


















 1173
1173
如果说AI赋予了各行各业更为广阔的想象空间,则加速计算正在强力支撑着这些想象的实现。
英伟达CEO黄仁勋在今年4月的GTC大会上曾谈到,AI 正在各个领域“全面开花”,包括新的架构、新的学习策略、规模更大、性能更强的模型、新的科学领域、新的应用、新的行业等,所有这些领域都在发展。他指出,正是得益于加速计算,AI领域才不断出现这些“惊人的进展”。
日前,在超级计算专家齐聚的年度盛会ISC上,就展示了加速计算帮助研究者应对重大挑战的繁荣景象。研究者们致力于构建模拟新能源的数字孪生,或者通过使用AI和高性能计算(HPC)深入探索人类的大脑。
英伟达加速计算业务副总裁Ian Buck在演讲中表示,一些公司甚至正在使用高敏感度仪器将HPC推向边缘或在混合量子系统上加速模拟。
先进芯片助推超算迈入百亿亿次AI运算时代
在超级计算机迈入百亿亿次AI运算时代的过程中,先进的处理器芯片也在向更先进架构、更高性能冲刺,异构芯片和异构系统架构将越来越成为主流方向,为计算密集型工作负载提速。
英伟达的Grace CPU 超级芯片搭载了两个基于Arm的CPU,它们通过高带宽、低延迟、低功耗的 NVIDIA NVLink-C2C 互连技术连接。这项开创性的设计内置多达144个高性能 Arm Neoverse 核心,并且带有可伸缩矢量扩展和 1 TB/s 的内存子系统。
Grace CPU 超级芯片支持最新的PCIe Gen5协议,可实现与GPU之间的高性能连接,同时还能连接 NVIDIA ConnectX-7智能网卡以及NVIDIA BlueField-3 DPU,以保障 HPC 及 AI 工作负载安全。
Grace Hopper超级芯片则在一个集成模块中通过 NVLink-C2C连接NVIDIA Hopper GPU 与 NVIDIA Grace CPU,满足HPC和超大规模 AI 应用需求。
尽管这两款芯片在2023年上半年才正式上市,但美国和欧洲领先的超级计算中心都率先宣布将采用这两款超级芯片。
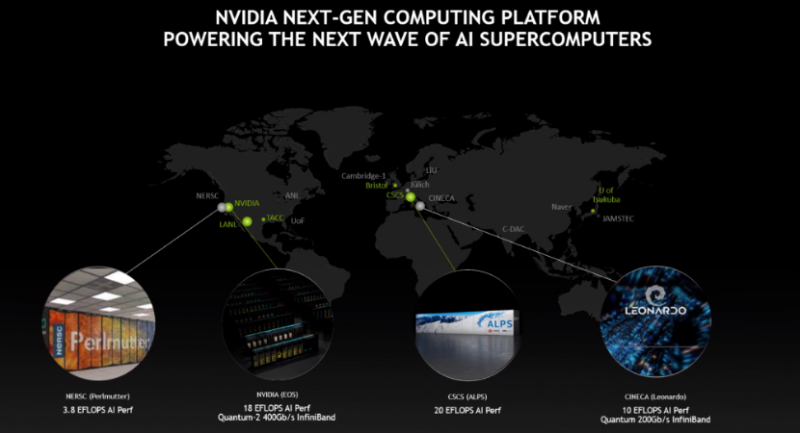
洛斯阿拉莫斯国家实验室(LANL)的新一代系统 Venado 将成为美国首个采用 NVIDIA Grace CPU 技术的系统。Venado 是使用 HPE Cray EX 超级计算机构建而成的异构系统,同时将配备Grace CPU超级芯片节点和Grace Hopper超级芯片节点,满足各类新兴应用需求。该系统建成后的AI性能预计将超过 10 ExaFlops。
瑞士国家计算中心的新系统 Alps由慧与基于HPE Cray EX超级计算机而构建。该系统将使用 Grace CPU 超级芯片,以支持众多领域的开创性研究。Alps 将作为一个通用系统,向瑞士及其他国家的研究者开放。
在欧洲,英伟达和 SiPearl 正在一起扩大在Arm上构建百亿亿次级计算的开发者生态系统。这项工作将帮助该地区的用户将应用移植到使用SiPearl的Rhea,以及未来基于Arm的CPU和英伟达加速计算和网络技术的系统上。
日本筑波大学的计算科学中心正在英伟达的Quantum-2 InfiniBand平台上将H100 Tensor Core GPU 和 x86 CPU 搭配使用。这台新的超级计算机将处理气候学、天体物理学、大数据、AI 等方面的工作。
DPU为未来庞大网络计算规模夯实基础
应对未来海量数据爆发和复杂计算难题的指数级增长,需要将计算移动到接近数据的位置,这是业界公认的以数据为中心的体系结构下的创新,也是英伟达数据处理器(DPU)的提出背景。
为了在现有x86体系中CPU内存和PCIe带宽基础上,进一步提升整体系统性能。英伟达推出了专为TB级加速计算而设计的Grace CPU,以及专为现代超大规模云技术基础架构而生的DPU。至此,英伟达的数据中心路线图焕然新生,由CPU、GPU、DPU形成三大算力支柱。
目前,DPU在网络性能提升方面的价值已经被许多前沿研究领域所认可。洛斯阿拉莫斯国家实验室(LANL)的杰出高级科学家Steve Poole预计,使用在英伟达Quantum InfiniBand 网络上运行的DPU等加速计算可取得巨大的性能提升。
LANL的加速闪存盒(ABoF)将固态存储与DPU和InfiniBand加速器相结合,可为Linux文件系统的关键性能部分提供加速。它的性能高达同类存储系统的30倍,并将成为LANL基础架构中的关键组件。ABoF 使“取得更多科学发现成为可能。让计算靠近存储可更大限度减少数据移动,提高仿真和数据分析工作流程的效率”,LANL 研究人员 Dominic Manno 在最近的LANL博客中这样表示。
在欧洲和美国,一些 HPC 开发者正在开发将通信和计算作业卸载到 DPU 的方法,通过借助BlueField-2 DPU内的Arm核和加速器的强大功能为超级计算机提供强力支持。
德克萨斯高级计算中心(TACC)近期也开始在 Dell PowerEdge 服务器中采用 BlueField-2 DPU。它将在 InfiniBand 网络上,使其Lonestar6系统成为云原生超级计算的开发平台。
在距 TACC 东北部 1200 英里的地方, 俄亥俄州立大学的研究人员展示了 DPU 如何将一个 HPC 热门编程模型的运行速度提高 21%。他们通过卸载消息传递接口(MPI)的关键部分,加速了P3DFFT,这是一个用于众多大规模HPC仿真的数学库。
此外,在剑桥大学、伦敦大学学院、慕尼黑工业大学、达勒姆大学、佐治亚理工学院等,都在使用BlueField DPU加速相关研究。
混合量子/HPC数据中心之路开启
量子计算一直被寄予厚望,用以解决当今面临的一些严峻挑战,通过在HPC中发挥巨大作用,推动从药物研发到天气预报等各项工作的发展。随着量子系统的发展,下一个重大飞跃是朝混合系统迈进:量子计算机和经典计算机协同工作。
研究人员都希望这些系统级量子处理器(即QPU)成为功能强大的新型加速器。因此,摆在面前的一个重要任务就是将传统系统和量子系统桥接到混合量子计算机中。这项任务主要包括两部分:
首先,需要在GPU和QPU之间建立快速、低延迟的连接。这样一来,混合系统可使用 GPU 完成其擅长的传统作业,例如电路优化、校正和纠错。
GPU 可以缩短这些步骤的执行时间,并大幅降低经典计算机和量子计算机之间的通信延迟,而这是当今混合量子作业面临的主要瓶颈。
其次,该行业需要一个统一的编程模型,其中包含高效易用的工具,目前在 HPC 和 AI 方面的进展,已经展示了固态软件栈的价值。
为了对QPU进行编程,研究人员只能使用相当于低级组装代码的量子,非量子计算专家的科学家无法使用这种代码。此外,开发者缺乏统一的编程模型和编译器工具链,因此无法在任何 QPU 上运行工作。
为了高效地找到量子计算机加速工作的方法,科学家需要轻松地将其 HPC 应用的一部分先移植到模拟版 QPU,然后再移植到真正的 QPU。这个过程需要一个编译器,使科学家们能够以熟悉的方式高效工作。
英伟达的cuQuantum软件开发套件可以在GPU上加速量子电路模拟,目前已获得数十家量子组织的采用。最近,AWS 也宣布在其 Braket 服务中提供 cuQuantum。它还在 Braket 上展示了cuQuantum 如何在量子机器学习工作负载上实现高达 900 倍的加速。
目前,cuQuantum 已经能够在主要的量子软件框架上实现加速计算,包括 Google 的 qsim、IBM的Qiskit Aer、Xanadu的PennyLane 和 Classiq 的 Quantum Algorithm Design 平台。这意味着这些框架的用户可以访问GPU加速,而无需再进行任何编码。
未来的混合量子计算之路任重而道远,虽然能够运行先进算法的量子计算硬件仍处于开发阶段,但 NVIDIA cuQuantum 等经典计算工具对推进量子算法的开发至关重要。通过将 GPU加速的模拟工具、编程模型和编译器工具链结合,可以帮助HPC 研究人员进一步向混合量子数据中心的构建进发。
加速 AI 在医疗健康领域的应用
在前沿医学领域,AI+HPC也正在为科学和研究界做出更大贡献。医疗健康领域的数据匮乏一直是制约行业进一步提升的瓶颈之一,将AI引入该领域,正在从一定程度上纾解这些难题。
基于英伟达的Cambridge-1 超级计算机和 MONAI(一种用于医学影像的 AI 框架),伦敦国王学院的研究人员打造了全球最大的开源合成大脑图像集。这位伦敦国王学院的研究人员兼伦敦 AI 中心的 CTO 为医疗健康研究人员免费提供了 10 万张合成大脑图像。这是一个宝库,可以加速人类对痴呆症、帕金森症或各类脑部疾病的认知。
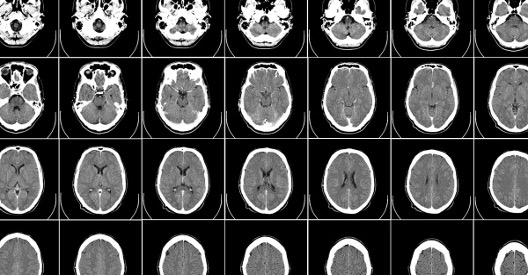
这些图像代表了合成数据在医疗健康领域的一个新兴分支。合成图像此前已经广泛应用于消费者和商业应用的计算机视觉领域,而实际上这些领域本身已有包含数百万张真实图像的开放数据集可供使用。
相比之下,医学领域可供使用的真实影像反而稀缺。出于保护患者隐私的需要,医学影像通常仅供与大型医院相关的研究人员使用。即便如此,这些影像往往也只能反映医院所服务的人群,而非范围更广的人群。
Cardoso 的 AI 方法的重要特征是,它可以根据需要制作图像。女性大脑、男性大脑、老年人的大脑、年轻人的大脑等等,只需插入所需内容,系统就会进行创建。
虽然这些图像是模拟生成的,但非常实用,因为它们基于经过良好测试的算法,所以外观和运作方式与真实大脑高度相似。
这一重大突破表明,HPC+AI的组合正在为科学和研究界做出真正的贡献。
写在最后
数字经济时代,算力已成为支撑各领域发展与转型的重要基石,在许多科研应用以及商业场景中已不可或缺。以往在气候科学、能源研究、太空探索、数字生物学、量子计算等领域遥不可及的巨大挑战,如今有了先进超算平台和AI平台提供的强大基础架构,正在解决这些重大的时代挑战。
同时,高性能计算的飞速发展与应用普及,正在为更多领域带来了巨大的动能。值得关注的是,HPC工作也在越来越多地延伸到超级计算机中心之外的范畴。为了将超级计算带到边缘,英伟达在开发用于HPC的Holoscan,它是图像软件的高度可扩展版本,将在Jetson AGX模块和设备、四路 A100 服务器等各种加速平台上运行。
随着高性能计算向各个方向的扩展,不论是超级计算中心、云端还是边缘等,一切正在发生巨变。而英伟达围绕加速计算展开的一系列软硬件创新和生态合作,也展现了它在高性能计算领域深耕的实力与决心。

 下载ECAD模型
下载ECAD模型



.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
