


 2477
2477
作为半导体领域最受关注的芯片设计公司之一,Arm在2月初披露了2024财年第三季度财报,营收8.24亿美元,同比增长14%,高于分析师预期的7.6亿美元;调整后运营利润3.38亿美元,高于分析师预期的2.744亿美元。这份超出市场预期的财报直接推动Arm股价暴涨,一度超过40%,市值突破千亿美元。
对于下一季度的展望,Arm也给出了强劲数据,预计截至3月底的季度营收将在8.5亿美元至9亿美元,超过分析师预估的7.78亿美元均值。
“来到了公司历程中最令人振奋的时刻”
距离这份超预期的财报不到一个月,Arm近期更新了Neoverse 产品路线图,进一步推进基于Arm平台的人工智能基础设施。其中包括,通过性能效率更优异的 N 系列新 IP 扩展 Arm Neoverse 计算子系统 (CSS) 产品路线图。与 Neoverse CSS N2 相比,Neoverse CSS N3 的每瓦性能可提高 20%。此外,Arm 还首次将计算子系统引入性能优先的 V 系列产品线,新的 Neoverse CSS V3 基于全新的 Neoverse V3 IP 打造,与此前的 Neoverse CSS 产品相比,其单芯片性能可提高 50%。
“我们此刻来到了公司历程中最令人振奋的时刻”,Arm 高级副总裁兼基础设施事业部总经理 Mohamed Awad如此形容当下所处的情形,“2023 年,我们见证了加速转型,全球开始拥抱生成式人工智能 (GenAI)。2024 年及未来,预计将出现大规模的创新应用。随着AI渗透到教育、就业、制造、医疗和交通等领域,AI正在改变经济发展和日常生活,而Arm是这一切变革的基石。
他表示,从小型传感器到大型数据中心,创新和技术转型遍布科技领域。计算越来越专用化,通用CPU已不再能满足需求。特别是在基础设施领域,持续向更复杂的计算转型,它不再只关乎芯片、服务器或机架,而是关乎整个数据中心。
也就是说,系统级创新正在成为基础设施领域的新趋势。
NVIDIA 就是很好的例子,其Grace Hopper 从根本上重新设计了系统架构,从单个CPU管理多个 GPU,转变为CPU与GPU一对一的映射。而更多的 CPU 意味着内存一致性,这最终会大大提高 GPU 的利用率。通过将72颗Arm Neoverse核心与NVIDIA GPU进行组合,Grace Hopper的AI性能较基于x86架构的系统提升了10倍。
亚马逊云科技 (AWS) 和微软等行业巨头也采取了类似方法。他们正从头开始设计系统,并从定制系统级芯片 (SoC) 开始。AWS第四代基于Arm Neoverse平台的处理器Graviton4相比上一代产品,处理速度提高了30%,核心数量增加了50%,内存带宽增加了75%;微软首款专为计算中心打造的定制芯片Azure Cobalt 100 CPU也基于Arm Neoverse计算子系统(CSS)打造,该芯片具有128颗 Neoverse内核。
为什么这些巨头纷纷选择Arm Neoverse和Neoverse CSS?Mohamed Awad认为原因很简单,因为Arm独特的定位能赋予合作伙伴快速创建定制解决方案的能力,并充分利用到强大的生态系统,正是这些特性使 Arm Neoverse 夯实了全球 AI 愿景的根基。
他将Arm在基础设施领域收获累累硕果的原因归结为三点:首先是卓越性能,工程团队坚持不懈地实现迭代提升;其次是灵活性,赋能技术合作伙伴定制芯片,以支持其专用的工作负载和系统,而非采用一体适用的方案;最后是生态系统,Arm在软件、IP和芯片生态系统中提供出色性能和灵活性,从而降低配置的总成本并加速产品上市。
而Arm Neoverse 计算子系统 (CSS) 则充分演绎了这些优势,并在过去一年取得了显著进展。
据Mohamed Awad透露,一家合作伙伴使用Neoverse CSS节省了长达80人/年的工程师时间,另有一家合作伙伴,从项目启动到流片仅耗时九个月。而这背后的关键是——计算子系统是经过集成和验证的平台,汇集了构成 SoC 核心的各类重要部件。
为了帮助合作伙伴快速交付基于Neoverse CSS的定制SoC,Arm打造了全面设计 (Arm Total Design) 生态项目,核心目的是希望能够帮助合作伙伴快速交付基于Neoverse CSS的定制SoC,帮助降低合作伙伴的创新成本,并将其想要构建的定制数据中心计算系统更快推向市场。
据介绍,Arm 全面设计生态项目已吸引超过 20 家来自各方技术合作伙伴的加入,他们均致力于确保高性能、高效率解决方案的广泛可触及性,助力满足 AI 加速未来的计算需求。
Arm Neoverse 开启新篇章
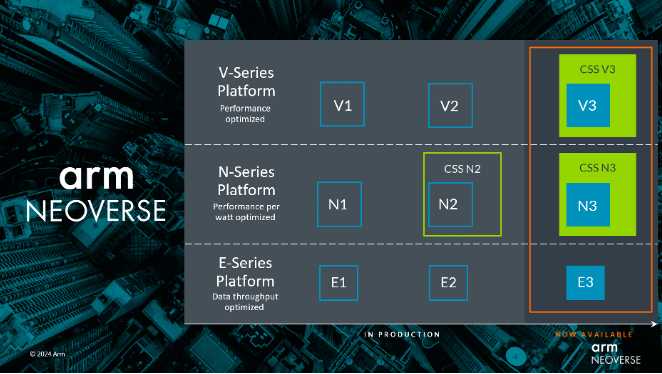
Arm Neoverse分为V/N/E三大平台:V系列旨在提供最佳性能,N系列强调每瓦性能优化,E系列则主要关注数据吞吐量优化。此次,Neoverse N 系列和 V 系列在推出新品的基础上,还推出新的 CSS 产品,即 Neoverse CSS V3 和 Neoverse CSS N3。Neoverse E 系列也不断迭代更新,采用了新的 CPU 和 新的 Neoverse S3 系统 IP。
据Arm基础设施事业部产品解决方案副总裁Dermot O’Driscoll介绍,CSS V3在单芯片上最多可扩展至128核,并支持最新的高速内存和I/O标准,CSS V3 基于新的 Neoverse V3 核心打造,是Arm目前单线程性能最高的Neoverse核心,专为Arm机密计算架构(CCA)提供硬件支持。
CSS N3则聚焦能效,与 CSS N2 相比,其每核心的每瓦性能提升 20%。“我们对 CSS N3 进行了调优,以填补我们发现的市场空缺,提供满足基础设施性能要求的高效计算”, Dermot O’Driscoll表示。
CSS N3 的首个实例可提供32核,热设计功耗(TDP)低至40W,可覆盖电信、网络和DPU等一系列应用。同时,考虑到横向扩展云配置需要,Arm为新的N系列产品引入了Armv9.2功能,能为每个核心提供2MB的专用L2缓存,并支持最新的PCIe、CXL I/O标准以及UCIe芯粒标准。
下图可以看出新CPU核心的性能提升,从视频处理到 SQL 数据库的性能均有所跃进。如今,人们常常忽视的一点是,有多少计算周期最终被用于压缩和协议转换等后台任务。N 系列在压缩方面取得了性能优势,可降低云服务运营商的成本,并最终降低云服务客户的成本。同样地,V 系列显著提高了协议缓冲区的性能,这是在数据中心内传输数据的一项关键功能。
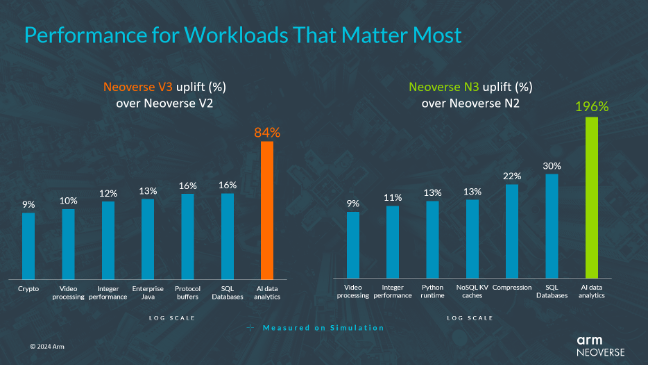
“CPU 推理将是生成式AI计算应用的关键组成,这些工作负载已从ML专用的Neoverse 功能(如Bfloat16、MatMul、SVE和SVE2),以及Arm微架构优化中受益,而且这一趋势还将继续”, Dermot O’Driscoll认为。
紧耦合芯粒方式有利于AI大模型应用
未来一个显而易见的事实是,并非所有 AI 处理都将在 CPU 上进行,因此打造 AI 加速器的公司迅速涌现出来。据最近统计,这一领域的公司已接近 80 家。
例如NVIDIA的Grace Hopper,就是使用了基于Neoverse V2 平台的紧耦合计算芯粒。Grace Hopper的一大关键创新就在于内存容量和共享内存模式,这种紧耦合的 CPU 加上加速器配置,对大参数 LLM 非常有益,对检索-增强-生成 (RAG) 等新兴方法也很有帮助。
当前,芯粒已成为管理良率的常用机制,企业也在努力复用芯粒,不过,尤其是面临不同团队的设计组合时,还是会在系统架构层面临挑战。例如:怎样在设计时对芯粒进行逻辑分区?如何设置直接内存访问 (DMA) 和中断、电源和安全等管理功能?要建立可互操作的生态系统,就需要在生态系统层面一致地解决这些问题。
Dermot O’Driscoll表示,Neoverse CSS 是专为帮助客户快速打造通用计算芯粒而推出的产品。它能提供所需接口,以便选择耦合自身的加速器。这种方法既可以在需要 CPU 时提供 CPU,又可以在需要 AI 加速器时提供 AI 加速器,做到两全其美。
近期,Arm发布了芯粒系统架构 (Chiplet System Architecture, CSA) ,目的是构建一个功能强大、支持通用的芯粒生态系统。Arm预计很多应用都需要将计算芯粒与AI加速器并行使用,而CSA 有助于简化这一联合设计的过程。Arm正与 20 多家合作伙伴,推动整个Arm生态系统释放芯粒技术的潜力。
生态伙伴共同加速基于 Neoverse CSS 系统开发
去年十月,Arm借由Arm全面设计生态项目,围绕 Arm计算子系统开展创新设计。该生态项目汇集了半导体领域领先企业,囊括了芯片设计合作伙伴、IP 供应商、EDA 工具提供商、代工厂和固件开发商等,共同加快并简化基于 Neoverse CSS 的系统开发。
如今,Arm全面设计已经有20多家成员加入。其中包括新的EDA和配套 IP 提供商,以及来自包括韩国、中国台湾、中国大陆和印度等战略市场的芯片设计合作伙伴,这些市场存在巨大的发展潜力。
据Arm基础设施事业部营销副总裁 Eddie Ramirez透露,Arm正在与三家主要代工厂合作,以确保CSS 产品能在其先进工艺节点上进行优化。

同时,Arm 全面设计合作伙伴正在努力将基于 Neoverse CSS 的设计推向市场。去年十月,Socionext 成为首家宣布计划在台积公司领先的2nm工艺上开发基于CSS芯粒的合作伙伴。智原科技也在构建基于芯粒的服务器芯片,该芯片将搭载64颗N系列核心,并基于英特尔代工服务的18A工艺节点进行生产制造。此外,ADTechnology将提供高性价比的16 核 CSS N 系列边缘服务器平台,他们将与三星代工厂合作,为边缘计算释放更强大的算力。
据了解,面向不断增长的AI计算需求,Arm Neoverse的创新方向主要聚焦于:第一,通过诸如 Bfloat16、MatMul、SVE 和 SVE2 等架构功能,以及微架构的优化,持续提升运行在 CPU 上的机器学习 (ML) 计算的表现。第二,通过支持最新的行业标准接口,以及提供用于一致性高带宽连接的 CHI 协议,为定制 AI 加速器与Arm Neoverse 平台和 Arm Neoverse CSS 的紧耦合提供更好的灵活性。第三,为自研定制 AI 加速器的合作伙伴提供行业领先的系统互连技术,以实现与主机计算的紧密耦合链接,并提供 CPU 来处理 AI 工作的编排,同时支持利用 Arm 基础设施软件生态系统的云原生软件。
“大型科技企业对基于 Arm Neoverse 平台的系统、软件和芯片等方面的投入,凸显了对AI时代的共同愿景。新一代 Arm Neoverse 将成为合作伙伴打造新一代产品和服务的基础”,Mohamed Awad表示。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1670437.html

 下载ECAD模型
下载ECAD模型


