


 2553
2553
自遵循IBM的要求,将X86架构和产品授权AMD以来,英特尔和AMD就成为了处理器领域当之无愧的巨头。尤其在PC时代,这两者几无竞争对手,他们也一直引领着芯片设计。
虽然错过了手机时代,但现在的服务器和AI时代,这两家半导体“老兵”有了广大的发挥之地。为了满足终端的需求,他们也在自己的芯片设计和制造上各出奇招。
继该领域的先驱 AMD 之后,英特尔在日前的Intel Innovation活动上也宣布推出基于 Chiplet 的产品 Meteor Lake。据介绍,Meteor Lake 的结构结合了 5 种类型的tile:当中包括了4 种类型的tile(CPU/IO/图形/SoC)以及位于所有这些tile之下的基本tile。从这颗芯片开始,我们正式见证了英特尔全面进入Chiplet时代。
AMD和Intel,也再次在同一个战场上相遇。
为什么需要Chiplet?
Chiplet 是小型模块化芯片,组合起来形成完整的片上系统 (SoC)。它们提高了性能、降低了功耗并提高了设计灵活性。概念已经存在了几十年,早在2007年5月,DARPA也启动异构异构系统的COSMOS项目Chiplet,其次是用于Chiplet模块化计算机的 CHIPS 项目。但最近,Chiplet在解决传统单片 IC 缩小尺寸的挑战方面受到关注。这是当前芯片制造产业发展瓶颈与终端对芯片性能需求之间矛盾所产生的妥协结果。
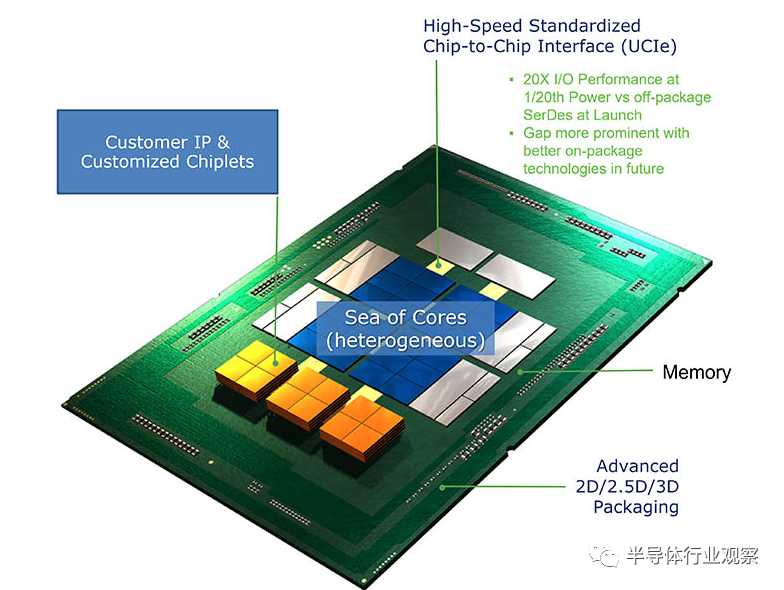
图2
据Yole表示,摩尔定律背后的创新引擎使得不断提高的设备集成度能够继续适应相同的物理尺寸。例如,如果光刻缩小可以使构建块缩小 30%,那么就可以在不增加芯片尺寸的情况下增加 42% 的电路。这大致是几十年来逻辑收缩的速度。
然而,虽然逻辑往往可以很好地扩展,但并非所有半导体器件都享有这一优势,例如可以包含模拟电路的 I/O,其扩展速度约为逻辑的一半,并且即使对于最领先的晶圆代工厂TSMC而言,SRAM 单元最近向 3nm 的过渡尺寸几乎没有,这就让人不得不寻找新的出路。此外,完整的 SOC 不仅需要逻辑门,还需要许多不同类型的器件电路,以及维持市场竞争力的最低水平创新。有见及此,设计师已经开始选择设计更大的整体die。然而,较大芯片的危险在于对良率的影响,因为随着芯片变得越来越大,它包含足够的关键缺陷而导致其功能失调的可能性就更高。
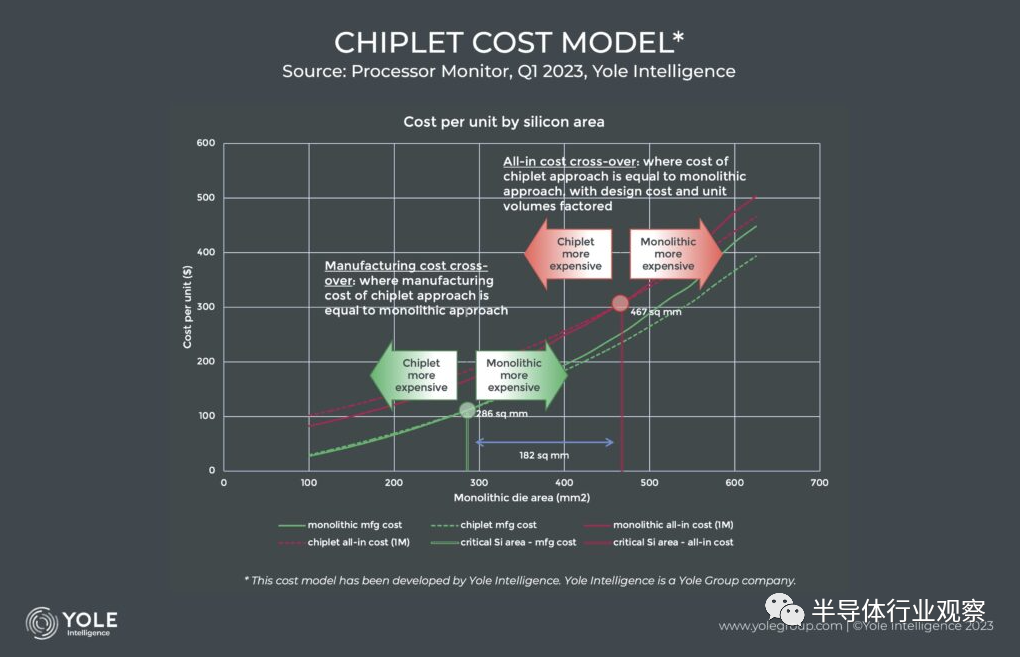
图3
而且,光刻缩小成本并不便宜。因为改变晶体管的形状和尺寸只能带来价格更高的设备和更长的处理时间。因此,采用 7nm 工艺加工的晶圆成本高于采用 14nm 工艺加工的晶圆成本,5nm 工艺的成本高于 7nm 工艺,依此类推……当我们在成本模型中检查这一趋势时,我们看到一个明显的趋势:随着晶圆价格的上涨,小芯片方法的经济性比单片方法更具吸引力。
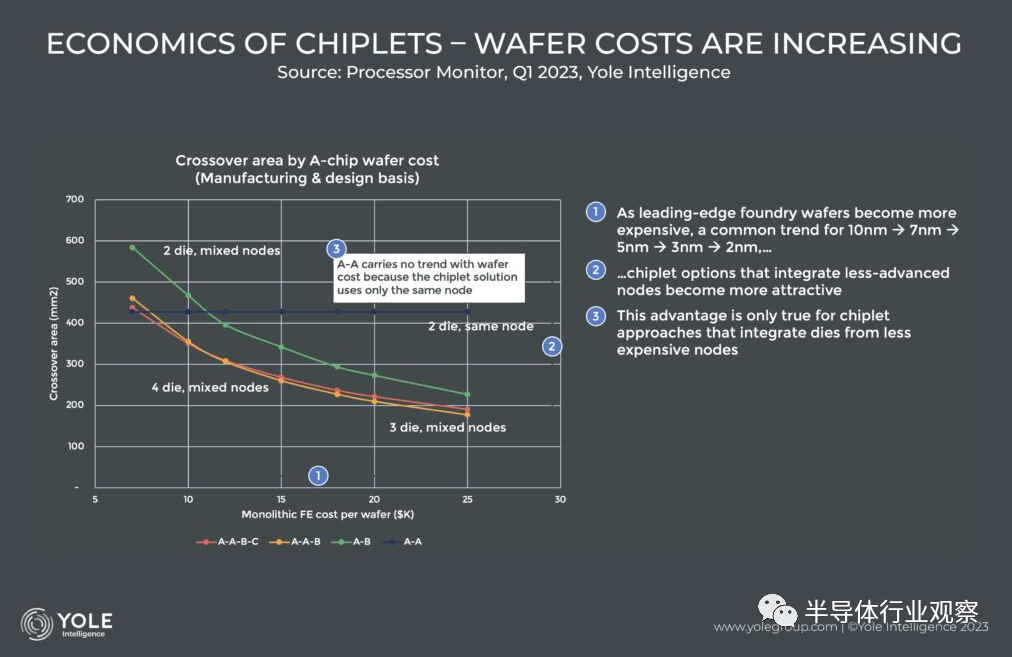
图4
据Yole所说,每个新芯片设计都需要设计和工程资源,并且由于新节点的复杂性不断增加,每个新工艺节点的新设计的典型成本也随之增加。这进一步激励人们创建可重复使用的设计。小芯片设计理念使这成为可能,因为只需改变小芯片的数量和组合即可实现新的产品配置,而不是启动新的单片设计。例如,通过将单个小芯片集成到 1、2、3 和 4 芯片配置中,可以从单个流片创建 4 种不同的处理器品种。如果完全通过整体方法完成,则需要 4 次单独的流片。
正因为如此,异构小芯片集成市场正在快速增长。据估计,小芯片的市场价值预计到 2025 年将达到 57 亿美元,到 2031 年将达到 472 亿美元。电子设计中对高性能计算、数据分析、模块化和定制的需求不断增长正在推动这一增长。

图5
总结而言,我们认为chiplet 具备以下四个优点:
1、通过将功能块划分为小芯片,我们可以防止芯片尺寸增加。这可以提高良率并简化设计/验证。
2、可以为每个小芯片选择最佳工艺。逻辑部分可以采用尖端工艺制造,大容量SRAM可以使用7nm左右的工艺制造,I/O和外围电路可以使用12nm或28nm左右的工艺制造,从而减少了设计和制造成本。制造成本。如果采用28nm左右的工艺,甚至可以嵌入闪存。
3、轻松制造衍生类型,例如相同逻辑但不同外围电路,或相同外围电路但不同逻辑。
4、让来自不同制造商的小芯片可以混合使用,而不仅仅是局限在单个制造商内。
然而,在英特尔和AMD最新发布的信息和产品看来,他们似乎对Chiplet有不一样的思考。
英特尔的选择
从名为“Ponte Vecchio”的芯片我们可以看到,英特尔充分利用了该小芯片的优势。而如图所示,Ponte Vecchio的整体tile面积比“Sapphire Rapids ”要小一点(Sapphire Rapids是400平方毫米x 4,也就是1,600平方毫米。Ponte Vecchi总共不到1,300平方毫米),但是有实际上是16个tile。它由一个计算tile、8个Rambo缓存tile、8个HBM2e I/Ftile和2个Xe-Linktile组成(还有很多HBM的基础tile和控制器,并且有8个HBM。但是,让我们将其从计数中排除)。

图5:左起Sapphire Rapids XCC/Sapphire Rapids HBM/Ponte Vecchio
基础tile相当大,不过只是简单的连接了走线,集成了HBM控制器等,而且工艺是Intel 7。计算块的尺寸小于 100 平方毫米,因为采用 TSMC N5。Rambo Cache 仍然是使用Intel 7,但是到了HBM2e SerDes 则用了TSMC N7。通过分离功能块,我们能够提高验证和良率,并且现在可以对每个块使用最佳工艺。
由于它同时使用EMIB和Foveros封装连接技术,因此它满足上面谈到的Chiplet优势中的1和2,尽管它偏离了UCIe指定的chiplet。除了完整的英特尔数据中心 GPU Max 1550 之外,该产品线还包括半尺寸的数据中心 GPU Max 1100,可满足 3和4所说的优势,但考虑到目前这还不是必要条件,Ponte Vecchio可以说是“正确利用chiplet思想的产品”。
问题在于 Xeon Max,或者更确切地说 Sapphire Rapids(图片5中排列在最左)
诚然,物理上它是一个由四个tile组成的chiplet,但每个tile具有包括CPU核心、内存控制器、PCIe/CXL、UPI和加速器在内的所有功能,并且tile尺寸为400平方毫米。另外,因为我们按照这种形状排列了四块tile,所以我们必须准备两种镜面对称的tile,所以这不符合上文谈到的1到3优势。
今年(2023年)3月举行的DCAI投资者网络研讨会上展示了后继产品Emerald Rapids的样品(图6),但这次不需要准备两种类型的tile,但tile的尺寸增加到几乎是光罩限制(芯片尺寸限制),并且优点1、2和3仍然完全被忽略。

图6:封装与Granite Rapids相同,因此tile尺寸约为25.2 x 30.9毫米,使其达到778.7平方毫米的巨大尺寸。
虽然这个Xeon Scalable物理上是一个chiplet,但它的设计原理与上面写的“chiplet的有点”不同。不过,他们看起来很自信。这主要有两点原因。
原因一:该小芯片具有内置内存控制器。这意味着出现的内存通道将根据小芯片的数量而变化。事实上,如果你看一下照片 2 右下角的图表,则可以发现有:
3 个小芯片:12 通道 DDR5
2 个小芯片:8 通道 DDR5
1个chiplet:如果保持原样,它将成为4通道DDR5,因此请准备另一个8通道的chiplet。
这就是它的意思。此外,如果有 4 个或更多小芯片,DDR 将是 16 通道或更多,从而无法保持与平台的兼容性。
原因二:Tile尺寸很大。根据Hot Chips披露的信息,Granite Rapids配备了4MB/核心的L3。这意味着每个核心的面积大小比 1.875MB/核心 Sapphire Rapids 大得多。
核心数量本身尚未正式公布,但根据目前流传的信息,似乎最多为 132 个核心,这意味着每块 44 个核心。包括DDR5内存控制器在内,共有46个块。
我认为 Granite Rapids 一代计算 Chiplet 的结构,据此估计,是这样的(图 1)。有48个12x4块,其中44个是CPU,2个是内存控制器(其余两个未知,但它们实际上可能是CPU的冗余块)。
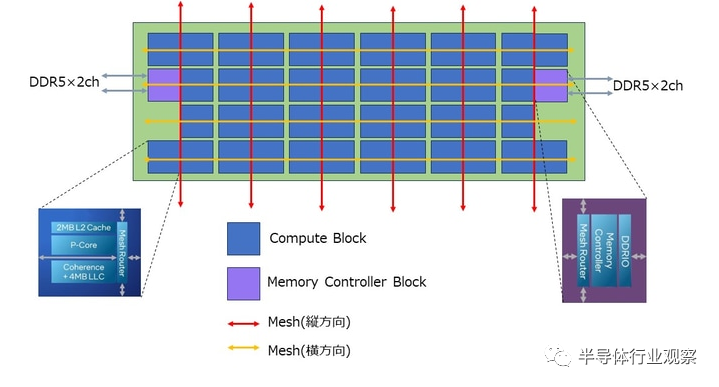
图7:Granite Rapids生成计算chiplet
用橙色绘制的水平网格在 Chiplet 内完成,但红色垂直网格通过 EMIB 连接多个 Chiplet。因此,对于一个chiplet,垂直方向有6个网格,水平方向有4个网格,但对于2个chiplet,垂直方向有6个网格,水平方向有8个网格,而对于3个chiplet,则有6个网格。垂直方向12个网格,水平方向12个网格,它就成为一本书。
嗯,到目前为止一切顺利。这是小芯片的一种形式,但问题是,这个计算块有多大?
以 Sapphire Rapids 为例,一块 400 平方毫米的tile包含 20 个等效块。换句话说,每个块的大小约为 4 毫米 x 5 毫米,即 20 平方毫米。实际上,每个块的尺寸较小,约为 13.2 平方毫米,因为 PHY 和其他组件放置在该块周围。
现在,如果我们忘记 PHY 并假设该块的大小不变,则 48 个块的大小将为 633.6 平方毫米。
现实中,由于工艺从Intel 7改为Intel 3,我们可以预期面积会更小(Intel公告称Intel 4中HP Library的面积将是Intel 7的0.49倍)。但是, L3缓存从1.875MB显着增加到4MB,工艺小型化对于这个L3缓存来说效果不是很大(因为布线层的间距比晶体管的尺寸影响更大。说实话,没有Intel 7 和 Intel 4 之间存在很大差异,Intel 3 可能也是如此),所以这并不是什么大问题,但远非差异的一半。那么,如果能够将633.6平方毫米压缩到600平方毫米左右,岂不是一个好主意?
考虑到将包含用于 EMIB 的 PHY 和用于 DDR5 的 PHY,预计虽然形状会横向较长,但面积约为 700 平方毫米,与 Emerald Rapids 相差不大。简而言之,它太大了,不能称为chiplet。
为什么Intel要选择良率似乎越来越差的解决方案呢?笔者认为,这主要是因为英特尔觉得Sapphire Rapids(包括下一个Granite Rapids,甚至之后的Diamond Rapids)之后的解决方案变成——“如果可能的话,我想制作一个巨大的整体die,但这在物理上是不可能的(标线限制),所以我认为它意思是“把它分开然后再重新组合起来”。这正是内部网格扩展后的样子。换句话说,他们可能希望将所有内容保留在一个芯片上,而不尽可能地划分功能。
这样做性能当然更好。而且,英特尔的巨型芯片方法可以大大降低 CPU 之间的通信延迟,并且对内存控制器的访问速度更快。作为权衡,预计验证工作将变得更加复杂,并且由于芯片尺寸更大,良率将下降。
但是,AMD在Chiplet上,却有了另一种思路。
AMD的思考
首先,我们看一下AMD在Chiplet上的演进,这首次在Ryzen 处理器上实现。
据了解,第一代 Ryzen 架构相对简单,采用SoC 设计,从内核到 I/O 和控制器的所有内容都位于同一芯片上。引入了 CCX 概念,其中 CPU 核心被分为四核单元,并使用无限高速缓存进行组合。两个四核 CCX 形成一个芯片。
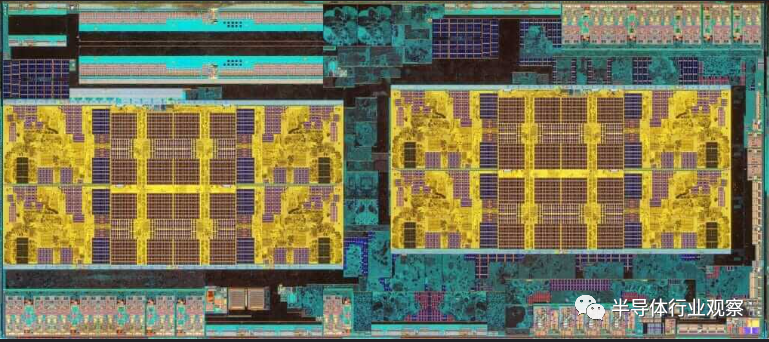
图8:AMD Ryzen 1000 Zen 1 CCD
值得注意的是,尽管推出了 CCX,但消费类 Ryzen 芯片仍然是单芯片设计。此外,虽然 L3 缓存在 CCX 中的所有核心之间共享,但每个核心都有自己的slice。访问另一个 CCX 的末级缓存 (LLC) 相对较慢,如果是在另一个 CCX 上,则速度更慢。这导致游戏等对延迟敏感的应用程序性能不佳。
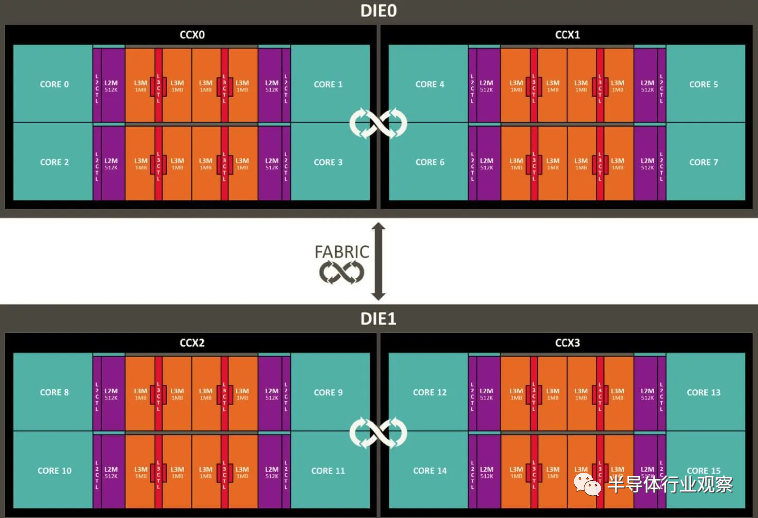
图9
到了Zen+ 时代,情况基本上保持不变(节点缩小),但 Zen 2 是一个重大升级。这是第一个基于小芯片的消费类 CPU 设计,具有两个计算芯片或CCD和一个 I/O 芯片。AMD 在 Ryzen 9 部件上添加了第二个 CCD,其核心数量在消费者领域前所未见。
16MB L3 缓存对于 CCX 上的所有核心来说更容易访问(读取:更快),从而大大提高了游戏性能。I/O 芯片被分离,Infinity Fabric 被升级。此时,AMD 在游戏方面稍慢一些,但提供了比竞争对手英特尔酷睿芯片更出色的内容创建性能。
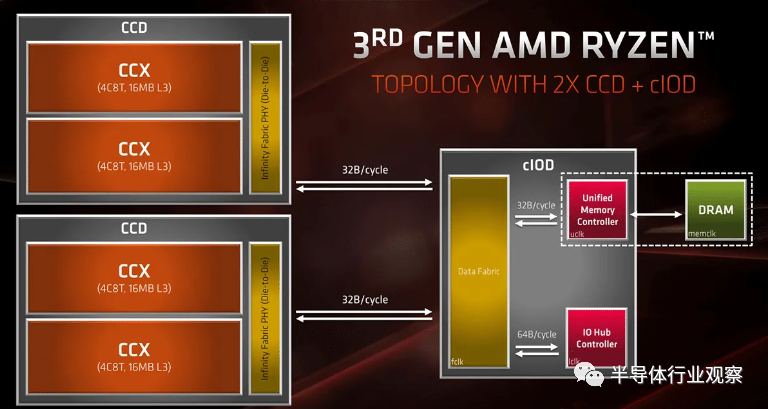
图10
Zen 3进一步完善了chiplet设计,取消了CCX并将八个核心和32MB缓存合并到一个统一的CCD中。这大大减少了缓存延迟并简化了内存子系统。AMD 锐龙处理器首次提供了比主要竞争对手英特尔更好的游戏性能。Zen 4 除了缩小 CCD 设计外,没有对 CCD 设计做出显著改变。

图11
来到Epyc系列处理上。资料显示,在第一代 AMD EPYC 处理器中,英特尔基于四个复制的小芯片。每个处理器都有 8 个“Zen”CPU 内核、2 个 DDR4 内存通道和 32 个 PCIe 通道,以满足性能目标。AMD 必须为四个小芯片之间的 Infinity Fabric 互连提供一些额外的空间。
据相关预估,在 14 纳米工艺中,每个小芯片的芯片面积为 213 平方毫米,总芯片面积为 4213 平方毫米 = 852 平方毫米。与假设的单片 32 核芯片相比,这意味着大约 10% 的芯片面积开销。基于使用成熟工艺技术的历史缺陷密度数据进行的 AMD 内部良率建模,估计四小芯片设计的最终成本仅为单片方法的约 0.59,尽管总硅消耗量多出约 10%。除了降低成本之外,他们还能够在产品中重复使用相同的方法,包括使用它们构建 16 核部件,将 DDR4 通道加倍并提供 128 个 PCIe 通道。
但这一切都不是免费的。当小芯片通过 Infinity Fabric 进行通信时,会产生延迟,并且同一小芯片上的 DDR4 内存通道数量不匹配,因此必须谨慎处理某些内存请求。因此到了第二代AMD EPYC处理器(ROME)上,AMD采用了双芯粒的方法。
据了解,AMD的第二代EPYC的第一个芯粒称为I/O die(IOD),是在一个成熟和经济的12nm工艺中实现的,包含8个DDR4内存通道,128个PCIe gen4 I/O通道以及其他I/O(如USB和SATA, SoC数据结构,和其他系统级功能)。第二个小芯片则是复合核心die(CCD),在7nm节点上实现。在实际产品中,AMD将一个IOD与多达8个ccd组装在一起。每个CCD提供8个Zen 2 CPU内核,因此这种排列方式可以在一个插槽中提供64个内核。

图12
在第三代的Epyc处理器(Milan)上,AMD提供多达64个核心和128个线程,采用AMD最新的Zen 3核心。该处理器设计有八个小芯片,每个小芯片有八个核心,与Roma类似,但这次小芯片中的所有八个核心都是连接的,从而实现了有效的双 L3 缓存设计,以实现较低的整体缓存延迟结构。所有处理器都将配备 128 个 PCIe 4.0 通道、8 个内存通道,大多数型号都支持双处理器连接,并且提供通道内存优化的新选项。所有 Milan 处理器都应通过固件更新与 Rome 系列平台直接兼容。
到了第四代Epyc处理器,AMD在其Chiplet架构上采用多达 12 个 5 纳米复杂核心芯片 (CCD) 的小芯片设计,其中I/O 芯片采用 6nm 工艺技术,而其周围的 CCD 则采用 5nm 工艺。每个芯片具有 32MB 的 L3 缓存和 1 MB 的 L2 缓存。因为AMD 的 Epyc 设计是完全集成的小芯片,也称为片上系统。这意味着它们将所有核心组件(例如内存和 SATA 控制器)集成到处理器中,主板上不再需要强大的芯片组,从而降低了成本并提高了效率。
AMD的产品技术架构师Sam Naffziger在一篇论文中还表示,AMD是第一批商业化引入硅中介层技术的公司之一,这让其在产品设计上拥有了更多优势。早前在接受IEEE采访的时候他更是直言““我们架构的目标之一是让它对软件完全透明,因为软件很难改变。例如,我们的第二代 EPYC CPU 由被计算芯片包围的集中式 I/O小芯片组成。当我们采用集中式 I/O 芯片时,它减少了内存延迟,消除了第一代的软件挑战。”
在内存控制器上,和上文提到的Intel做法不一样,AMD将内存控制器移到了IOD,而CCD只有CPU核心和L3缓存,所以有4/8/12多种CCD,不过两款产品都可以使用12 通道 DDR5。
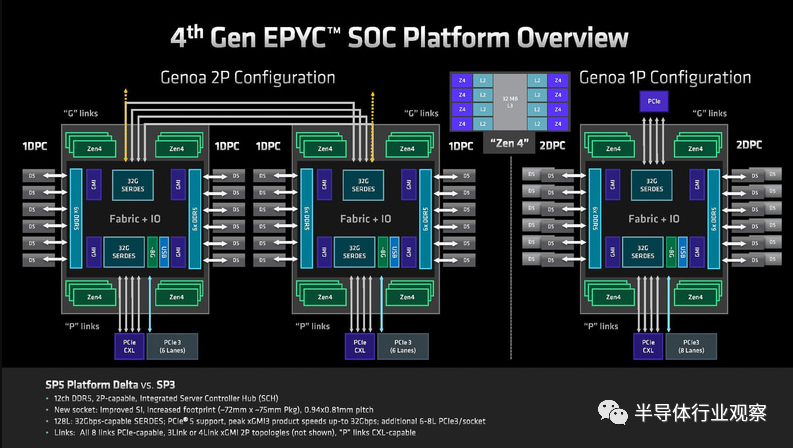
图13
在EPYC系列中,AMD也一直使用Infinity Fabric来连接CCD和内存控制器,这不但提高了灵活性,还降低了成本。但是,由于使用Infinity Fabric而带来了延迟增加的性能损失,AMD也不能幸免。即便如此,AMD还是通过使用大容量三级缓存等努力将影响降至最低,这似乎并不是英特尔的选择。
正如Sam Naffziger所说,AMD正在寻找扩展逻辑的方法,但 SRAM 更具挑战性,而模拟的东西绝对无法扩展。所以AMD已经采取了将模拟与中央 I/O 小芯片分离的步骤。借助3D V-Cache(一种与计算芯片 3D 集成的高密度缓存小芯片),AMD分离出了 SRAM。展望未来,公司可能会看到有更多类似的操作。
最后,我们重申一下,这两家公司的Chiplet战略都是基于当前所见的产品所做的分析,并不代表他们的最终策略。但从这些分析中,我们无疑能给Chiplet的设计带来更多的思考。

 下载ECAD模型
下载ECAD模型





-%E5%89%AF%E6%9C%AC.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)







.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
 [课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
[课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
