


 10.9万
10.9万
FPU(Floating-Point Unit)
浮点运算单元是处理器内部用于执行浮点数计算的逻辑部件。因为并不是所有的处理器都需要具备该功能,所以一些处理器实现的时候可以配置为包含或不包含该部件。
如果处理器包含了该运算部件那么表现形式就取决于ARM架构的定义, 要么是作为处理器架构里面定义好的一部分,要么是作为处理器基础架构之外的扩展。浮点运算部件除了满足IEEE754标准,另外也会定义相关的FPU工作方式以及相对应的指令集。即便处理器里面并没有包含FPU单元,也仍然可以使用软件的方式来执行相关的浮点计算,但是使用软件完成这些运算跟使用硬件FPU相比会慢许多。
不同的浮点运算单元支持不同大小的浮点数据类型,所以对于一些处理器来说可以配置为仅支持单精度浮点数或者是单、双精度浮点数均支持。
VFP(Vector Floating Point)
“VFP”表示的是向量浮点运算单元,并且也是在ARMv8架构之前已经出现了的浮点运算扩展单元的名称。ARM架构默认并不支持向量浮点运算运算,因此相关的定义与实现都是通过架构的VFP扩展提供的。
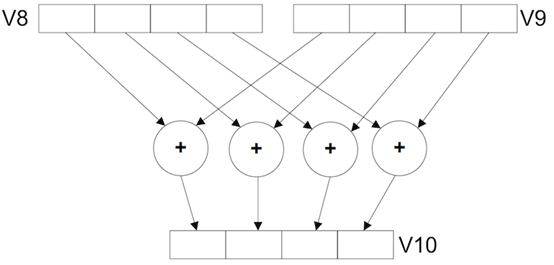
之所以称为“向量”浮点是因为在ARMv6及以前这个扩展不只是用于增加浮点数计算处理,同时也用于类似向量的SIMD浮点数计算处理。在本文中,“向量”用于表示对打包成单个大数据集的一项乘法运算(例如把多个独立的数值合并存储到一个寄存器内相乘)。
在ARMv7架构中,这种使用VFP来处理向量浮点数据的方式不建议采用,相关的功能可以使用“先进SIMD扩展”来替代。
VFP有多个不同的版本 (VFPv1, VFPv2, VFPv3, VFPv4)用来支持不同的特性与数据类型。VFPv2用于ARMv5和ARMv6架构扩展,VFPv3与VFPv4用于ARMv7架构扩展使用。
ASE(Advanced SIMD Extension)
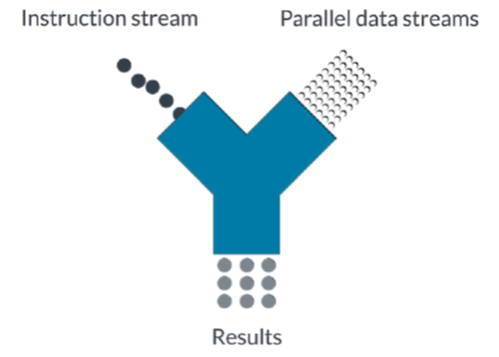
“ASE”是“先进SIMD扩展”的英文首字母缩写。它是ARMv7架构上用于提供额外SIMD运算的扩展,既可以使用整数(即INT整型),也可以使用浮点数。
同VFP扩展相似,先进SIMD扩展也有多个版本(Advanced SIMDv1、半精度Advanced SIMD以及Advanced SIMDv2)用来支持不同的特性与数据类型。
尽管架构上的扩展是“先进SIMD扩展”,但实际用于描述这个特性的产品名为“NEON”。这两个名称代表的是相同的部件。
对于ARMv8A架构中,在默认的架构上包含了对向量SIMD运算的处理所以先进SIMD扩展也不再认为是一种扩展。它仍然作为NEON并且呈现在所有标准的ARMv8-A处理器核心中,因此在某些架构的核心上可能不包括它。.
NEON
如上面简短的提及,“NEON”是用于ARMv7和ARMv8 Cortex-A与Cortex-R处理器的先进SIMD功能的产品名称。
需要注意的是NEON(或ASE)的支持在不同处理器上可能有不同的形式呈现,但基本的功能都是一样的,也就是说,它允许在整数或者浮点数据执行SIMD运算。 所使用的向量大小、向量的数量、所支持的浮点数类型等都取决于其具体的实现。
有关于NEON指令的更多信息可以从这里获得。
MPE
MPE(Media Processing Engine)是一些ARMv7A处理器当中先进SIMD部件使用的名称:Cortex-A5、Cortex-A7以及Cortex-A9。它通常也被称作“NEON MPE”或者“NEON多媒体处理引擎”,它也是处理器实现ASE/NEON支持后的别称。
SVE
SVE(Scalable Vector Extension)如前面所提到的,ARMv8-A架构已经包含了“先进SIMD”支持,用于提供SIMD向量处理能力。SVE是ARMv8-A架构的一种扩展,它表示的是可变向量扩展。
这个扩展只在AArch64模式下支持使用,它提供了额外的寄存器来支持更大向量、额外的指令以及其它的特性。如果要包含SVE则需要处理器核心对NEON提供支持。
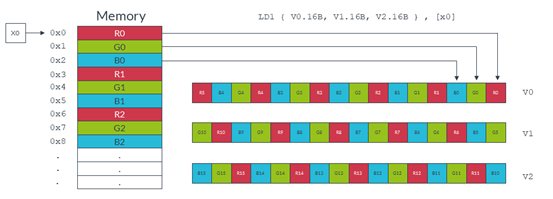
之前支持SIMD运算使用的是固定大小的数据项,比如ARMv7-A先进SIMD使用16个128位的数据项或者32个64位的数据项。而SVE的好处是它拥有的32个向量寄存器可以并成一个2048位的大小,而且向量的大小是可以通过软件来控制的。这也就是为何它叫做“可变”向量扩展—向量的大小可以在运行中调整为不同大小,且这个特性并不随处理器实现而改变。
之前版本的SIMD支持(比如NEON)需要将数据提前处理成处理器实现的向量运算所对应的大小(这类数据通常也称作“已调节”数据)。SVE允许向量数据的大小在运算过程中被改变,无需重写或重新编译代码,使得它更加容易实现那些处理SIMD运算的软件开发。
SVE2是SVE更新后的版本,主要区别在于附加了更多的指令支持。这样就使得它可以在更宽的应用范围加速更多的算法。
有关于SVE指令的更多信息可以从这里获得,类似的SVE2指令的更多信息可以从这里获得。
SME
SME(Scalable Matrix Extension)是ARMv9-A架构提供的建立在可变向量扩展(SVE和SVE2)上增加了对矩阵处理支持。它包含了一定数量的新指令,相当于处理器的新模式—这个模式用于执行矩阵运算,并且这也使得它在处理矩阵运算以及常规的SVE SIMD运算时更容易使用不同的向量大小。
有关SME指令的更多信息可以从这里获得。
MVE
MVE(M-profile Vector Extension)是ARMv8-M架构专用的,它提供了大量对SIMD运算的支持。跟NEON作为A-系列先进SIMD扩展的产品名字一样,“Helium”则是M-profile Vector Extension的产品名称。
MVE可以分为2大类,MVE-I和MVE-F。MVE-I仅对整型向量提供支持,MVE-F则对浮点数据向量提供支持。要包含MVE-F那么处理器核心就需要支持MVE-I以及浮点扩展。
有关MVE指令的更多信息可以从这里获得。

 下载ECAD模型
下载ECAD模型







.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
 [课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
[课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
