


 195
195
继续Seeing Machines对DMS商业化落地遇到的挑战的总结。
本节针对DMS系统中常见的三类任务,检验Occula的设计效率。(i) 人脸检测,(ii) 人脸跟踪,(iii) MobileNet(一种常用的NN架构)的推理。
对标方法
如前所述,Occula不是一个普通的NPU,而是与基于NN的算法相匹配(或共同设计)的加速硬件,而这些算法又可以在其上高效运行。因此,重要的是要把Occula看成是一个NPU和一套算法,它们是不可分割的。
因此,为了使效率测试有意义,我们需要将Occula NPU+NN系统与其他潜在的NPU+NN系统进行比较,例如那些Seeing Machines的竞争对手可能开发的系统。
为此,我们在候选的NPU上创建了人脸检测和人脸追踪的对标算法,这些算法很适合这些NPU,我们认为这些算法将代表任何负责在这些设备上实施最先进的DMS软件解决方案的机器学习专家工程师所采取的开发路径。
我们的想法是比较Occula作为一个特定应用的设计所实现的“开箱即用”的效果与在任何其他通用NPU上开发人脸检测和人脸追踪NN的结果。我们认为,这种方法很好地代表了将“与硬件无关”的DMS软件移植到随机SoC上的现实,这也是我们的竞争对手必须做的。
人脸检测任务
在人脸检测方面,我们的对标测试采用了使用TensorFlow的MobileNet SSD-V2,在人脸图像库中进行训练。在撰写本文时,SSD(Single-Shot Detectors)是使用NN进行一般2D物体检测的最先进技术。此外,MobileNet NN架构产生的模型很小,通常用于高性能的嵌入式解决方案。我们认为这种方法是机器学习工程师为DMS解决方案开发人脸检测时最可能选择的方法。SM-DETECT和MobileNet SSD-V2网络都是针对320*320分辨率的图像运行的。
人脸跟踪任务
对于人脸跟踪,我们的对标测试采用了3D“人脸对齐(face alignment)”技术的开源实现,该技术最初在ECCV 2020上提出。这篇论文的题目是“Towards Fast, Accurate and Stable 3D Dense Face Alignment”,追求使用NN技术实现最大效率的快速实时人脸对齐。ECCV的论文和3DFFA_V2 GitHub项目都是由Jianzhu Guo共同撰写的,他是人脸处理领域中被高度引用和尊重的专家。在我们的对标中,我们测量了人脸对齐阶段所花费的时间,这与SM-TRACK在应用于追踪人脸时所做的工作有直接的可比性。每个方法都是在核心算法模型的原始分辨率下执行的,以避免图像缩放影响结果。3DFFA_V2代码在128128分辨率的图像上运行,而SM-DETECT处理1280968分辨率的图像。注意,这使得3DFFA_V2处理的输入像素更少(因此有带宽优势)。
通用的NN推理任务
对于通用的NN推理,同一模型在所有目标设备上执行,包括Occula。网络架构是MobileNet-V3,有一个由8位量化系数组成的10MB模型。任务是使用ImageNet11数据执行简单分类。
目标设备
对于对标测试,我们有意选择(i)通用的NPU设计,(ii)因其低功耗的嵌入式性能而被认为是“最先进的”,但(iii)没有出现在车载产品中。
排除任何出现在汽车SoC中的NPU的原因是Seeing Machines也在开发和提供车载NPU软件,而这些设备的性能与Occula相比是商业上的敏感信息。简而言之,我们不想给我们的任何SoC合作伙伴带来麻烦。
在我们的研究中,我们选择了Google Coral Edge TPU和NVIDIA Xavier NX,因为Google和Nvidia都可以说在高性能通用NPU设计方面处于市场领先地位,而且最近还发布了嵌入式版本。这两款芯片还拥有业界领先的工具链。
功耗测量
Google Coral
Coral TPU是一个纯粹的NPU设备(而不是一个带有CPU和其他子系统的SoC)。Google提供的测试系统使用带有USB Coral TPU加密狗的Raspberry Pi v4进行操作。测量Coral TPU的功耗,只需观察Coral TPU进行处理时与移除Coral TPU加密狗时Raspberry系统功率的差异。
NVIDIA Xavier NX
我们在NVIDIA Xavier NX系统的两个不同的子组件上运行该对标测试,(i)GPU(384核NVIDIA Volta™ GPU,带48个Tensor Core),以及(ii)深度学习加速器(NVDLA引擎),在该系统上获得的功耗测量结果如下:
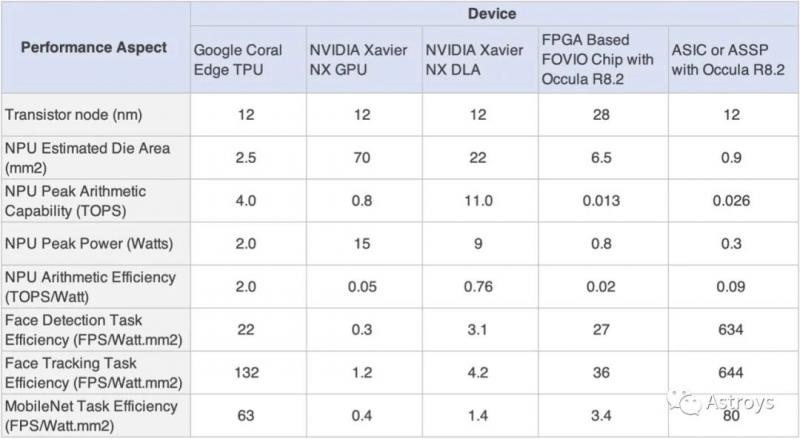
上表通过考虑以下因素来比较设计效率:(i)NPU执行任务的速度(FPS);(ii)NPU执行计算的额外功耗(W);(iii)NPU内核消耗的芯片面积(mm2)。请注意,对于Occula来说,该测试是在FOVIO芯片的环境下进行的,它是一个28nm的FPGA设备,而Google和Nvidia的设备被认为是12nm的部件,因此应该更节能。
最右边的一列是对Occula设计部署在12nm器件中的性能结果的模拟预测,它提供了一个更好的平行的效率比较。这个模型的细节将在下一节讨论。
一个有趣的结果是,在所有三个任务中,Google TPU的性能明显优于Nvidia设备。我们注意到,Google设备显然是为执行量化的NN而优化的,而Nvidia设备则保留了完整的浮点支持。
这些结果揭示了一个众所周知的行业现象,即特定应用的设计通常能够比通用设计(在特定应用领域进行比较时)的性能至少高出一个数量级。事实上,这就是协处理器存在的原因。也许这里更深刻的认识是,虽然NPU本身是远离更多通用的CPU的专业化,但大多数NPU(甚至是嵌入式的)仍然是高度通用的设计,可以被特定应用的协同设计方法所超越。

.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)


.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
