


 1460
1460
半导体行业正面临一个巨大的转折点,以语言大模型为代表的人工智能技术的质变,让整个世界处于计算范式转折的前夜,并行计算即将成为主流,半导体行业被裹挟其中。哲库的饮恨离场,不过是芯片产业风云巨变的开场。
上个月底,阿里云宣布了“史上最大规模降价”,其中核心产品价格全线下调15%-50%,存储产品最高降价50%。对于云服务厂商来说,支撑起高效和高性价比服务的,是硬件和云计算能力的双重优势。云计算也是大模型军备竞赛的技术支撑,ChatGPT就是鲜活案例。
ChatGPT能真正实现大规模应用,背后少不了微软的支持。微软云OpenAI是ChatGPT的独家云供应商,ChatGPT大模型训练所需要的海量数据,也来自微软云多年的积累。正如李彦宏所言,“之前企业选择云厂商更多看算力、存储等基础云服务。未来,更多会看框架好不好、模型好不好,以及模型、框架、芯片、应用这四层之间的协同。”
阿里云宣布要上市,为什么是现在?因为人工智能时代,以GPU、TPU为代表的异构计算芯片,将成为智能化基础设施。阿里云如果不能主动折旧(降价),融资(上市即加杠杆)拥抱新的基础设施架构,可能会错过下一波而被边缘化。
纵观全球计算主芯片,异构已经不是一个未来潮流,而是现实落地的主流和顶流。
苹果新一代SOC芯片产品,M2 Pro 和 M2 Max,大幅集成GPU功能。M2 Pro芯片提升M2 芯片原有架构,带来多达12核的中央处理器和多达19核的图形处理器,M2 Max芯片在 M2 Pro的强大性能基础上更进一步,带来多达38核的图形处理器。两款芯片还有增强的定制技术加持,包括速度更快的16核神经网络引擎,每秒可进行最多达 15.8 万亿次运算,较前代芯片快达40%。
Intel一直在为其异构架构理念不停地做重磅收购,2015年收购FPGA供应商Altera,2016年收购AI芯片供应商Nervana,2017年收购了ADAS芯片供应商Mobileye和AI芯片供应商Movidius,2018年收购eASIC,2019年收购云端AI芯片供应商Habana Labs。

AMD收购Xilinx后,Zynq异构系列的战略不用多说,传言AMD与微软合作,合作开发一款代号为雅典娜(Athena)的自主研发的人工智能芯片。
谷歌张量处理器(tensor processing unit,TPU)是该公司为机器学习定制的专用芯片(ASIC),第一代发布于2016年,成为了AlphaGo背后的算力。与GPU相比,TPU采用低精度计算,在几乎不影响深度学习处理效果的前提下大幅降低了功耗、加快运算速度。同时,TPU使用了脉动阵列等设计来优化矩阵乘法与卷积运算。

如今TPU已经发展到了第四代,虽然每个TPU的处理速度都比不上最好的英伟达AI芯片,但谷歌用于连接芯片和在芯片之间传递数据的光电路交换技术弥补了性能差异。
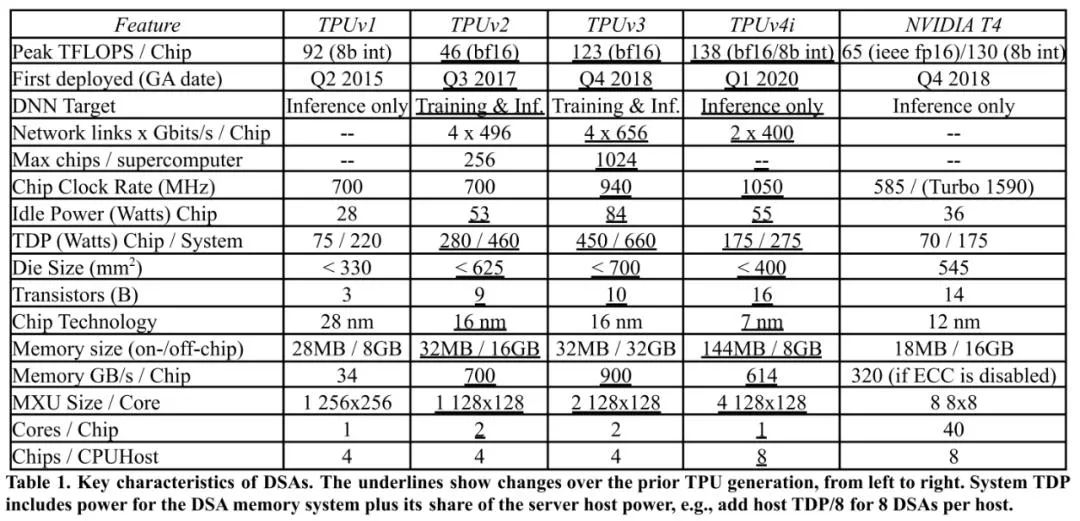
其他互联网公司也有自研芯片的,但基本上都是基于ARM架构,比如亚马逊的推理芯片Inferentia和训练芯片Trainium,还有META昨天刚刚发布的AI加速器芯片MTIA(Meta训练和推理加速器)。

AI风潮之下,没有什么领域不会被波及,AI深入到边缘和终端装置,已经是一个长期必然的大方向,我相信MCU也不会例外。
随着物联网设备的普及和应用场景的扩大,对于更智能化和自主决策能力的需求也在增加,作为物联网设备中必不可少的大脑——MCU,正朝着更智能化、更强大的方向发展。
传统认知中,人工智能(AI)相关的深度学习应用,只有算力充沛的MPU或者是PC才能玩得转,MCU作为边缘物联网的主控芯片,其在AI中担任的主要功能是推理和决策。
将AI能力集成到MCU上,使得AI算法可以实时地在设备本地进行处理和响应,而无需依赖于云端或其他远程服务器。这提高了系统的实时性和即时响应能力,使得设备能够更快速地做出决策和反应,且可以在低功耗的情况下实现高效的AI计算。
现在为边缘设备创建机器学习模型正成为一种大的趋势,这些模型称为微型机器学习或TinyML,它主要适用于内存和处理能力有限的设备,以及互联网连接不存在或有限的设备。TinyML使在MCU上运行深度学习模型成为可能。TinyML在MCU上的应用越来越普遍。
各大MCU巨头其实很早就已开始布局。
恩智浦:2018年推出了机器学习软件eIQ软件,该软件能够在恩智浦EdgeVerse微控制器和微处理器(包括i.MX RT跨界MCU和i.MX系列应用处理器)上使用。并推出了AI工具链NANO.AI。最近恩智浦推出了MCX N系列,MCX N94x和MCX N54x MCU系列中集成了恩智浦设计的用于实时推理的专用片上神经处理单元 (NPU)。据悉,与单独使用CPU内核相比,片上NPU的ML吞吐量最高可提高30倍。
ST:2021年6月3日,意法半导体宣布收购边缘AI软件专业开发公司Cartesiam。Cartesiam成立于2016年,总部位于法国土伦,专门从事人工智能开发工具研发,让基于Arm的MCU具有机器学习和推理能力。ST即将推出第一个带有神经网络硬件处理单元(Neural-Art Accelerator)的通用微控制器——STM32N6,这款MCU与其STM32MP1微处理器(运行频率为 800MHz 的双 Cortex-A7)相比,STM32N6 的推断速度提高了25倍。
瑞萨:去年瑞萨收购了Reality AI,主要为汽车、工业和商业产品中的高级非视觉传感提供范围广泛的嵌入式人工智能和微型机器学习 (TinyML) 解决方案。
英飞凌:2023年5月16日,英飞凌宣布,已收购总部位于瑞典斯德哥尔摩的初创公司Imagimob AB。Imagimob是快速增长的微型机器学习和自动机器学习(TinyML 和 AutoML)市场的领先者。以提升其微控制器和传感器上的TinyML边缘 AI 功能。
国内MCU厂商大部分仍处于模仿兼容传统STM32的同质化水平,忙于内卷比拼价格,生存还是个问题,基本上还顾不上未来的布局。
我司作为MCU的新进厂商,由于客户需求与STM32兼容,但是在其中赠送了FPGA的异构逻辑,FPGA本身就可以用于并行加速用,其核心架构与TPU的脉动阵列矩阵运算有异曲同工的相似之处。我们下一代产品中扩大逻辑容量后将可直接与TinyML的边缘推理整合。
我们正在迈入AIoT时代,AI深入到边缘和终端装置,已经是一个长期必然的大方向。做好技术准备,国产厂商方能迎接未来转折窗口的挑战。






