


















 1097
1097
和 ChatGPT 在 AIGC(AI- Generated Content,人工智能生成内容)领域一样具备颠覆性的事情正在发生。
4 月 11 日,自动驾驶技术公司毫末智行在其第八届 HAOMO AI DAY 上,重磅发布行业首个自动驾驶生成式大模型 DriveGPT,中文名「雪湖·海若」,该模型参数规模达到 1200 亿,可用于解决自动驾驶研发过程中困扰已久的认知决策问题,并通过能力迭代,最终实现端到端自动驾驶。
此前,受制于传统模型「数据量小、基于规则」等局限性,智能驾驶技术进展一度较为缓慢,甚至不少从业者都对未来产生了自我怀疑,在这样的背景下,两年前,毫末率先投入到大模型技术的研发之中,旨在寻找新的突破。
经历了先行探索和反复验证,毫末成功找到了突破口——生成式大模型,通过在行业首个将 GPT 落地到自动驾驶领域,大大加速了更高阶智能驾驶的落地应用。

「生成式大模型将成为自动驾驶系统进化的关键,基于 Transformer 大模型训练的感知、认知算法会逐步在车端进行落地部署。」毫末董事长张凯在 HAOMO AI DAY 上对行业未来发展趋势作出论断。

毫末 CEO 顾维灏也表示:「DriveGPT 雪湖·海若将会重塑汽车智能化技术路线,让辅助驾驶进化更快,让自动驾驶更早到来。」
顾维灏在自动驾驶技术领域的眼光独到,布局非常领先。
事实上,毫末在 2021 年就已经开始了 Transformer 大模型技术的探索,并快速落地应用到 BEV 视觉感知算法当中,然后又以五大模型的方式来实现自动驾驶感知、认知算法的快速升级,现在这些大模型将统一到 DriveGPT 生成式大模型当中,目标将实现端到端自动驾驶。
毫末的探索始终走在行业技术探索的前列。

据了解,新摩卡 DHT-PHEV 即将首发搭载 DriveGPT 雪湖·海若量产上市,届时,用户市场还将迎来一轮新的震撼。
「毫末真正重塑了行业信心,」一位业内人士略微激动地说道,「这将是一场革命。」
DriveGPT 雪湖·海若,如何颠覆智能驾驶
在介绍 DriveGPT 雪湖·海若之前,先回顾一下 ChatGPT 的概念,其全称是 Chat Generative Pre-trained Transformer,字面意思是用于聊天的生成式预训练 Transformer 大模型。
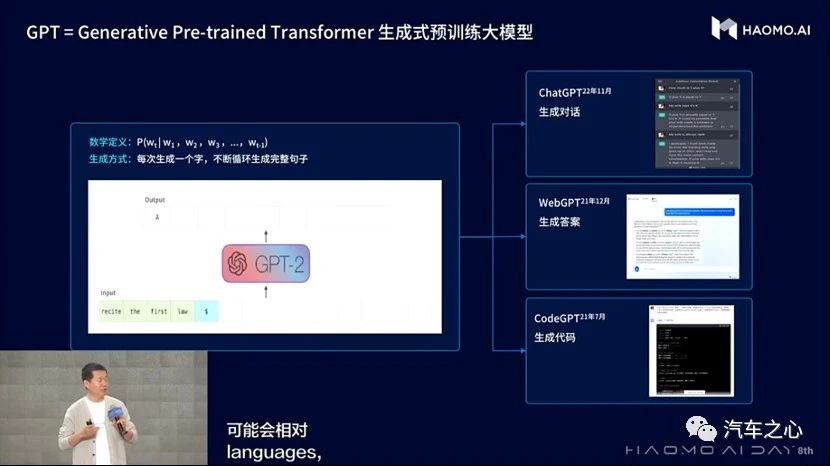
其中 Transformer 是 ChatGPT 的重点,最早由谷歌在 2017 年提出,该模型基于注意力机制的设计,可以实现出色的算法并行性,因而迅速在自然语言处理(NLP) 领域流行起来,ChatGPT 就是其最新成果。
Transformer 大模型对于智能驾驶来说也不陌生,在 NLP 中奠定了核心地位之后,被逐渐被引入计算机视觉(CV)领域,后又被特斯拉、毫末智行等行业龙头先行引入自动驾驶系统中,用于提升感知端的模型效果。
如今,毫末在 Transformer 大模型的应用上更进一步,将其率先拓展到智能驾驶系统认知端,DriveGPT 雪湖·海若由此诞生。
从同样使用 Transformer 大模型的角度来说,ChatGPT 和 DriveGPT 雪湖·海若属于同宗同源。
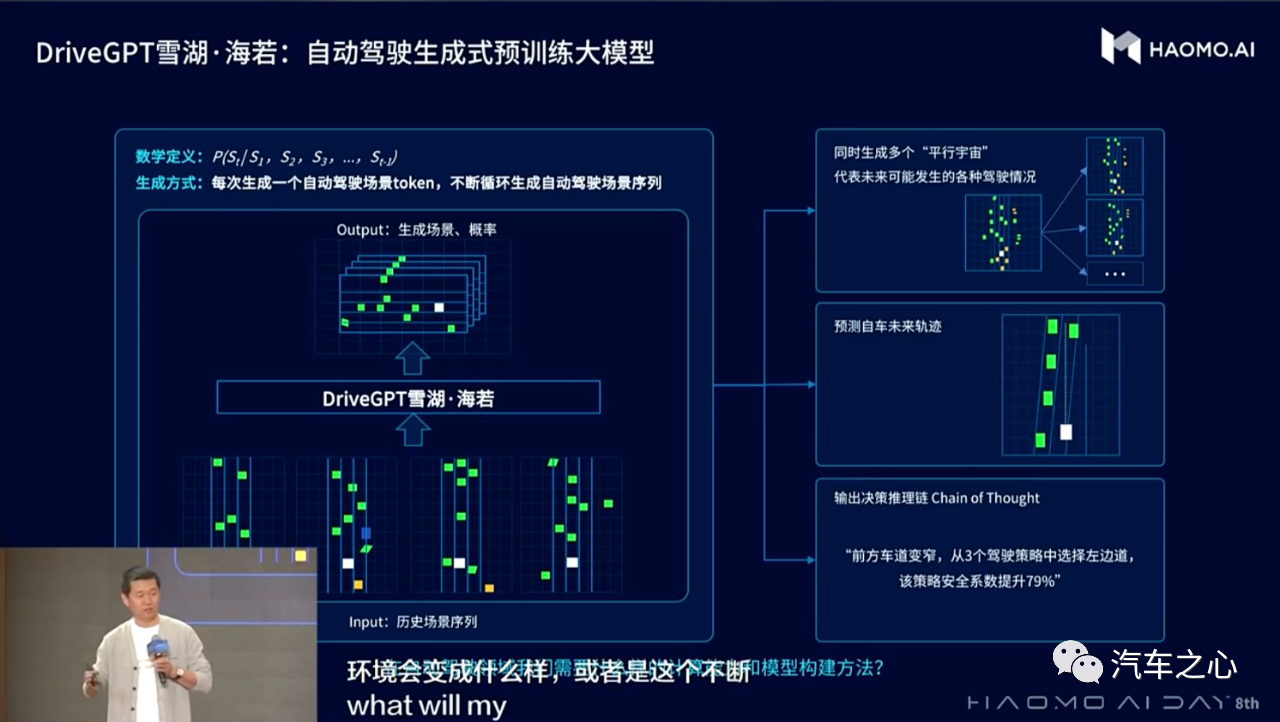
其中,ChatGPT 是对话式的生成式自然语言模型,输入是自然语言的文本串,输出是自然语言的文本,可以完成通用的下游语言生成任务,比如多轮对话、代码生成、翻译、数学 运算等能力。
而毫末 DriveGPT 雪湖·海若是用于自动驾驶场景的生成式大模型,输入是感知融合后的文本序列,输出是自动驾驶场景文本序列,即将自动驾驶场景 Token 化,形成「Drive Language」,最终完成自车的决策规控、障碍物预测以及决策逻辑链的输出等任务。
DriveGPT 雪湖·海若首先在预训练阶段通过引入量产驾驶数据,训练初始模型,再通过引入驾驶接管 Clips 数据完成反馈模型 (Reward Model) 的训练,然后再通过强化学习的方式,使用反馈模型去不断优化迭代初始模型,形成对自动驾驶认知决策模型的持续优化。

具体来说,DriveGPT 雪湖·海若会通过人类反馈强化学习的方式进行迭代,用 DriveGPT 雪湖·海若最新模型 (Active Model) 对真实场景 Case 做生成,产出多种场景序列结果,再用反馈模型给这些结果进行打分排序,目标是把好的结果排上来,差的结果排下去,然后与初始模型 (Pretrain-Model) 的生成概率做比较,放大比分。最后通过强化学习的方式将参数再次更新到最新模型 (Active Model) 中,一直反复这个迭代过程。
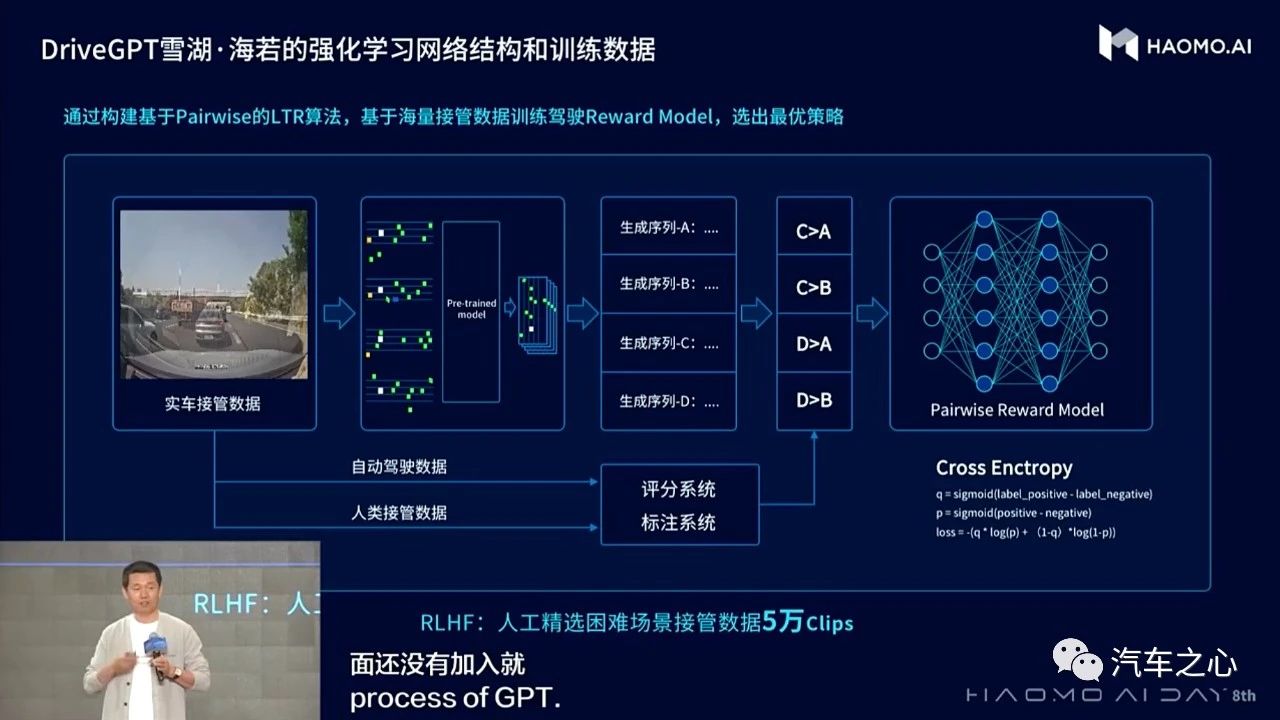
其中,Reward Model(反馈模型) 的训练过程是独立的,使用带有偏序关系的 Pair 样本对来训练,这些样本对来自于接管 Case,毫末将与人类驾驶结果相似的模型结果作为正样本,与被接管轨迹相似的作为负样本,这样来构建偏序对集合,再利用 LTR(Learning To Rank) 的思路去训练 Reward Model,进而得到一个打分模型。

此外,DriveGPT 雪湖·海若还可以输出决策逻辑链:即在输入端提供 Prompts(提示语),根据提示输出含有决策逻辑链 (Chain of Thought) 的未来序列。
毫末 CSS 自动驾驶场景库是 CoT 的重要输入,拥有超过几十万个细颗粒度场景,将 Prompt 提示语和完整决策过程的样本交给模型去学习,学到推理关系,从而将完整驾驶策略拆分为自动驾驶场景的动态识别过程,完成可理解、可解释的推理逻辑链生成。

除了用作认知决策,DriveGPT 雪湖·海若还可以逐步应用到城市 NOH、捷径推荐、智能陪练以及脱困场景中。
有了 DriveGPT 雪湖·海若的加持,车辆行驶会更安全;动作更人性、更丝滑,并有合理的逻辑告诉驾驶者,车辆为何选择这样的决策动作。
对于普通用户来说,车辆越来越像老司机,用户对智能产品的信任感会更强,理解到车辆的行为都是可预期、可理解的。
尽管 DriveGPT 雪湖·海若刚出世就拥有强大的功能,但这还不是它的「终局」,毫末对于 DriveGPT 雪湖·海若的目标是实现端到端自动驾驶,后续毫末会持续将多个大模型的能力整合到 DriveGPT 雪湖·海若中。
与此同时,毫末也对外构建 DriveGPT 雪湖·海若生态,通过对行业提供开放服务,促进自动驾驶的从业者和研究机构,快速构建基础能力,释放创新。

汽车之心获知,毫末 DriveGPT 雪湖·海若首批定向邀请了北京交通大学计算机与信息技术学院、高通、火山引擎、华为云、京东科技、四维图新、魏牌新能源、英特尔等加入。
事实上,毫末对于大模型的开放从 DriveGPT 雪湖·海若的中文名「雪湖·海若」即可窥见。
据了解,「海若」一词出自《庄子·秋水》中的神话人物北海若,在该书中,另一神话人物河伯请教北海若,何谓大小之分,北海若教导河伯说,不因天地而觉大,不因毫末而觉小。
毫末据此把 DriveGPT 中文名命名为「海若」,寓意着智慧包容、海纳百川,为行业发展贡献力量。
自动驾驶生成式大模型「第一枪」,为何由毫末打响
自动驾驶领域顶级玩家众多,毫末凭何在全球首个推出了自动驾驶生成式大模型 DriveGPT 雪湖·海若?
要回答这个问题,首先要理清楚毫末 DriveGPT 雪湖·海若的本质,它是应用在智能驾驶上的人工智能,就必然离不开人工智能三要素:算法、数据和算力,而这三者恰恰是毫末具备领先性优势的地方。
首先在算法的技术路线上,毫末早早就坚定选择走渐进式发展路线,比「跃进式」玩家的量产时间更早,更快形成规模化,从用户真实使用场景中积累足够多的数据。

毫末还清晰地提出了从自动驾驶 1.0 时代到自动驾驶 3.0 时代的演进路径,并率先进入以数据驱动为核心的新时代。
从这时开始,自动驾驶获取的数据量与数据多样性将呈现指数级膨胀,在深度学习主导中,与大模型相辅相成,真正去解决自动驾驶最后的长尾难题。
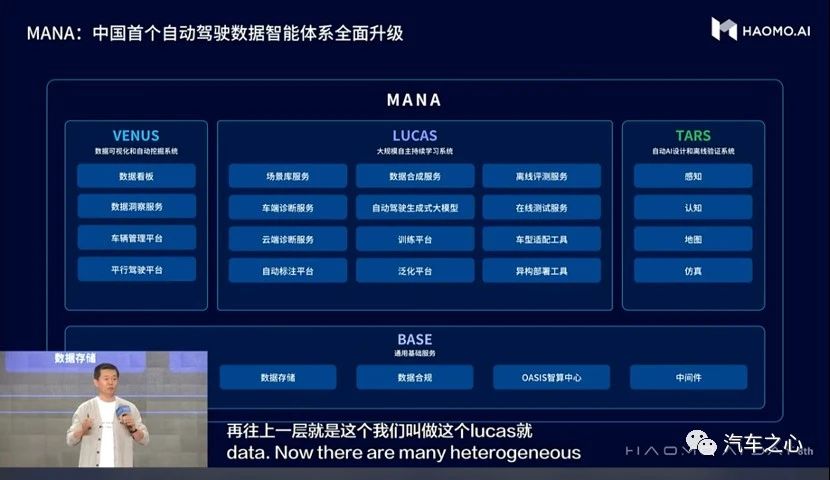
在 2021 年 12 月第四届 HAOMO AI DAY 上,毫末发布中国首个数据智能体系 MANA,其由四大板块组成,分别是 TARS、LUCAS、VENUS 和 BASE。
其中,BASE 是整个系统架构的底层,包括数据底座、数据融合、PoseidonOS 等。
其他三大板块置于上层:
TARS 代表毫末智行的开发的原型算法,包括感知、规划决策、地图定位、仿真引擎;
LUCAS 是提取数据价值,以数据驱动系统能力持续迭代的核心子系统,解决场景泛化,评测和部署的问题;
VENUS 则是数据看板,以参考标准评价算法的好坏。

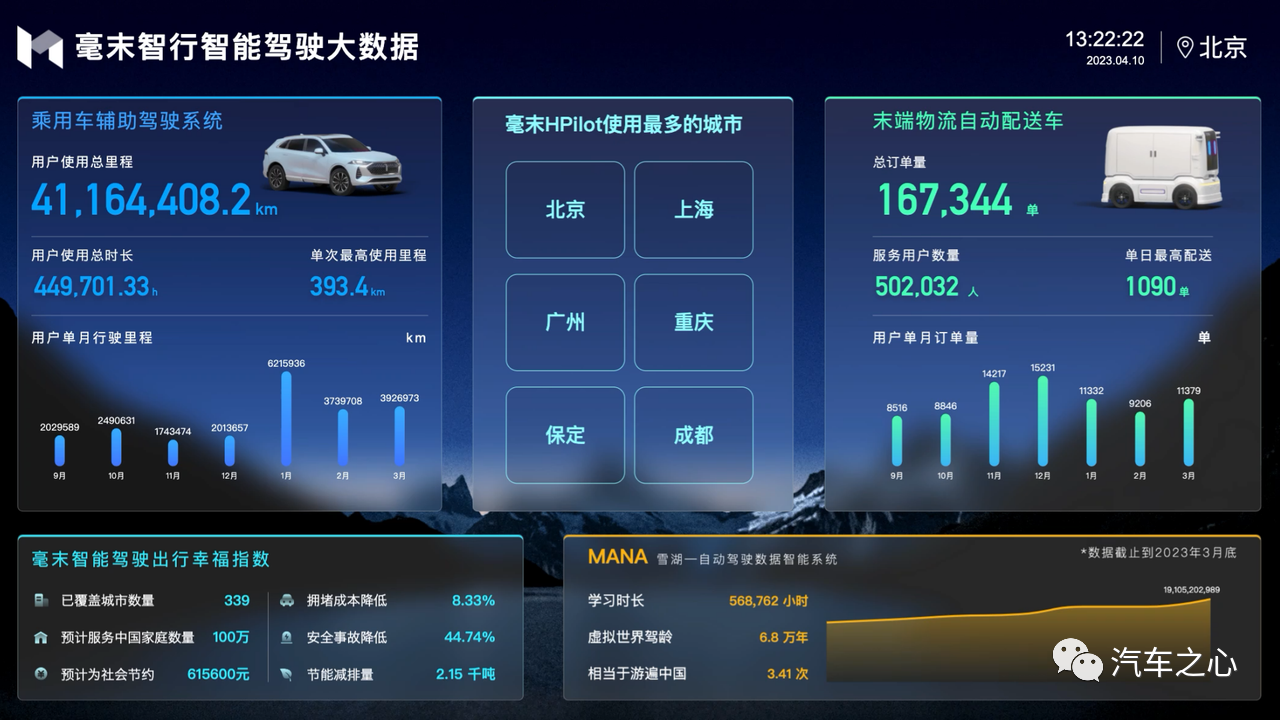
在 MANA 的加持下,毫末辅助驾驶系统持续迭代,并不断积累数据,目前用户使用毫末辅助驾驶的行驶里程超过 4000 万公里,而这即成就了 DriveGPT 雪湖·海若的数据底座。
毫末 DriveGPT 雪湖·海若使用了基于这 4000 万公里的驾驶数据做 Pretrain(预训练),为了对生成决策结果进行调优,又引入大约 5 万段驾驶接管 Clips 数据,完成模型的训练和推理。
距离上一届 HAOMO AI DAY 三个月时间过去,毫末在数据驱动六大闭环体系上又实现多重进展:
在用户需求闭环方面,毫末在道路曲率限速、换道时机、换道平顺性、跟车控制平顺性等产品性能上持续优化,并进行新功能的体验反馈;
在研发效能闭环方面,毫末将数据驱动理念深入到包括产品需求定义、感知与认知算法开发、系统验证环节等产品开发流程的各个环节,使得整体开发效率较去年提升 30%;
数据积累闭环方面,毫末在车端部署诊断服务的相关数据场景标签覆盖 92% 的驾驶场景,在离线评测升级上,实现场景数据库到仿真测试用例的自动化转化,覆盖 97% 的用户使用高频场景,同时在大规模纯视觉 4D 标注和场景编辑的能力和效率上均达到行业顶尖水平;
在数据价值闭环方面,毫末大模型正在持续挖掘自动驾驶数据价值并解决自动驾驶的关键问题;
关于产品自完善闭环,毫末实现售后问题处理速度较传统方式的十倍效率提升,实现最快 10 分钟定位售后问题。
两年时间有效挖掘产品提升点,问题闭环率达 76%,并且实现 8 轮 HWA 性能提升和 5 轮 NOH 软件迭代,帮助客户成功实现 8 次 OTA 产品在线升级;
最后在业务工程化闭环方面,毫末进一步完善了从采集回流环节、标注训练环节、系统标定环节、仿真验证环节到最终 OTA 释放环节的产品研发全流程工程化闭环。
毫末不断进步的数据驱动六大闭环能力,进一步加速毫末冲刺进入自动驾驶 3.0 时代的步伐,并形成相应的护城河。
除了在技术路线和数据积累上保持领先,毫末之所以能让 DriveGPT 雪湖·海若横空出世的原因还在于提前布局算力。

2023 年 1 月 5 日,第七届 HAOMO AI DAY 上,毫末与火山引擎联手发布了智算中心「雪湖·绿洲」(MANA OASIS),这也是中国自动驾驶行业首个也是最大的智算中心,每秒浮点运算达到 67 亿亿次。
基于雪湖·绿洲,毫末得以训练出参数规模达 1200 亿的 DriveGPT 雪湖·海若模型。
从首个提出在技术路线上步入自动驾驶 3.0,到发布中国首个数据智能体系 MANA,再到建设中国自动驾驶行业首个也是最大的智算中心,毫末在前期如此多的积累,让其在自动驾驶生成式大模型的推出上,再次夺下「首个」,变得顺理成章。
尽管已经走在最前面,毫末的脚步也没有停下。
在本届 HAOMO AI DAY 上,顾维灏透露,为给 DriveGPT 雪湖·海若做好算力支持,毫末对智算中心 MANA OASIS(雪湖·绿洲) 进行了三大升级,首先是与火山引擎全新搭建了「全套大模型训练保障框架」,以保障毫末大模型训练的稳定性。
据了解,训练保障框架包括 Monitor&Alert、Tracer&Log、Profile&Checkpoint 等功能,通过训练保障框架,集群调度器可以实时获取服务器异常、并及时将异常节点从训练 pod group 中删除,再结合 CheckPoint 功能,利用 VePFS 高性能存储和 RDMA 网络高效分发。此外,训练保障框架实现了异常任务分钟级捕获和恢复能力,可以保证千卡任务连续训练数个月没有任何非正常中断,有效地保障了大模型训练的稳定性。
其次,毫末还将「增量式学习」推广到大模型训练,构建 DriveGPT 雪湖·海若大模型学习系统。
具体来说:
(1)基于量产自动驾驶规模优势,毫末研发出以真实数据回传为核心的增量学习技术;
(2)针对不同时段数据回传量差异巨大,MANA OASIS 训练平台依靠弹性调度能力,自适应数据规模大小。同时将增量学习推广到了大模型训练,构建了一个大模型持续学习系统,自主研发任务级弹性伸缩调度器,分钟级调度资源,集群计算资源利用率达到 95%;
(3)结合增量学习数据以动态数据流的形式,持续不断将量产回传和筛选的存量数据,传入感知和认知 Pre-train 大模型。系统定时采样评测模型学习状态,出现异常快速回滚。持续提取最佳模型版本。
最后,毫末优化关键算子,以提升数据吞吐量,提升 DriveGPT 雪湖·海若大模型训练效率。
针对 Transformer 大矩阵计算,通过对内外循环的数据拆分,尽量保持数据在 SRAM 中,以提升计算的效率。
「Transformer 类大模型计算复杂度高,训练难度大。在传统训练框架中,例如 PyTorch,算子流程很长,包括 Attention、LayerNorm、Dropout、Softmax 等多个环节,通过引入火山引擎提供的 Lego 算子库实现算子融合,端到端吞吐提升 84%。」顾维灏介绍道。
2023 年智驾竞争白热化,毫末也开始干掉超声波雷达?
过去几年,智能驾驶在国内市场增长迅速,第三方数据显示,2022 年在乘用车上,L2/L2+功能的搭载率接近 30%,时间来到 2023 年,行业更是全线爆发。

高速 NOA 等 L2+功能正成为标配,搭载行泊一体功能的智驾产品也迎来前装量产潮,而另一边,城市 NOA 也开启抢位战,玩家们纷纷比拼在多城市落地的速度以及真实用户覆盖面。
这其中,智驾方案性价比以及用户价值被前所未有地凸显出来。前者关系到智能驾驶能不能被更广泛的用户使用到,后者则与智能驾驶好不好用直接挂钩。
张凯也提到:「车主的使用频率和满意度开始成为产品竞争力的重要衡量标准。」毫末的应对之策其一是修炼好内功,进而向外挤出「成本」,降低智能驾驶使用门槛;其二是通过领先的技术布局、数据闭环体系等,为用户提供最优选择。

在降本上,毫末的第一步是开始像特斯拉一样,验证能否使用鱼眼相机进行测距满足泊车要求,以成功去掉超声波雷达,进一步降低整体智驾成本。
据了解,毫末把视觉 BEV 感知框架引入到车端鱼眼相机,目前做到了在 15 米范围内达到 30cm 的测量精度,2 米内精度高于 10cm 的视觉精度效果,未来还有望进一步提高对于障碍物的轮廓边界识别和测量的精度。

此外,毫末还升级 MANA 视觉感知能力,可实现单趟和多趟纯视觉 NeRF 三维重建和虚拟动态物体合成,重建道路场景更逼真,肉眼几乎看不出差异。
通过 NeRF 进行场景重建后,就可以编辑合成真实环境难以收集到的 Corner Case,模拟城市复杂交通环境,用更低成本测试提升城市 NOH 能力边界,更好提升应对城市复杂交通环境。
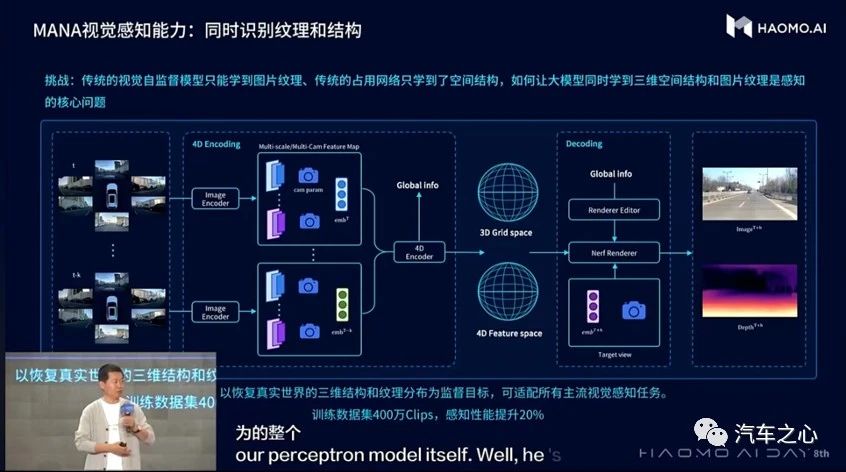
在提升用户价值上,毫末的打法是在技术上「增效」,成功实现 MANA 视觉感知对于三维空间结构和图片纹理的同时学习,让模型练好内功理解场景中的结构、速度和纹理等核心信息,最终将输出渲染得到结果和真实的后续视频保持一致。
顾维灏表示,这一过程使用了 400 万 Clips 训练数据集,使 MANA 视觉感知性能提升了 20%。
「我们一直提到,基于真实用户场景的反馈数据能够让我们更好的优化产品,让产品进步的更快。所有技术都要转化为对人有用的产品才最有价值。现在,毫末的产品正在为用户提供着更多价值。」

除了在技术上不断收获进步,毫末在商业化进展上也取得重大胜利,张凯透露,毫末已与 3 家主机厂签署战略合作协议,达成面向 L2+级别智能驾驶领域的全方位战略合作,相关项目已经在交付中。
2023 年一季度,毫末又迎来了映驰科技、中国自动化学会等更多合作伙伴,秉持着「6P 开放合作原则」,至此,毫末生态伙伴已达近百家。
基于以上取得的种种成就,毫末为 2023 定下的四大战役正在全面突围。

首先在智能驾驶装机量王者之战上,毫末三代乘用车产品搭载车型近 20 款,HPilot2.0 日均里程使用率 12.6%;
此外,HPilot 还在欧盟、以色列等地区和国家得到使用,墨西哥、俄罗斯、中东、南非、澳大利亚等市场也将陆续投放。

其次在大模型巅峰之战中,毫末自动驾驶生成式大模型 DriveGPT 雪湖·海若已经发布,接下来,将携手合作伙伴率先探索包括智能驾驶、驾驶场景识别、驾驶行为验证、困难场景脱困等四大应用能力。

例如在驾驶场景识别中,毫末建立起一套基于 4D Clips 的方案,相比行业对一张图片给出正确标注结果,需要付出约 5 元的代价,使用 DriveGPT 雪湖·海若的场景识别服务,单帧图片整体标注成本直线下降到 0.5 元,仅相当于前者的 1/10。
接下来,毫末会逐步向行业开放图像帧及 4D Clips 自动标注服务的使用,此举将大幅降低行业使用数据的成本,提高数据质量,从而加速自动驾驶技术的快速发展。

此外,在城市 NOH 百城大战里,毫末城市 NOH 将在北京、保定、上海等第一批城市率先落地,具体到车型,除了前面提到的新摩卡 DHT-PHEV,还将搭载魏牌蓝山,并以安全为先、用户为先、规模为先的原则,到 2024 年有序落地 100 城,目前量产落地至少领先业内一年以上时间。
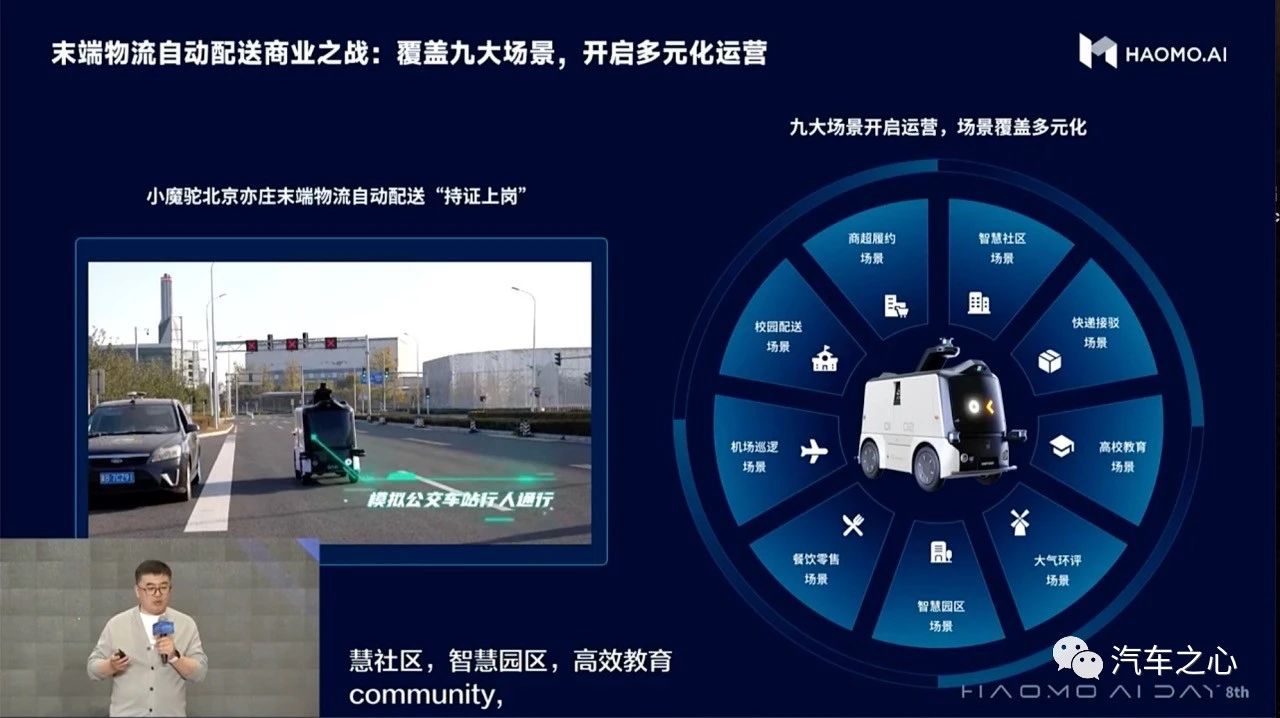
最后,需要指出的是末端物流自动配送车商业之战也已经打响,毫末末端物流自动配送车小魔驼 2.0 获北京亦庄无人配送车车辆编码,开启亦庄运营,截止目前,已履约商超、智慧社区、校园配送、 餐饮零售、机场巡逻、高校教育、快递自提、智慧园区、大气环评等九大场景。
2023 年,AI大模型一夜火爆,让所有人惊呼人工智能的时代真正开启,英伟达 CEO 黄仁勋称这是「iPhone 时刻」,比尔·盖茨大赞堪比互联网的发明,然而事实上,任何技术的爆发都不是一刻之间,往往前期已经经历了较深的铺垫。
毫末 DriveGPT 雪湖·海若也是如此,其源自于大模型、大数据和超算中心的深厚积累,才得以一鸣惊人,率先在业内开启自动驾驶技术发展的黄金时代。

借用顾维灏在本届 HAOMO AI AI DAY 上的结束语:
「很多人问我,为什么自动驾驶领域的 GPT 是毫末先做出的? 毫末成立到现在接近三年半时间。这三年多时间,很多事物都发生了变化,但是毫末对技术的坚定投入始终未变。我们始终热爱技术,枕戈待旦,全力冲刺。再难,我们都不会放弃。」






.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
-1.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
-%E5%89%AF%E6%9C%AC.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
