


 1862
1862
越来越多的大模型、AI应用,以及庞大的服务器集群,给原有基础设施和底层技术带来了直接挑战。高速、大带宽的网络连接,支持数据快速传输的解决方案,成为AI下一步发展的关键支撑。
前不久的2024年光纤通信大会(OFC)上,英特尔展示了与其CPU封装在一起的集成OCI(光学计算互连)芯粒,该项技术虽然尚处于技术原型(prototype)阶段,但是对于在新兴AI基础设施中实现光学I/O(输入/输出)共封装已经实现了关键突破,是推动高带宽互连创新的关键一步。
该OCI芯粒可在最长100米的光纤上,单向支持64个32Gbps 通道,有助于实现可扩展的CPU和GPU集群连接,和包括一致性内存扩展及资源解聚的新型计算架构。虽然英特尔尚未公开这一OCI芯粒的确切尺寸,但最近发布的一张照片中,也可以直观感受到OCI芯粒与标准2号铅笔末端橡皮擦的尺寸对比。

据介绍,第一代OCI芯粒双向数据传输速度达4Tbps,功耗约为每比特5皮焦耳(pJ)。英特尔正致力于对器件和封装设计、制造工艺和带宽扩展的各种改进,以期在后续几代产品中将能效降低到每比特3.5皮焦耳以下。
传统电气I/O逼近极限,硅光互连展现优势

英特尔研究院副总裁、英特尔中国研究院院长宋继强在接受<与非网>等媒体采访时表示,AI大模型对计算密度和内存提出了很高要求,包括大容量和高带宽,此外,存算比显著提升,接近一比一,这进一步加剧了带宽挑战。下一步,随着AI应用普及,云、边缘计算及领域内模型的并发调用需求将激增,更需要业界加快探索新技术,提升算力和存储密度,同时降低功耗和体积,以适应有限空间内的高密度计算和存储需求。
一直以来,铜线实现芯片间的互连较为高效节能,但传输距离不超一米。长距离传输时它的短板明显,因为需要提高驱动电压以保持信号完整性,从而增加了功耗开支,这使它难以满足跨机架以及跨数据中心集群部署的长距离连接需求。
“硅光互连被认为是应对这一挑战的关键。在相对较长的距离内,采用光纤进行互连,能够大幅提高传输带宽速率;在I/O层面,可以通过包含片上激光器的PIC(硅光子集成电路)发射和接收光线,并实现光信号和数字信号的相互转换,这些集成电路可在现有的晶圆生产线上实现大规模量产,十分方便”,宋院长指出。
当硅光技术以其节能特性越来越受到重视的时候,英特尔融合了两大核心技术的独特优势也显现出来:首先,融合了半导体(特别是硅材料)发光和检测光的能力,实现了与现有基于硅的生产流程的集成;其次,支持大规模集成电路设计,包括硅与非硅晶体管的混合集成,进一步扩展了硅光技术的应用范围。

据介绍,这一完全集成的OCI芯粒的双向数据传输速度达4 Tbps,并兼容第五代PCIe。在2024年光纤通信大会现场,实时光学链路演示还展示了通过单模光纤(SMF)跳线(patch cord)在两个CPU平台之间实现的发射器(Tx)和接收器(Rx)互连。CPU生成并测量了比特误码率(BER)。英特尔还展示了发射器的光谱(optical spectrum),包括单一光纤上200GHz间隔的八个波长,以及32Gbps发射器眼图(eye diagram),表明了较强的信号质量。
满足AI需求,I/O“马车”升级“摩托骑士”
在数据中心和早期AI集群中,普遍使用可插拔光收发器模块来延长传输距离,但就AI工作负载的扩展需求而言,其成本和功耗不可持续。
因为要扩展AI或机器学习基础设施,就需要大幅提高I/O带宽密度和互连距离。可插拔收发器模块虽然可增加传输距离,但体积较大,通常需要高速串行器与解串器(SerDes)或数字信号处理技术(DSP)。因此功耗较高,带宽密度较低,延迟较高。
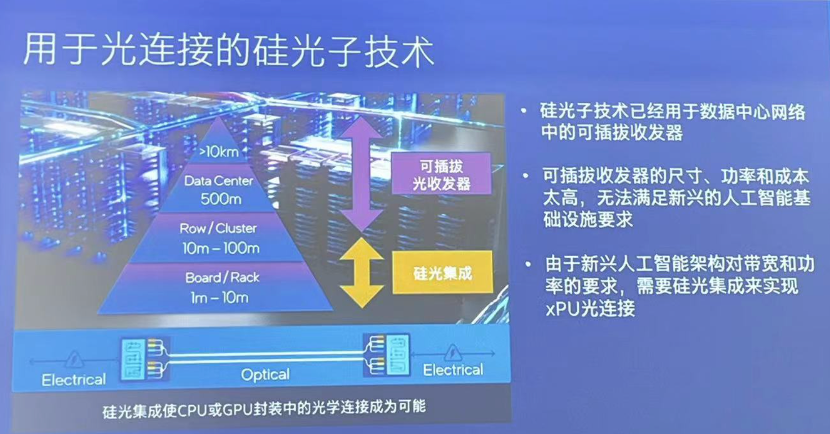
目前,可插拔光收发器模块的功耗大约为每比特15皮焦耳,而这种光电共封装解决方案的功耗仅为每比特5皮焦耳(pJ)。英特尔的OCI芯粒单向支持64个32Gbps 通道,传输距离达100米(由于传输延迟,实际应用中距离可能仅限几十米)。它采用8对光纤,每根8波长密集波分复用(DWDM)。下一步,OCI芯粒(或任何光学I/O解决方案)将实现与CPU、GPU或SoC共封,可以优化和改善I/O带宽密度、总能效比、延迟和成本。
对于OCI芯粒的实现方式,宋院长也有一个贴切的比喻,“传统电气I/O正在逼近物理极限,好比马车,传输速度和距离都很有限;光学I/O则像是摩托车甚至汽车,速度快且距离长。”
OCI芯粒是单一晶圆上硅光混合集成的创新之举
与普通芯粒相比,OCI芯粒的制造需要哪些特殊的半导体技术?现有的制造传统半导体芯片的工厂能否快速转产OCI芯粒?
宋院长解释说,OCI芯粒是一个完整的物理层光I/O器件,包括一个带有片上密集波分复用(DWDM)激光器和半导体光放大器(SOA)的硅光子集成电路(PIC),以及一个用于控制硅光子集成电路和连接主机的电子集成电路(EIC)。硅光子集成电路采用基于300毫米硅晶圆上运行的英特尔硅光子制造工艺,电子集成电路则采用标准CMOS工艺节点。
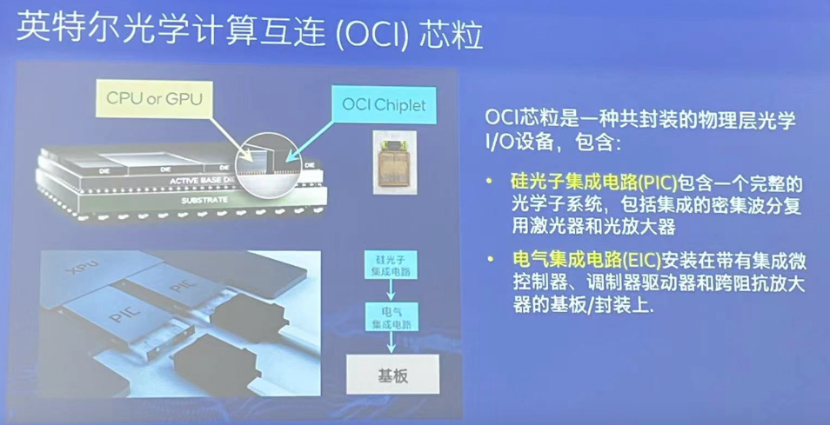
目前,英特尔已出货超过800万个硅光子集成电路,包含多达3200万个片上集成激光器,时基故障率(FIT)小于0.1(时基故障率是一种广泛使用的测量可靠性的方法,体现了故障率和发生故障的次数)。在可插拔光收发器模块中已经应用了这项技术,数百万个可插拔光收发器模块已于实际应用中部署,满足大型数据中心100/200/400 Gbps网络传输速率需求。
完全集成的OCI(光学计算互连)芯粒,标志着英特尔将半导体激光器与硅基光放大器混合集成于单一晶圆的创新,不仅缩减了体积、降低了功耗,还预示着规模化生产后,将进一步带来良率提升与成本降低的优势。
宋院长透露,英特尔还正在探索新的硅光子制造工艺节点,该节点具有先进的器件性能、更高的密度、更好的耦合性,并能大幅提高经济性。英特尔将继续在片上激光器和性能、成本(芯片面积减少 40% 以上)和功耗(减少 15% 以上)等方面取得进步。并且,英特尔也在与客户合作,开发共封OCI和客户SoC作为光学I/O的解决方案。
谈及OCI芯粒与英特尔CPU集成在技术层面的挑战,宋院长表示,将光学I/O芯粒集成到 CPU 或 GPU 封装中,可能会增加热量管理、封装设计和供电方面的需求。不过,英特尔在硅光子领域已深耕超过25年,是硅光集成的开拓者和领导者。依托这些技术经验,已经能够满足这些设计需求。
他补充,为了使光学I/O芯粒更加灵活,并减少集成过程中的工作量,通常会考虑在主机xPU与I/O之间使用电气接口,这些接口已通过健全的IP生态系统实现标准化,例如 UCIe、PCIe、以太网等。
OCI芯粒将聚焦三大指标持续迭代升级
今年以来,数据中心普遍进入“万卡”甚至“五万卡”级别。在算力集群的构建过程中,OCI芯粒可支持距离长达100米的传输,它可以通过提高岸线密度和扩展集群中CPU或GPU之间的连接范围来实现更高的带宽,还可以通过支持资源解聚的新架构(如HBM或CXL内存池化)来实现更高效的资源利用。面向传输速率需求达800 Gbps和1.6 Tbps的新兴应用,速度达200G/通道的硅光子集成电路正在开发中。
“我们相信,随着时间的推移和产量的提升(如新兴AI扩展所预期的那样),在系统层级,光学I/O的每比特总互连成本将可与电气I/O相比。此外,光学I/O性能更强,将有助于在系统层级提高性能”,宋院长表示,“英特尔目前正在开发第二代硅光子制造工艺节点,预计能将芯片面积减少40%以上,从而提高经济效益,并在功率耗散、光耦合效率、激光功率等方面实现多重性能提升。”
根据当前的路线图,英特尔将主要进行三方面指标的迭代,包括:提高线速率、每条光纤的波长数、光纤数量和偏振模式,从而扩展未来几代OCI芯粒的性能,打造出带宽达32Tb/s的器件。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1730755.html

 下载ECAD模型
下载ECAD模型

