


 4624
4624
架构就像是芯片的基因,它直接决定了芯片的提升空间。这也是后摩尔定律时代,“新物种”芯片崛起的根本原因。
大量的数据、有效的算法以及足够的算力结合,推动了人工智能的高速发展。但我们也不得不看清一个严峻的现实:数据量越来越大,数据类型越来越多;各种算法日新月异,高速发展;与此同时,算力的提升却显得赶不上趟,甚至落后于数据和算法的需求,特别是在计算场景对高带宽、低功耗需求持续走高的趋势下。此外,加之芯片工艺趋近极限,可大规模商用的新型材料暂时还没实现,在芯片架构上的探索成为提高芯片性能最重要的手段之一。
AI芯片的破“墙”运动
在传统的冯·诺依曼架构中,由于计算与存储分离,计算过程中需要不断通过总线交换数据,将数据从内存读进CPU,计算完成后再写回存储。而随着深度学习的发展和应用,计算单元和存储单元之间的数据移动尤为频繁,数据搬运慢、搬运能耗大等问题成为了算力效能进一步提升的关键瓶颈。从处理单元外的存储器提取数据,搬运时间往往是运算时间的成百上千倍,公开数据显示,整个过程的无用能耗约在60%-90%之间。
特别是大算力场景下,存算分离带来的计算带宽问题成为主要瓶颈。以智能驾驶等边缘端高并发计算场景来看,它们除了对算力需求高之外,对芯片的功耗和散热也有很高的要求。而常规架构的芯片设计中,内存系统的性能提升速度已经大幅落后于处理器的性能提升速度,有限的内存带宽无法保证数据高速传输,无法满足高级别的计算需求。
行业面临的挑战很突出,一边是需要逾越的“算力高墙”,一边则是固守多年的“存储墙”。而只有创新架构,打破存储墙、降低成本、提升计算效率,才能让芯片算力更进一步,推进数据计算应用的发展。
在这一趋势下,将内存和计算更紧密地结合在一起的存算一体方案,正获得越来越多的关注,并逐步由研究走入商用场景中。
以数据为核心的AI芯片路线
对于大算力的AI芯片来说,架构设计已经越来越明显地转向了“数据为核心”的思路,不过对于不同技术路线的企业来说,有不同的实现方式。
HBM是目前超大算力芯片常用的方案之一,它能够暂时缓解“存储墙”的困扰,但实现成本较高。以英伟达在AI云端市场大规模落地的GPU来看,其最先进的Hopper架构一方面通过HBM来解决内存墙,另一方面新增了张量存储加速器 (TMA) 。整个Hopper架构GPU由8个图形处理集群(GPC)“拼接”组成,核心两侧是HBM3显存,拥有5120 Bit的位宽。此外,TMA提高了张量核心与全局存储和共享存储的数据交换效率。
这一方式也需要先进的工艺和封装技术,基于Hopper的最新一代GPU H100,就采用了台积电4nm工艺、CoWoS 2.5D封装技术,在设计能力、成本投入方面都有很高门槛。
再看三星发布的HBM2-PIM技术和近内存计算方案AxDIMM。HBM2-PIM实际上是一块带有计算功能且在AI应用中能提升系统性能的内存芯片,AxDIMM则实现了在每个DRAM芯片旁边都集成了一块单独的加速器逻辑并可以同时访问,增加了访存带宽。这样的设计思路也非常符合三星的业务规划,用以确保其存储器在AI时代继续保持先进性。
英特尔的神经拟态计算芯片Loihi也采用了存算一体的架构,使之更加容易扩展。Loihi芯片的裸片包含128个小核,每个核里面模拟1024个神经元的计算结构,每个神经元又有1000个突触连接,这意味着768个芯片连接起来可以构建接近1亿神经元的系统。
存算一体,方兴未艾
近年来,国内企业对于存算一体芯片的投入进入高峰期。
据<与非网>分析,国产存算一体芯片主要呈现以下趋势:进入2017年以来,国产存算一体芯片企业开始“扎堆”入场,12家企业中有10家成立于2017年之后;第二,从技术路线来看,以近存计算和存内计算两种路线为主,其中,又可以细分为模拟存内计算、全数字存内计算、类脑存内计算、类脑近存计算等;第三,存储器类型相对多样化,包括闪存、SRAM、RRAM、ReRAM等;第四,国产存算一体芯片正在向大算力的方向迈进,以2020年成立的亿铸科技和后摩智能为代表。
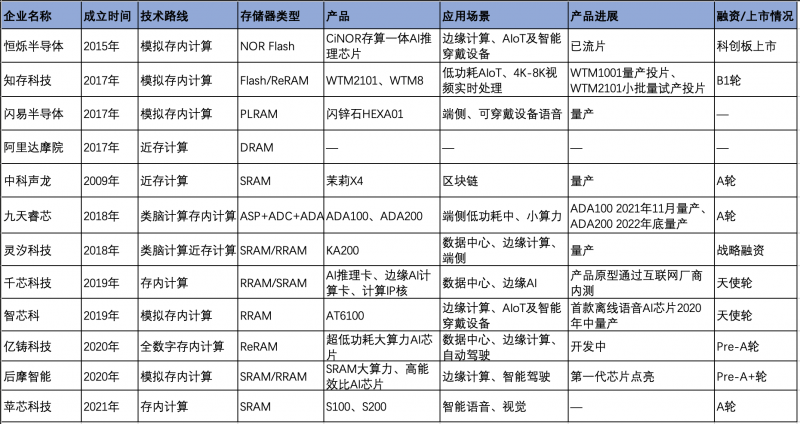
国产存算一体芯片概况,<与非网>不完全整理
技术路线的选择直接决定了产品的应用方向。近存计算的基本做法是将数据存储尽量靠近计算单元,降低数据搬运的延迟和功耗,其架构主要包括多级缓存架构和高密度片上存储;而存内计算是对内部存储中添加计算逻辑,直接在内部存储执行数据计算,这种架构数据传输路径最短,同时能满足大模型的计算精度要求。
在存储器的选择方面,发展较为成熟的有NOR Flash、SRAM、DRAM等。FLASH属于非易失性存储介质,具有低成本、高可靠性优势,但工艺制程有瓶颈;SRAM在速度方面有优势,但容量密度小,价格高,在大阵列运算的同时保证运算精度具有挑战;DRAM成本低、容量大,但是速度慢,且需要电力不断刷新。存算一体新型存储器有PCRAM、MRAM、ReRAM等,其中ReRAM在神经网络计算中具有优势,是目前发展较快的新型存储器。
此外,还有模拟存算和全数字存算的区分。究竟是数字好还是模拟好?前几年,业界认为模拟计算在速度、能耗、工艺节点方面有优势;近些年,又提出模拟路线需要进行模数转换,精度容易受信噪比影响达到上限,而数字计算具有高精度、高环境容忍度的优点。不过,不论是模拟还是数字,都需要企业基于已有技术能力,面向应用场景、可选择工艺等方面进行权衡选择。
谁将胜出?
面向国际巨头在AI算力市场、存储技术占据领先地位的当下,以电路/架构设计出身的存算一体初创公司,将竞争核心着眼于存算一体SoC芯片设计以及相应的IP核能力,是一种较为务实的做法。并且,差异化的技术路线演进,长远看也有利于产业的良性发展。
目前看来,整个行业对存算一体芯片的研究依旧处于探索阶段,在工艺成熟度、典型应用、生态系统等方面亟待进一步成熟,谈论哪种架构胜出为时尚早。并且,存算一体芯片发展本身就涉及庞杂的产业链环节,需要从存储器到AI芯片再到编译器和算法的一系列技术能力,也离不开强大的开发能力和生态建设能力。
写在最后
多年从事芯片开发的工程师,到后来可能发现,很多时候算力的提升并不在于计算单元本身,而是传输带宽的制约。对于这一多年来就存在的瓶颈,存算一体无疑是合理的路径,也因深度学习的兴盛而达到了合适的发展节点。
目前看来,第一批实现量产落地的存算一体芯片,以小算力、端侧应用居多,面向大算力数据中心、智能驾驶的芯片,根据主要玩家的市场规划,有望在未来一两年内实现量产。
在人工智能本身仍在探寻应用场景的前提下,存算一体化的落地问题,仍需要紧密结合具体应用场景具体分析。存算一体芯片产业真正走向成熟还需要持续地积累,实现小算力场景持续渗透,针对高价值场景做极致优化;大算力场景规模量产,最终走向普遍应用。





.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
-1.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)


 [下载]LAT1482 STM32G0单线串口通信帧错误问题解析
[下载]LAT1482 STM32G0单线串口通信帧错误问题解析
