器中,Arm的处理器能够提供低延时、高吞吐量的支持,帮助实现高效的数据存储和管理。
Arm还通过与存储企业合作,推动AI本地化部署和边缘计算场景中的存储创新。例如,Solidigm基于Arm Cortex-R CPU的SSD产品,在数据中心中提供了更高效的存储解决方案,而SiLiconmotion则通过Arm Cortex-R8处理器在AI PC和手机中的闪存应用,进一步提升了存储的性能和能效。
在云基础设施中,AI模型的训练和推理大多发生在集中式数据中心,Arm通过其计算平台支持这一过程。Arm的CPU采用先进的内存技术,减少数据延时,同时通过CPU和GPU的NV Link互连,提高数据吞吐率,优化AI训练和推理过程的效率。在边缘计算领域,Arm则通过其Cortex处理器系列为AI提供强大的计算能力,特别是Cortex-A320和Ethos-U85组合,能够支持大规模AI模型的运行,尤其适用于物联网和消费电子设备,促进AI技术在边缘设备中的落地。
“AI对大容量、低成本存储产品的迫切需求,会推动QLC时代的加速来临”——联芸科技董事长方小玲
随着AI技术的持续进步,AI对存储的需求将继续加大,这对存储厂商提出了更高的技术挑战。联芸科技凭借强大的技术创新能力和对市场需求的敏锐洞察,已做好充分准备,迎接AI2.0时代带来的新机遇。
联芸科技董事长方小玲介绍,联芸科技采用统一的架构设计,从芯片到固件再到量产工具,确保了不同接口的存储主控芯片能够共享资源,提升开发效率。通过这种高度集成的开发平台,联芸科技可以快速响应市场需求,减少研发周期,同时确保产品的稳定性和可靠性。
随着AI对大容量、低成本存储产品的需求日益增加,联芸科技加速推动QLC(四级单元)技术的普及。通过自主研发的Agile NCC+QLC算法,联芸科技帮助客户快速实现QLC技术的量产,进一步降低存储产品的成本。QLC技术的广泛应用,标志着闪存行业迈入了一个新的时代,能够满足AI应用中对大容量存储的需求。
群联科技推出了MAP1802和MAP1806两款高性能PCle5.0 ESSD主控芯片。这些芯片支持高达16TB的大容量存储,能够满足AI应用中对大规模数据存储和高速数据处理的需求。MAP1802主控芯片特别适合低功耗应用,如AIPC,能够有效延长设备的续航时间;而MAP1806则提供了更强的存储性能,适用于对高速大容量有需求的AI场景,如大模型训练和数据处理。
AI终端设备对功耗有着极高的要求,尤其是在移动设备中,散热和电池续航是设计的关键。群联科技通过改进主控芯片架构和采用更先进的制造工艺,不断提升能效。例如,群联的PCle5.0 SSD比上一代产品在单位性能功耗方面下降了30%左右,显著提高了能效。此外,群联还开发了智能温控算法,能够根据SSD的实际工作状态自动调整功耗,避免过热问题,提高设备的稳定性和可靠性。
如何应对AI算力提升对存储的挑战?
“两大对AI数据方面的挑战:一是应对大模型纯算一体化创新与近场数据加速处理技术;二是大量多模态数据的管理与高效率检索技术。”——慧荣科技CAS(终端与车用存储)业务群资深副总裁段喜亭
“2024年年底的时候,提出了两大对AI数据方面的挑战:一是应对大模型纯算一体化创新与近场数据加速处理技术;二是大量多模态数据的管理与高效率检索技术。” 慧荣科技CAS(终端与车用存储)业务群资深副总裁段喜亭表示,作为主控厂商,慧荣通过聚焦五个要点来应对这两大挑战。这个五个要点分别是:1.高吞吐量、2.低延迟;3.低功耗;4.可扩展性;5.高可靠性。
要做到这五点,首先是加速主控技术的升级创新。慧荣在主控上的创新之一是自研的Serdes和分布式存储数据管理系统,这使得闪存主控能够更高效地管理和处理海量数据。尤其是在大规模AI训练和推理任务中,如何快速有效地将数据从存储装置传输到GPU等计算设备成为一大挑战。慧荣通过提升主控性能,支持高容量(如2TB QLC NAND)以及低功耗技术,确保数据在不同存储装置(如企业级SSD、客户端SSD、BGASSD等)间的高效流动。
其次,慧荣通过超越传统存储主控设计,着重提升数据管理和分类处理能力,使得数据可以根据需求合理分层存储。这种做法有效降低了存储系统的延迟,提升了数据的读写效率,特别是对于多模态数据的处理至关重要。通过这种方式,AI模型可以更快地读取所需数据,避免传统存储装置的瓶颈。
慧荣还提出了FDP技术,这项技术特别针对大容量SSD的预铺路优化。FDP可以在写入和延迟方面显著提高性能,例如它在WAF(写放大效应)上提升3倍,在写入操作上提升4.5倍,为大容量、高效存储提供了解决方案。
随着存储容量的增加,慧荣开始注重QLC(四级单元闪存)技术的优化,QLC闪存虽然在容量上有优势,但在性能和稳定性上面临挑战。慧荣通过其专利技术PerformasShape,对QLC闪存进行双重调校,使其在写入和读取操作上分别提升了93%和95%的稳定性,这对AI应用中对高稳定性、高一致性要求的数据传输至关重要。
随着闪存容量的增加,尤其是QLC闪存的普及,慧荣进一步加强了纠错技术。慧荣的NAND Xtend技术通过更大的解码空间(从4KB向16KB推进)和更智能的解码算法,显著提升了存储的可靠性。这项技术使得即使在高容量存储设备中,数据的完整性和准确性也能够得到保证,避免因数据损坏导致AI训练过程中的计算错误。
在AI应用中,尤其是GPU的高功耗特点下,慧荣还特别注重低功耗设计。通过先进的制程技术(如12纳米、6纳米,未来可能进一步推进到4纳米、3纳米),以及智能电压电流调整,慧荣的存储主控能够在高负载运行下仍保持极低的功耗。此外,多模态操作技术也使得系统能够根据不同应用场景动态调整功耗和速度,以实现节能和高效运行的平衡。
“慧荣为客户不只是提供一个主控而已,我们从上下游帮客户做一系列的串联,从GPU、CPU厂商的测试,一直到集成商跟全球的闪存原厂,甚至到全球的模组厂,我们帮各位搭建所有的生态,让各位可以很轻松的来使用SMI的主控。”段喜亭表示。
“国内很多领先的互联网和创新存储方案提供商已经在积极地研究大容量SSD来替换HDD”——Solidigm 亚太区销售副总裁倪锦峰
自2018年以来,Solidigm已累计出货超过100EB的QLC产品,成为AI大模型时代大容量SSD的核心提供者。尤其在2024年,Solidigm将其定义为QLC替代HDD的“元年”,国内外主要互联网与AI服务商均在加速部署基于QLC的新一代高密度存储系统。
Solidigm 亚太区销售副总裁倪锦峰表示,AI的发展推动了存储架构的演进,特别是在模型训练、推理、数据摄取、数据准备、checkpoint等典型AI工作负载中,对存储提出了“高性能 + 高容量 + 高可靠”的三重要求。尤其在训练阶段,高带宽、低延迟的随机读取能力成为关键,否则昂贵的GPU资源将因等待数据而空闲,造成资源浪费。与此同时,数据中心面临日益严峻的能耗与空间瓶颈。据预测,2024年美国数据中心用电将占全国4%,2030年将翻倍至8%。随着百兆瓦甚至千兆瓦级AI数据中心的兴起,如何节省电力、提升效率、压缩空间,成为行业共同关注的问题。
针对上述挑战,Solidigm主推基于QLC闪存的大容量SSD,全面替代传统HDD方案。
倪锦峰介绍,以Solidigm P5336为代表的新一代QLC SSD具备多项优势:
单盘容量高达122TB,为业界之最,是AI与数据密集型工作负载的理想选择。
相较混合架构(TLC SSD + HDD),在相同算力基础上可节省70%以上机架空间、降低77%以上功耗。
拥有5年无限随机写入耐久度,突破了QLC在企业级应用中的可靠性门槛。
此外,Solidigm不断优化产品架构、生产流程与测试验证,确保超大容量SSD的长期稳定性与质量控制。
满足AI全流程多样化存储需求。
此外,Solidigm还构建了覆盖不同AI阶段的全线SSD产品组合:
PS1010/1030(Gen5 TLC SSD):面向训练、数据准备、推理等高IOPS场景,提供领先的性能与能效比,特别在数据准备与checkpoint等关键阶段,展现出明显优势。
P5520/5620(Gen4 PCIe TLC SSD):出货量大,广泛部署于互联网公司,为AI基础数据处理提供坚实基础。
P5336/5430(QLC SSD):针对大容量需求,在数据摄取、存档、预处理等阶段提供高密度、高读性能支持,助力建设高效数据湖。
P5810(SLC SSD):超高性能,适用于对延迟极度敏感的场景。
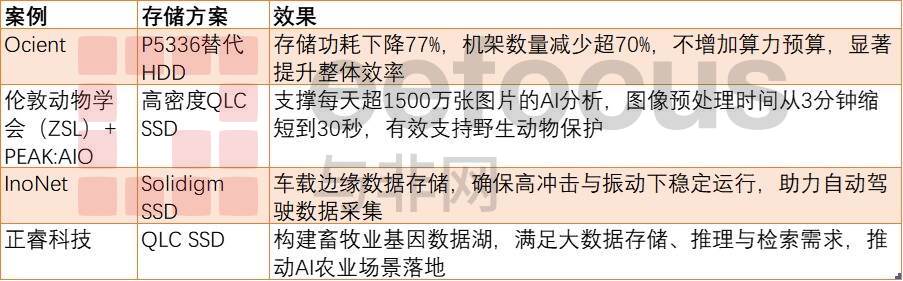
多个真实案例展示了Solidigm存储方案的AI适配优势,来源:与非研究院
“FLASH的产业在何方,在AI那一方,主控现在可能在西方,但是好好投资后,主控会回到我们这一方”——群联电子执行长潘健成
除了技术上的挑战,目前支持AI训练和推理的服务器成本过高依然是一个问题。群联电子执行长潘健成表示,群联电子通过推陈出新的产品来降低AI计算的成本。例如,群联推出了一款基于其闪存技术的AI训练与推理一体机,该产品大大降低了AI应用的入门门槛,使得一台PC就能支撑高效的AI计算工作。群联的目标是让更多企业和个人能够以更低的成本部署AI服务器,进行本地微调与服务推理,无需依赖昂贵的云服务。对于一般用户来说,购买一台性能强劲的AI训练机器的成本仅需20多万元人民币,而更高配置的8卡机则大约需要100万元人民币。通过这种方式,群联不仅降低了AI应用的硬件成本,还使得普通企业和个人都能轻松搭建自己的AI系统。
在国内,群联与合作伙伴如铨兴、浪潮和Deepseek等共同推动AI硬件解决方案的量产,推出了适用于AI训练的高性能一体机。在AI技术尚未广泛普及的背景下,群联通过降低AI硬件的成本,使得更多的教育机构能够为学生提供学习AI的机会。例如,群联推出的AITPC产品价格仅为2.5万元人民币,大大降低了学校部署AI计算机设备的成本。
在提高效率方面,群联还利用AI技术优化了自身的生产与设计流程。例如,群联通过自主开发的Phison Code Pilot平台,利用AI对海量数据进行智能分析与优化,提升了编程效率。群联的AI解决方案还大大降低了传统IT设计和技术文档编写的费用。例如,群联通过使用AI工具进行代码文档编写,可以将原本需要200万美元的设备费用压缩至仅需6万美元,节省了大量的研发成本。群联估算,仅在技术文档和设计开发中,AI就帮助他们每年节省了1000万美元的费用,并且在生产效率方面,AI的引入使得团队能以更少的人员完成更多的工作量,进而提高了整体的业务运作效率。最后,潘健成还呼吁更多的行业合作伙伴,包括软件公司、系统集成商、硬件公司和经销商,携手推动地端AI的广泛应用。
“如何把存储容量提上来,去满足它的需求,同时又做到成本的平衡,是未来主机厂跟汽车合作的一个非常关键的面临挑战的点”——小鹏汽车嵌入式平台高级总监&整车电子电气首席架构师段志飞
除了服务器、AIPC、AI手机等终端,汽车存储也成为AI驱动的重要应用领域。智能座舱不仅要求具备丰富的交互界面,还需要支持大量的应用功能,如第三方应用、地图导航、智能语音等。所有这些功能的实时性要求决定了运行内存(DRAM)的需求迅速增长。而智能驾驶则从传统的基于规则的系统转变为基于大模型的系统,这也对车端的硬件提出了更高的内存要求。
过去的智能汽车采用的是分布式的小算力、低存储的硬件架构,而现在,随着中央超算、大算力、高性能和大存储的硬件平台的引入,智能汽车逐步转型。这种转变不仅体现在硬件层面,软件架构同样经历了从分布式小模块的传统OS到以AI为核心的整车级操作系统(OS)的演进。
小鹏汽车嵌入式平台高级总监&整车电子电气首席架构师段志飞对与非网记者表示,小鹏汽车率先在汽车行业提出AI概念,并通过自研的AI芯片、底层架构和应用软件,打造具有差异化竞争力的智能汽车产品。小鹏汽车在座舱AI操作系统(AIOS)和智能驾驶系统中,均部署了大量的存储和计算资源。AIOS不仅支持炫目的交互功能,还通过多模态交互提升了用户体验。在这一过程中,座舱需要配备高性能的存储系统,以保证大屏显示、地图导航和语音识别等多个功能的流畅运行。小鹏汽车目前在座舱中采用了高达24GB至90GB的DRAM,并配备了128GB至256GB的存储内存,以满足实时性和大容量的存储需求。
在AI智能汽车的应用中,存储技术面临着以下几个挑战:
大容量:由于AI系统需要处理大量的数据,特别是在智能驾驶中,高容量的存储系统是必不可少的。
高性能:智能汽车要求存储系统具有极高的读写速率,以支持高速数据处理和实时响应。
可靠性与安全性:汽车是一个复杂的系统,对存储系统的可靠性和安全性要求极高。尤其是在自动驾驶的场景中,存储系统必须具备容错能力,以应对可能的硬件故障和数据丢失。
段志飞表示,小鹏汽车在解决这些挑战时,采取了多个技术措施。首先,采用高性能的DRAM和NAND闪存,以保证系统的高效运行。其次,在智能驾驶领域,通过不断的OTA(空中升级)更新,不断优化存储和计算架构,提升系统的稳定性和安全性。此外,随着技术的不断发展,小鹏汽车还计划引入更多先进的存储技术,如量子存储、非易失性内存等,以满足未来更加复杂和高效的存储需求。
最后,段志飞从客户的角度,强调了车载存储的可靠性和安全性问题,因为在售后中,存储问题在各类物料问题中占比为TOP1或TOP2,这是非常严峻的问题。加上车规存储的成本非常昂贵,占据超算平台的30%,因此一旦出问题就非常麻烦。
“AI时代需要一个六边形战士,要存力,在所有的领域都全面发展,这不是一个很容易做到的事情。”——平头哥半导体产品总监周冠锋
在2023云栖大会上,阿里巴巴平头哥发布旗下首颗SSD主控芯片镇岳510,基于这一颗SSD芯片,平头哥开始深入存储应用的各行各业,共同推动存储技术的进步。
平头哥半导体产品总监周冠锋表示,到AI和大模型的发展对存储提出了更高的要求,特别是在文件系统、数据存取速度和训练时间等方面。例如,Deepseek通过优化萤火虫文件系统,显著提升了SSD的带宽利用率和训练效率,这表明强大的存储能力对AI的高效运行至关重要。AI的训练过程不仅需要强大的计算力,还需要存储系统支持大容量、低时延、高带宽和高能效等多项特性。
周冠锋进一步分析了AI工作流中的各个环节对存储的不同要求。数据采集阶段需要低成本和大容量的存储;数据清洗阶段要求高带宽的存储来处理大量无效数据;在模型训练阶段,存储需要具备高可靠性、高带宽和能效,以应对反复的模型迭代和数据备份恢复;在部署和推理阶段,低时延和高效的存储系统是确保推理速度的关键。
周冠锋认为,镇岳510芯片作为AI时代的“六边形战士”,它在低时延、高能效、高带宽、可靠性、低成本等方面具备领先优势。例如,镇岳510芯片能够提供420K每瓦特的处理能力,带宽超过3400K lps,并通过创新算法实现了业界最高的可靠性指标。此外,它还能支持TLC、QLC等多种存储技术,具备大于32TB的存储容量。在芯片架构上,平头哥采用了软硬件深度融合架构,灵活结合硬件化任务和软件处理任务,实现高效的任务处理和灵活性。同时,对于低时延的处理,平头哥通过硬件化的LO执行路径提升了性能,确保了芯片可以实现4个1秒的低时延。
此外,平头哥还在算法方面进行了创新,特别是在数据纠错算法(LDPC)和电压优化算法上。LDPC算法是当前存储行业最先进的数据纠错技术,平头哥通过优化算法矩阵结构和消除环状结构,显著提升了纠错能力,并降低了错误率。通过最优电压搜索算法,平头哥还能够优化功耗、时延和质量控制(QOS)。
值得一提的是,目前平头哥已经与阿里云等大客户开展了广泛的合作。在阿里云的分布式存储平台上,镇岳510芯片大幅提升了带宽和LPS,减少了长尾延时,使得云服务能够在不增加硬件投入的情况下,提升性能和用户体验。此外,平头哥还与忆恒创源、DERA和BIWIN等存储厂商合作,推动了新一代SSD产品的开发,进一步提升了存储技术的市场竞争力。
周冠锋最后强调,存储产业在过去依赖数据爆炸带来的需求,但如今AI大潮为存储产业带来了更为强劲的增长动力。AI推动了存储行业的再度腾飞,平头哥作为芯片供应商,凭借在芯片架构和算法上的技术优势,致力于与行业合作,共同构建更强大的存储基础设施,为各行各业赋能。
总结:从“算力”到“存力”,存力决定AI创新上限?
根据IDC的数据,2023年全球数据产量达129.3 ZB,预计2028年增至384.6 ZB,不可否认其中存在大量的数据垃圾,这里生成式AI功不可没。在本次采访交流中,与非网记者频繁听到的一个词就是“存力”。事实上,在传统架构中,算力与存力是分离的,数据在计算单元与存储设备间频繁搬运,导致“存储墙”问题。AI的高并发数据处理需求迫使技术向存算一体演进,通过减少数据移动提升整体效率。
我们可以认为AI发展的上半场,主要还是堆算力(如GPU、AI加速器),算力成为模型训练和推理的关键。但是到了下半场,AI大模型需要海量数据支撑,例如单次训练可能涉及PB级数据集。而AI大模型的推理也会生成同等量级甚至更高的海量数据,这使得存储系统的高效性和扩展性成为瓶颈突破的关键。
另外,单纯的遵循摩尔定律提升芯片制程面临物理极限,且算力利用率受存储性能制约。例如,AI服务器中30%-50%的能耗来自数据搬运。这也是为什么NVDAH200的发布揭示了算力下一步提升路径,H200证明HBM比台积电更重要;英伟达证明了就算不添加更多CUDA核或超频,只增加更多的HBM和更快的IO,即便保持现有Hopper架构不便,依然可以实现相当于架构代际升级的性能提升。
最后,总结前面各位大佬的观点,笔者认为:算力与存力从“单一主导”转向“双轮驱动”,存力成为支撑AI规模化应用的基础设施。这一转变不仅是技术迭代的结果,更是数字经济从“计算优先”迈向“数据优先”的战略选择。未来,存力的发展将决定AI创新的上限,而算力则更多扮演效率优化的角色。两者的协同进化,将共同定义下一代数字经济的竞争格局。













 [课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
[课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
