


















 1256
1256
作者:杜奕宁
今天布置了这学期信号与系统的小论文作业。有参加了上海中学生的科技节作品评选。他们的一篇关于声音与年龄的论文让我很感兴趣。不知道这学期我的信号与系统班上的同学提交的小论文能否赶上这位中学生研究论文的内容。
01 引 言
1.1 项目由来
我对音乐很感兴趣,所以,我在寻找课题时,最初的想法也落在了“声音”上。我了解到谐波分析可以提取声音特征,于是在经过几次尝试、调整后,我选择以年龄为变量分析人的声音。
对于“谐波”的好奇,源于一个声音的实验:用湿润手指摩擦装水高脚杯发出的440 Hz以及国际基准音中央A(440 Hz),它们的声音是完全不一样的。前者声音刺耳且古怪,但后者却完全处于我们的舒适的认知范围内。这个例子也说明谐波对人听觉所带来的影响不可忽视,是很值得去探究的。
所以最后的题目就定为:“基于频谱分析探究人的声音随年龄的变化”。
1.2 文献综述
通过对于“声带”、“年龄”等关键词的内容模糊搜索,我在许多生物学、医学的期刊或论文里进一步了解了人的发声机制。通过对于“谐波”、“频谱”等关键词的搜索,我看到了较多有关于声音的特征提取以及谐波对于声音的影响。这两部分各自的检索结果都比较多。相对而言,二者相结合的研究就非常少了。
尹基德的汉语韵律嗓音发声研究便是一例,他将声带发声机制以及声音的基音、谐波结合在一起考虑,重点把不同的汉语发音作为变量。虽然此研究与汉语发音并无关系,但是是为数不多的涉及到发声机制以及谐波特征的综合研究。
1.2.1 声带发声原理
声带位于人类的喉部,是一个发声器官,主要是由甲状软骨、杓状软骨、环状软骨、环甲肌、真声带(声襞)、假声带(前庭襞)等部分组成。
覃折波等人利用超声成像,解析正常人声带区的发声原理。在研究中他们提到:“声襞本身构成了声门的一部分,其游离的内侧缘所形成的开口即为声门裂,声门裂是喉腔最狭窄的部位。在喉内肌协调作用的支配下,声襞运动使声门裂有规律的开放和闭合,从气管和肺冲出的气流不断冲击声带,引起振动而发声。”同时他们在分析数据时也指出了随着年龄增长发声器官的老化现象:“这与甲状软骨随着年龄增加钙化逐渐严重的生理特点相符,而声像图上显示因甲状软骨严重钙化致影遮挡也证实了这点。”
▲ 图1.2.1 声带结构示意图
在尹基德汉语韵律的嗓音发声的研究中,他从三个调节方面来论述了汉语韵律的发音方式:音调调节、时长调节以及强度调节。在音调调节方面,作者提出,最重要的便是环甲肌与声带肌。如上图1所示,环甲肌通过拉扯甲状软骨来调节真声带的张力,从而改变声带肌的硬度与有效质量以调节音调。另外,文中提到真声与假声的发声原理是不同的,“从正常嗓音发声转变为假声时,环甲肌的变化不明显而声带肌的电信号明显下降。”1注意到这一点,本项目的声音样本全部采用的是真声。
另外,日本耳科会报的一篇文章提出:声带肌截面积变化、声带肌纤维数的变化、肌纤维类型的变化、脂褐质沉积率四个方面是声带老化的重要指标。
通过这些文献的查阅,我认为,人的声音会随着年龄的增加而有一定的变化,而如何对其进行测量,并找到其中的关联性,则是我的研究重点。
1.2.2 谐波的研究概述
“谐波”在许多有关声音文章中都被作为了一个关键数据去看待,因为“谐波”确实是与我们平时所说的“音色”是分不开的。
张雪源在其研究中提到,人在听到一个具有谐波结构的声音时,不会依次感知到每一个单一泛音的频率,而是将信号整体感知为基频频率,而将泛音的个数、能量大小、泛音能量衰减速率等感知为音色 。黄天乾等人通过分析钢琴比较特殊的七次谐波、九次谐波来研究其音质5;张雪源则分析得出:小提琴因其泛音多且能量衰减慢、黑管因其泛音少而能量衰减快,所以前者声音明亮而后者较为低沉(张雪源)4;杨婧基于谐波的特征对于不同乐器进行音色特征提取6……这些都反应了谐波作为一个声音特征的重要地位。所以,在对声音进行定量分析的过程中,谐波的研究有其重要的意义。
1.3 研究意义
在除了纯粹的科学探究以外,本实验还可能为其它切实的领域提供帮助:
1. 在此基础上进一步了解声音衰老的机制,帮助提出修复方法
2. 进一步扩大数据,可以提取特定年龄的特定声音特征,可用于身份识别等领域。
1.4 创新点
本人认为,该研究的创新点主要有以下两点:
1. 通过对人的声音的谐波分析,在前人定性声带衰老的基础上,为定量研究人的声带衰老提供可能。
2. 通过对频谱特征的提取让声音在数据层面上与年龄相关联,并辅助其推测。
02 原 理
▲ 图2.1 谐波示意图
如上图2谐波原理图所示:黑色直线是弦,蓝线、黄线、绿线都是这根弦的振动方式,分别代表着二次谐波、三次谐波、四次谐波……以此类推,但一般而言越往后的能量就越微弱。可以很容易知道:波长λ乘以谐波次数n就等于半条弦的长度,同时:一秒钟速度u = 一秒内波的频数f每一段波的长度λ。所以得到: 。把第二个式子带入第一个式子, 。
如果假设弦长一定,且弦各部分均匀,那么L与u皆为定值,则f与n成正比。这证明了倍频的频率在理论中应为基频的整数倍。
03 实 验
3.1 实验器材
【表-1 实验器材】
| 使用软件 | 功能 | 使用版本 |
|---|---|---|
| Sigview | 音频分析软件 | Sigview v5.0 |
| Adobe Audition CC | 音频截取软件 | Adobe Audition CC20 |
| OriginPro | 图表制作软件 | OriginPro9.1 64-bit |
3.2 音频采集
本文的研究方向在于一个人的声音特征随年龄变化的改变。因为很难短时间做到跟踪一个人几十年的声音,所以实验的音频来源采用了李谷一几乎每年春晚都演唱的《难忘今宵》。并且采用《难忘今宵》也有另一原因:歌唱与讲话不同,歌唱可以确定一个相对稳定的音高,有效地为实验控制了变量。如杨婧在其学术论文中所言,乐音信号与语音信号相比更具有明显的谐波特征。
从第一次演唱的1984到最近期的2019,时间跨度为三十五年,除去一些并非李谷一演唱的部分,大概可以留下13份左右的样本,数据较为充足。我两次截取了所有不同年份音频之中的“忘”字以及“宵”字。
伴奏音乐其实是一个实验中非常大的干扰。一开始我粗糙截取了她演唱的整个音,但它们的伴奏往往在后半段掩盖了人声,导致音频价值较低。所以我使用adobe audition较精细地裁剪掉了后边乐声掩盖了人声的部分。
3.3 频谱分析
我将音频导入sigview后,进行了fft分析。如图4所示,蓝色是打开音频时的初始状态,是横轴为时间的图像;红色则是傅里叶变换后输出的频谱。这一步操作完毕以后得到近三十份的频谱便是我的“原始数据”了。
▲ 图3.3.1 1990年“宵”字音频分析
“数据收集”可以说是本实验中遇到的一个挺大的困难,这是与我实验本身的特性相关的。经过fft分析以后得到的数据是原始的、复杂的、凌乱的,所以我在抉择到底采用那些数据作为有效数据时遇到了困难。为了避免混乱,得到一个固定的数据收集方式是非常重要的。下文将简单展示本人在确定数据收集方式时,多方面的分析与考量。
3.3.1 基频数据录入方式
录入基频数据从三方面着手:
1. 假设其为基频,是否能寻找到其对应倍频
2. 是否落在歌曲中该音的范围内(“忘”:392Hz-415Hz,“宵”:440-460Hz)
3. 以上二者任意答案为否的备选峰值直接排除,若仍有多选项,取其y值明显更高的。
若并不存在“明显更大”,则改组数据不参与分析计算,仅作参考。
3.3.2 倍频数据录入方式
倍频数据的录入都是基于一个已经确定的基频之上的,要同时用到“set harmonic marker”、“show 5 highest points”两个sigview的自带功能。第一个是可以选定一个频率以后自动显示出它所有理论倍频的所在位置。“show 5 highest points”同字面意思,会显示出你框定范围内的五个最高点并直接读出此点坐标。
左下图的情况(红圈为理论倍频,蓝色为实际峰值)是容易解决的,直接将理论倍频往最近最高的峰值靠拢即可,但如果遇到右下图这种情况,又该如何?左侧不远处是最高峰,右侧更近一点的地方是次高峰,那么取峰值更大的还是取更近的?实际操作一下就不难发现,取最高峰非常好操作,答案也唯一。反之,如果把“取更近的”作为规则,那么在遇到图5情况时,就得不到答案了。
▲ 图3.3.2 倍频数据录入案例-简单
▲ 图3.3.3 倍频数据录入案例-复杂
图5中,如果按照取最近峰值的原则,4号点应该是首推,但4号点的纵轴数值极小。那在就近的原则下,再取了3号点作为最终数据。但一比对,最高峰1号似乎只比三号点略远非常微弱的一点点,却在纵轴数值上大了一倍,二者便很难取舍了……这种混乱的取值方式是行不通的,因为在选择过程中,只要数据采集者随意地心念一动,最终的取值就会发生翻天覆地的变化,数据也就失去了它应有的价值。
故而,在所有倍频数据的采集过程当中,我都是直接取了候选名单中的最高峰。这样子完全地杜绝了采集标准摇摆不定带来的问题,但这样做同时也可能在实验中留下问题——凭什么最大值就是真正应该选择的倍频呢?理由有二:
第一,在这些候选峰值之中,横坐标的差值是非常小的,往往都在理论值的正负0.1-0.7%的区间内。上图是为了凸显选择数据的纠结所以把图像放得很大,但实际上,往往横坐标只浮动了几赫兹就能让纵坐标翻一倍、甚至三四倍,那么取舍也很分明了。
第二,李谷一她自己唱出的声音并不完美,有多个峰值是正常现象。虽然我记录的n次倍频不能全然代表整段的n次谐波,但它是这一段谐波里最能代表这段谐波的峰值。
故而经过仔细取舍,我最终选择采取“取最高峰”的方式来记录倍频的值。
04 数据分析
我的基础数据来源于两波样本——声源为“忘”字的12份、声源为“宵”字的12份。其中“宵”字样本的质量我观察下来是更高的,所以在之后也会使用的略多一点。
在第二部分“原理”中,已经解释了基频与倍频的关系——倍频频率按理论来说必然是基频频率的整数倍。回顾我们得到理想公式的诸多假设,其中两点实际上并不能完全成立:一.振动的弦长度是一定的。二.弦是各处均匀的。人的声带在振动时长度是一定的吗?人的声带是均匀的吗?正是因为这些假设我们不能保证,所以说会出现各种具有研究意义的误差以及有意思的现象,也能观察到一些规律。
4.1 峰值偏离与是年龄关系
4.1.1 峰值偏移与年龄观察
在理想模型里面,倍频应该是严谨地是基频的整数倍。所以我在最开始时,是非常严格地遵守这一条规则去采集数据的。但是我逐渐发现,恰在x值=基频整数倍的时候,y值并不在峰之上,甚至还有的恰好落在了谷底,那样子的得到的y值数据十分不恰当。所以在实验进程初期个人就有猜测:当把理论体系搬运到实际实验中时,因为种种理想假设失效,会出现一些小误差。得出这个结论以后,我转变了数据的采集方法,也开始深入研究真实峰值与理论峰值的偏离与年龄的关系。
在这个问题中首先要把握住“偏离”这个词汇,也由此延伸出两条不同的道路——分析差值,分析比值。
基础数据中不难发现,在倍频倍数增大的同时,理论峰值与真实峰值横坐标上的差值也在增大。可是这个趋势并不意为着什么,分析差值的大小我个人认为不可取。第一、这个偏离的产生虽然原因不明,但偏离的大小是很可能与基频取值相关的,表中可见每年的基频都有变化,未经过归一化就去分析相当于忽视了基频取值这一变量,让基频不同的年份无法统一分析。第二、在倍频被得出的过程中,牵涉到的变量仅仅有“基频”与“倍频是乘以几”这两项,所以在同一年中基频固定时,造成这个偏离的只能是来源于“真实乘上去的数”与“理论上应乘上去的数”不一样。倍频是一个经过乘法(而不是加减)得到的数据,所以该分析是真实测出的倍频与整数倍倍频的比值(而不是差值)。
所以我放弃了对于数据散乱的差值的分析,转入对于比值的分析。在此部分中,新的问题又涌现出来,这也是我至今并未给出确定答案的——如何用几个已知的变量去定义这个偏离?我在尝试中从三种思路提出了三种效果不同但各有道理的方案:
令基频=b,谐波次数=n,真实频率=t,abs()为取绝对值函数,理论频率=b · n
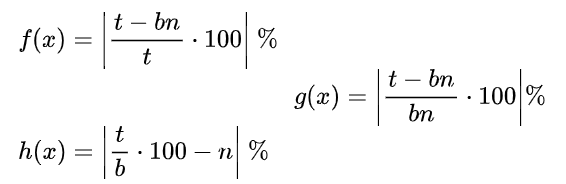
三个方案的数据意义是不同的。第一个反应的是真实与理论的差值以真实频率值为参考的偏离率;第二个反应的是真实与理论的差值以理论值为参考的偏离率;第三个反应的则是基频与倍频的直接运算关系,即基频*(h(x)+n)=倍频。在三者都各自有其不可替代的意义的情况下,我把三种分析方式的结果都罗列了出来。另外,为了对于每一年的总体偏离状况有一个总体的了解,我把2-8次谐波的偏离率全部相加,得到了total一栏。此处以“宵”字为例,计算得三张表格:
| 年份 | f(x) total | g(x) total | h(x) total |
|---|---|---|---|
| 2019 | 0.037030 | 0.036831 | 0.153925 |
| 2018 | 0.040015 | 0.040001 | 0.187327 |
| 2017 | 0.014949 | 0.014903 | 0.061542 |
| 2016 | 0.035468 | 0.035663 | 0.120753 |
| 2015 | 0.040381 | 0.040372 | 0.172545 |
| 2014 | 0.045170 | 0.045437 | 0.204236 |
| 2013 | 0.051366 | 0.051117 | 0.247460 |
| 2011 | 0.045015 | 0.045084 | 0.265867 |
| 1996 | 0.025946 | 0.025933 | 0.108896 |
| 1992 | 0.019542 | 0.019492 | 0.091860 |
| 1990 | 0.032161 | 0.032152 | 0.145650 |
| 1984 | 0.032722 | 0.032963 | 0.132432 |
(注:在求和时考虑到有些年份观察不到某些次数的谐波,所以在计算时引入变量k,表示有k个谐波是观测不到的。因为观测不到谐波并不能够证明偏离是没有的,所以为公平起见,total这个量在通加的基础上进行覆盖:
total=total·7/(7-k)。)
三者虽然不尽相同,但三个公式得出的值的大趋势是一样的。根据数据制作的相应变化趋势图如下图所示:
▲ 图4.1.1 年份与偏离率相关趋势图
1997-2010年间,因为李谷一并未演唱,所以数据缺失,这是本实验的一个遗憾。根据先前他人的研究,一个字的发音方式不同也会对于这个实验带来影响1,并且也不好确定不同歌里面的音调是否一致,所以缺失年份数据很难补充。
回到这三张图,可以看到他们大趋势一致:其偏离率都随着演唱者年龄的增大而增大。这个趋势作为结论不够严谨,因为仍然能看到年龄增大、偏离却减小的许多例子。本人认为这与基音可能有关,此问题将在下一部分中解释。
4.1.2 峰值偏移、基频频率与年龄关系
随着李谷一年龄的增长,她歌唱的基音是在下降的。比如“忘”字:(为了让这个下降表现得更加直观,它的频率的数值统一被减去了385 Hz)。又如“宵”字,仍然是明显的下降趋势。随着演唱者年龄的增大,她有意或无意地降低了基音的高度。纵观1984-2019的35年,在两个音的演唱中都大约下降了20-25 Hz,不过仍然还处在半音范围内。
▲ 图4.1.2 忘与宵基频下降趋势
年纪增长时基频有所下降并不难理解,相比更有趣的事情是峰值微弱偏离与基频的存在的一种互动。我们把2011-2019年这一段数据密集的内容单独拿出,并把他们n次谐波的x值分别除以n来反应偏移。
▲ 图4.1.3 反映偏离程度的折线图
可以看到在2011年时它的五种颜色的点都很接近,没有较大的偏离且基频教高;2013年,即年龄+2后,几个点的偏移略微增大(这与我4.2.1对于偏离率增大的趋势是吻合的),同时基音下降;2014年基音抬高,让五个点的上下浮动达到了一个峰值,偏离严重;2015年,基音重新降下来以后这个浮动也有缩小;2016年基音再抬升,偏移达到最大值;2017基频下降,偏移缩小;2018年基频没有下降,偏移增大;2019年基频下降,偏移缩小。
就本图中的三个变量:年龄、基音、偏移而言,年龄的增长是客观的,偏移来源于声带的条件,唯独“基音”是一个可以随着演唱者主观意志而改变的。正是因为这种主观意志的影响,所以对于“基音”我们仅把握住一个大趋势即可。同时我们也发现,在年龄增加的过程中,每一次基音的抬高都带来了偏移程度的扩大。做一个总结,基音的升高与年龄的增长都会导致偏移程度的增加,而基音降低可以导致偏移程度降低。
把样本扩大进行进一步分析。本图的扩大体现在两方面:年份添加了1984、1990、1992、1996四份数据,谐波最高次数从上一张的5次提升到了7次。基频为黑色,而2-7次谐波x值除以各自次数分别为红色、绿色、蓝色、淡紫色、黄色、深紫色。
▲ 图4.1.4 反应偏离的折线图全图
在这一张图中,通过图像与数据可以发现,这组数据完全满足结论:1.随着年龄增长,每一次基音的抬高都会导致偏移程度的增大。2.每一次基音的降低都会导致偏移程度的缩小。
第一条结论与第一张小范围的数据分析结论是一致的,而第二条个人认为是属于巧合——基音降低使偏移缩小、年龄增加使偏移增加,两个作用相反的变化同时存在,最后恰巧前者的影响力更大一些。
分两次来制图分析是我认为有必要的。第一,1984-2010年跨越了26年却仅有4份数据,要研究一个连贯的变化不如2011-2019年的数据有效。第二,谐波次数增加以后数据过于复杂,直接上手分析会造成困扰,不过最后发现的规律也得到了验证。
本章承接4.1.1峰值偏移与年龄的初步结论,观察到偏移、基频、年龄三者互动关系的存在,为定量尝试做了事实基础。
4.2 基频倍频与峰值偏移与年龄相关分析
本部分旨在提出基于上文所观察到明显规律的进一步探索的方法。
本部分将围绕“关联函数”(即两个数组协方差比上各自标准差的值)展开。一般而言,两个数组的关联度如果可以达到0.9以上,那么就可以认为是具有较强关联性的。在初步尝试中,本人将各年龄的峰值偏移总和作为数组A,各年龄的基音频率作为数组B,经计算得关联函数等于0.61545。这个数据表明,三个因素在计算关联函数是是必须要同时考虑到的。
为把“年龄”融入到这个关联系数的计算当中,经过思考,我把[峰值偏移+f(相对年龄)]作为数组A,各年龄的基音频率作为数组B进行尝试。相对年龄是我在这里使用的年龄计算方式,即把最早的1984年作为0,1990作为6,1992作为8,以此类推。
现在待确定的是这个f(x)到底是何种关系。因为每一次计算关联系数步骤很复杂,所以我手动计算不是很切实际,因为我要处理的数据量是极大的。鉴此,我用python简单地编程了一个程序来进行计算。我先假设它的影响方式是一次的,设斜率为k,以0.1为步长从0开始增大到100,又以0.1为步长从0开始减小到100。下图是结果展示,k>0时最大值在k=100时取到0.89左右,并仍然具有缓慢上升的趋势,可能在0.90左右存在其渐近线。k<0时,最大值在k=-2时取到,为0.91141。由此,最合理的猜测是数组(峰值偏移-2*相对年龄)与数组f有关。
▲ 图4.2.1 程序输出结果
这个尝试是初步的,具有很大的发展空间。
首先,年龄以正比例形式影响偏离量是我的假设,也有可能是有常数项的一次、二次、三次……在这个方案中,只需要略微改动程序为双层嵌套、三层嵌套也能实现。其次,年龄是使用相对年龄还是李谷一本人的年龄有待考量。这两种算法的结果是不一样的,但这很可能牵涉到生物领域,要了解声带老化过程的起始点等等复杂因素。
希望本尝试对于峰值偏移、年龄、基频之间定量关系的探索有一定意义。
4.3 倍频相对峰值偏移与年龄原因探索
先从基音随年龄增长而下降的趋势说起,因为在此处计算还不涉及到倍频峰值偏移的问题,所以用较理想的公式进行计算。整理一下现有公式:u=λ•f;F=k•f;另外是波在弦中的速度u=根号下T/ρ,其中T 为张力,ρ为线密度。
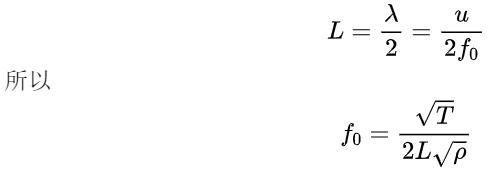

最后得到的式子,抛开定量L与ρ,本质是基频与k、Δx二者变化的关系。粗浅来讲,随着一个人年龄增长的声带肌肉老化松弛,这个系数k会降低,从而也在Δ降不发生改变的情况下使基频f0下降,这也就能成功解释在4.1.2开头提到的现象了。
当然,也很明显这个下降是可以有意识地人为避免的,如果演唱者想要在年龄增大以后仍然保持基频在同一高度,如果仍然对其施加一样的力的话,T一定那么k下降则Δ降增大,结果是分子不变,分母变大,基音下降。想要使f0保持稳定的关键是在于保持下式不变:
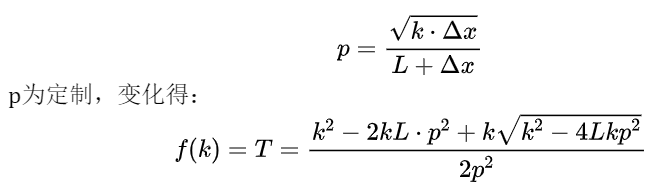
可见为使基频稳定,T随k的减小应当减小,但这个减小的程度便涉及到这个复杂的函数了。所以本部分得出结论:由于肌肉的老化导致的松弛,使k减小从而导致基频下降。演唱者通过有意识地抬高基频可以缓解,并且在这个抬高的过程中肌肉拉力T会减小。
4.4 倍频值岁年龄变化
上一部分是对于峰值x值的研究,而此板块则是对于分析y值数据的尝试。
初始数据因为音源响度、杂音等问题杂乱无章,所以第一步要进行归一化。把每份音频中基频的y值定为1,那么其余峰值的y值也得相应地缩小,汇入下表以后得到的便是比较有意义的数据(数据见附录)。
把它们制图后得到:
▲ 图4.4.1 谐波值与基频比值
▲ 图4.4.2 归一化后的y值
最明显的现象是二次谐波、三次谐波的突出。如果把各年数据进行累加则同时能在二次、三次谐波上面发现这一点。另外,把各个年份的同次谐波的y值进行累加,也可以看到在其宵字中在七次谐波的一个略微上浮。
▲ / 各年份谐波折线图
结合年龄来看,随着李谷一年龄的增大,“宵”字同年各次谐波归一化后y值之和随着年龄增大而减小(如表所示),而“忘”字数据则混乱不堪没有规律,趋势线为水平。结合上一章的分析,我认为导致此结果的原因可能是李谷一随着年龄上升,基频各峰值趋于分散所致。正是这种分散,在我只采取最高峰值的数据收集方法下,很难观察到随年龄变化的结论。这一部分的分析是不成功的。
05 结论与展望
5.1 结论
这里我按照数据分析各板块的顺序来进行结论的总结。
首先是在4.1.1中,通过不同的定量方式来考察“宵”字12份样本中每一次峰值横坐标与理论的偏离程度,并发现随着年龄上升,偏离率在三种定量方式中都处于上升的趋势之中。随后在4.1.2进一步分析,加入基音频率作为第三个变量分析,发现基音的上升和年龄的上升共同会导致偏离程度的加剧。此两章论证了年龄增长会导致这个偏离变大,但同时降低基频可以一定程度上掩盖此问题。
4.1.3是一个对上文三变量定量情况的讨论,目前得出最合理的说法是:数组(峰值偏移-2*相对年龄)与基频关联度最大。这个尝试具有可拓展性,也或许可以为定量表示声带衰老程度提供提示。
最后,在4.2中,我对于每一次峰值的y值进行分析,发现二次、三次谐波显著含能量更大。因为数据采集方式问题导致此板块无法深入分析。如果可以在进一步研究中把图像围成的面积作为新的y值标准,或许会有新的突破。
5.2 展望
一方面,这个项目本身可以被进一步优化。
因为前后此项目并前后用时也未超过一年,我是很难做到自己来做实验样本的。所以就只能在网上去获得实验样本。《难忘今宵》作为一个跨度非常大而且还是同一位演唱者的一份数据在我看来已经是非常好的突破口了。然而它也存在着伴奏音乐、背景噪声、多次录制使音频质量下降(它录一次,我再录一次)等等问题。如果能把这个项目作为一个长期项目(至少……四五年)的话,一定会是对于实验的一个重要优化。
我的对于这个课题所涉及的领域的了解还需要加深。举一个例子,我在确定谐波峰值(见3.2.4)时最终统一采取了最高峰峰值,虽然成功避免了数据的混乱,但这样子是不够严谨的。我想可能是因为我对于谐波的认知不够到位所以才找不到一个更好的方法。
其实做这个项目的过程也是一个我自己去摸索去提高的过程,在我的认知不断地被新知更新的时候,许多原先做的老数据就会暴露出问题。我不断地回过头去刷新老数据实际上花了挺多时间。如果时间允许,我希望可以再多挑几个字出来进行研究来把这个数据量进一步扩大。相信那样能让我发现更多。
另一方面,这个项目在几个点上可以被进一步拓展:
此处引入的仅仅是“年龄”这个单一变量,那么性别呢?是否经过训练呢?歌唱技巧呢?……更多的变量在一个全新的课题里是可以被拓展进去的。
可观测到的最高谐波次数到底与什么有关?这个问题在调查过程中就已经引起了我的好奇了,为什么我第一波样本里一般只能最高到达三次、四次,而第二波里却能达到八次、九次?是时长问题,还是强度问题,还是发音口型问题呢?
是否能将我的结论与生物板块进行更多的结合,而不要只是停留在发声器官老化这一层上?(当然我可以预想到,这个结合是对现在的我还是有一定技术困难的。)
声带老化在生物领域中更多是现象性的,如果本研究足够成熟,本人认为有可能可以作为定量声带衰老程度的一种方式。
音发声研究[D]. 博士学位论文,北京大学,2010 [2]覃折波,何芸,冯玉洁,郭燕丽,华兴. 正常成人声带区解剖结构的超声成像[J]. 临床超声医学杂志 2017,19(1):14-17 [3]铃木徹. 声带肌的衰老变化[J]. 日本耳科会报1982,85(11):1469 [4]张雪源. 面向音频检索的音频特征分析方法研究[D]. 博士学位论文,华南理工大学,2015 [5]黄天乾,谢志文. 钢琴幅度谱的七、九次谐波对钢琴音质影响的研究[J]. 电声基础 2005,4:4-7 [6]杨婧. 基于谐波结构的乐器音色提取方法研究[D]. 硕士学位论文,哈尔比工业大学,2018





.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)



