













 145
145
在消费电子市场上,智能手机,智能家居、可穿戴设备以及智能音箱等各类智能硬件产品中,AI 已被广泛应用。智慧城市、智慧交通、智慧物流等行业市场 AI 应用正加速落地;AI 也将成为自动驾驶的重要核心技术之一。可以说 AI 技术正不断的渗透到各行各业,并且发挥越来越重要的作用。与此同时,对于 AI 应用的性能要求也将越来越苛刻。低延迟、低成本、超节能逐渐成为 AI 技术在端侧应用的必要条件。
捷飞科芯的 AI 芯片及解决方案正是为应对这一挑战运用而生。
低时延、低成本、超节能
JF3010,这是一款革命性的 AI 芯片,低时延、低成本、超节能,是目前业界性能功耗比最强的 CNN 加速器。JF3010 由捷飞科芯(上海)计算技术有限公司团队研发,这是一家重点以人工智能技术的深度研究以及 AI 计算加速芯片的设计为发展方向的企业。

JF3010 产品特性:
- 计算峰值速度:2.8Tops/ 秒
- 单芯片峰值功耗:223 毫瓦
- 封装后面积:6mm x 6mm
- 时钟范围:50-200 MHz
- 片上储存器类型:SRAM
- 片上存储能力:8 MB
- 图片输入尺寸:448 x 448
- 外部接口:USB 3.0
- 网络拓展:支持多芯片级联
- 适配神经网络:VGG16,ResNet 18, MobileNet-V1, 其他类似网络
- 生产工艺:28nm
JF3010 相较于传统 CPU 和 GPU 的架构,去除了外部 I/O,去除了数据总线,采用分布式矩阵架构,分布式储存单元,具备超高速通信,可以在低时钟周期内实现海量并行运算,与市面上的 AI 芯片性能指标对比,JF3010 性能功耗比一骑绝尘,将近是同类产品的 4 倍。
JF3010 有如此强的性能主要依赖其分布式矩阵架构——基于 MPE 与 APiM 架构,免外部 DDR、存内计算,可以提供分类、检测、分割场景的软硬件一体化解决方案。
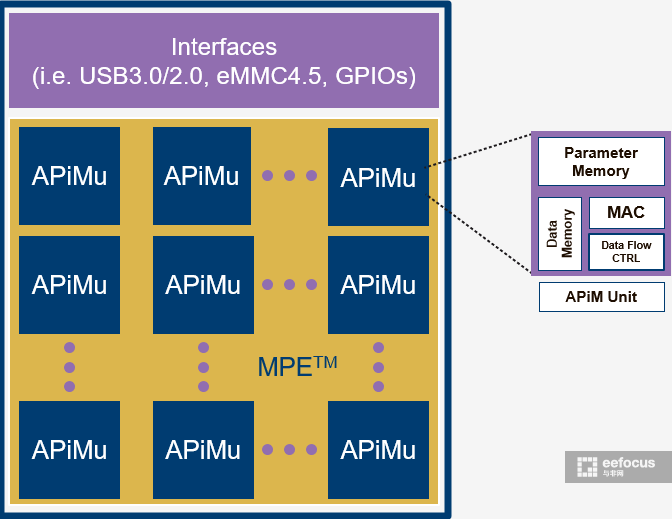
MPE 与 APiM 架构解析:
- APiM 消除了由于 AI 海量数据重复计算带来的数据移动瓶颈:
- 显著提升 AI 计算速度
- 大规模降低芯片能耗
- 芯片能耗分配:
- I/O=70%; Bus=20%; Calculating=10%
- APiM CNN 加速芯片新特性:
- 一次性神经网络预装
- 无需数据总线
- 无需外挂存储器
- 外部数据直接流过芯片完成 CNN 计算
- APiM 架构无缝支持多芯片级联,方便完成各种规模的 AI 计算硬件组合。
JF3010 AI 芯片能通过 MDK 适配通用 AI 算法,同时捷飞也自研调试了专用 AI 算法。
GNET 方案目前包含三大类自研算法
结合捷飞科芯特有的 AI 芯片架构,捷飞科芯同时推出了一套 GNET 自研算法,将完美的实现算法与芯片的融合,充分发挥硬件本身的计算能力,大幅提升 AI 芯片计算单元的执行效率,“最大算力”将不再是个空洞的指标,而是给用户实实在在的体验。捷飞科芯 GNet 方案目前已正式发布了分类(Classification)、检测(Detection)、分割(Segmentation)三大算法。
通过 TensFlow、Caffe、PyTorch 等平台,进行通用模型的量化,结合捷飞芯片进行加速运算。
捷飞科芯的 AI 芯片将凭借自身低时延、低成本、超节能的特点,以及完善的软硬件解决方案和技术支撑,将帮助各类智能硬件、智能家电、传统行业、中小企业完成 AI 应用的定制开发。
具体的应用可以参考视频的 demo 演示。

捷飞科芯的 AI 协处理器芯片功耗低、速度快,对于主处理器的 CPU 占用少,不管原 CPU 处理能力高低,都可帮助各类智能硬件厂家在不改变原有产品软硬件架构的基础上,快速的部署 AI 应用,让老产品在 AI 赋能中换发新生命。因此,你只需专注于你的产品和应用,把 AI 加速的事交给捷飞!
公司官网:www.jetflai.com
来源: 与非网,作者: 曹顺程,原文链接: https://www.eefocus.com/video/476276.html










