


 498
498
在去年的苹果发布会上,其产品包含iMac全线切到使用苹果自主研发并设计的芯片M1系列,这个系列芯片也代表着苹果放弃x86架构,这一里程碑式性决定。关于其在架构选择方面的详细解读,可以参考之前的文章:
苹果发布M1芯片放弃X86架构
M1 Pro和Max都是去年M1的后续产品,M1是苹果的第一代Mac芯片,它开启了苹果用自己的内部设计取代基于x86芯片的征程。尽管M1速度很快,功耗表现也不错,但它仍然是一个更小的SoC——仍然为iPad Pro系列等设备供电,以及相应的较低的TDP(Thermal Design Power),自然还是输给功能更加强劲地芯片,关于技术细节,在之前的文章中均有提到,这里不再赘述。
那么我们已知评功的M1芯片,于其说是为了制造出一款非常强大的明星产品,不如说是为了其生态链完整产品形态而服务的。那么后续M1基础上更新的动作,则更值得探究。
Apple M1,拥有4个大性能核心、4个高效核心和8-GPU,在一个5nm工艺节点上拥有160亿个晶体管。
而新的M1 Pro: 10核CPU, 16核GPU, 337亿个晶体管。
M1 Pro继续使用定制性的封装,苹果是封装SoC芯片和内存芯片在一个单一的有机PCB, 这与其他传统芯片,如AMD或英特尔的DRAM芯片形成对比,后者的特点是内存插槽或焊接到主板上,苹果的做法可能会显著提高用电效率。
与M1相比,他们将M1 Pro的内存总线增加了一倍,从128位LPDDR4X接口转移到更宽更快的256位LPDDR5接口,承诺系统带宽高达200GB/s。 我们不知道这个数字是否是精准地,但是LPDDR5-6400接口的宽度将达到204.8GB/s。
上图将AnandTech分享地M1与M1 Pro进行对比,
M1 Pro内存接口更加巩固在SoC的两个角上,而不是像M1那样沿着两条边展开。 由于接口宽度的增加,我们看到内存控制器占用了相当大一部分SoC。 显然在内存控制器后面直接使用了两个系统级缓存(SLC)块,对比M1,SoC的系统级缓存4MB L2,它是跨所有IP块共享的。
苹果的SLC设计精巧,因为它们服务于整个SoC,能够扩大带宽,减少延迟,或者只是通过避免内存处理与芯片分离,极来降低功耗。 这个新一代SLC块看起来相当不同于我们在M1上看到的。 SRAM单元区域看起来比M1的大,所以虽然我们现在不能确切地确认这一点,但这可能意味着每个SLC块中有16MB的缓存——对于M1 Pro来说,这意味着总SLC缓存32MB。
在苹果首此发布M1时,笔者最终得出的结论时——这是一款可以足够好服务于苹果生态完整性的芯片产品,但是并不代表是一款最高性能的SOC,也并不能说明Arm架构将彻底在与X86竞争的这场战役中占上风。本次发布的M1 Pro产品,在性能核心方面,苹果现在增加了一倍,达到8核。曾经,苹果的M1多线程性能方面落后于其他8核SOC,但随着本次新品的推出,M1 Pro必然在多线程操作的过程中有着更加突出的表现。毕竟ARM,基本上可以称之为精简指令集(RISC)的代名词,而针对设计超高性能的台式机和服务器处理器,Intel的优势更加明显。所以显然,从苹果进阶的芯片产品推出的方向看,他们更希望能够在保持低功耗的RISC基础上,可以让芯片的多线程处理性能进一步提升。
苹果似乎镜像了两个4核块,L2缓存也被镜像。 虽然苹果在这里引用了24MB的L2,但Anandtech认为这是一个2x12MB的设置,使用的是类似AMD核心的设置。
在CPU性能指标方面,苹果与竞争对手进行了一些比较,特别是这里比较的sku是英特尔的酷睿i7-1185G7和酷睿i7-11800H,这是英特尔最新的Tiger Lake 10nm“superin”CPU的4核和8核版本
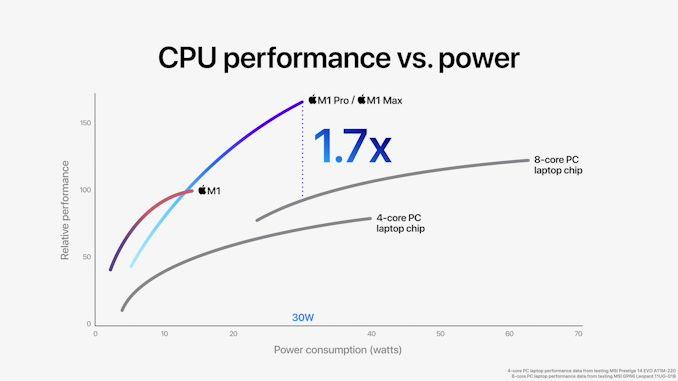
苹果的展示的运行测试结果显示,在多线程性能方面,这两款新芯片都大大超过了英特尔提供的任何芯片,而且功耗大大降低。 所呈现的性能/功率曲线显示,在30W等功率使用情况下,新M1 Pro和Max的CPU吞吐量比11800H快1.7倍,其功率曲线非常陡峭。 然而,在同等的性能水平下——在本例中使用11800H的峰值性能——苹果表示,新款M1 Pro/Max实现了同样的性能,功耗降低了70%。 这两个数字之间存在巨大差异,远远超过了英特尔目前的成绩。
但是笔者隐约记得在去年在发布会中,苹果表示,这是世界上最快的CPU。但是想要真正评估,我们最好真的看一下Firestorm CPU内核的微架构。根据我们现有可以得到的信息有限,从苹果官网注明的测试基准,其实重点在于运行顺畅,比如Safari浏览器上网,JavaScript的运行速度提升,睡眠模式唤醒等等,这个测试方式还是对macOS系列的产品有优势的。(笔者注,具体的测试方式Apple 于 2020 年 8 月和 10 月使用 JetStream 2、MotionMark 1.1 和 Speedometer 2.0 性能基准对完成测试的浏览器进行了此项测试。测试使用预发行版 Safari 14,以及 Chrome、Firefox 和 (Windows) Microsoft Edge 在测试时的最新稳定版本,以及配备 Intel Core i5 处理器的 13 英寸 MacBook Pro 系统,运行预发行版 macOS Big Sur,并用启动转换运行 Windows 10 Home)
除了强大的CPU综合体,苹果还在扩大其自定义GPU架构。 M1 Pro现在采用了16核GPU,宣传的计算吞吐量性能为5.2 TFLOPs。更大的GPU将被更宽的内存总线支持,以及大概32MB的SLC——后者本质上类似于AMD的Infinity Cache。(笔者注:AMD推出的Infinity Cache架构,主要目标是希望解锁游戏场景下,从1080p到4K的升级,否则,沿用传统设计方式,则可能需要超级昂贵且消耗巨大的512位内存总线,无限缓存位于主计算核心集群的旁边,本质上充当一个小型但有效的内存存储。 它位于较小的L1和L2缓存之间,也在GPU本身)
据称,苹果的GPU性能大大超过了任何上一代竞争对手的集成显卡性能,因此该公司选择直接与中端笔记本电脑的IGPU进行比较。 在这种情况下,M1 Pro与GeForce RTX 3050 Ti 4GB芯片进行了对比,苹果芯片在功耗降低70%的情况下实现了相似的性能。 这里显示的功率水平约为30W,但是还不清楚是系统功率,SOC功率或者知识在比较GPU模块本身的功耗。但是不可否认的是,苹果Mac系列产品图形处理能力越发强大。
至此,本次发布会依然有惊喜,继M1 Pro之后,M1 Max更加令人眼前一亮,因为本质上并不是我们常见的SOC+GPU的方式,它更像是GPU+SOC,实际上此类的应用配搭在消费类电子领域不太常见,更像是工业自动化领域做数据处理,外围电路用简单MCU控制的方式。
M1 Max的封装更大,并且DRAM芯片从2增加到4,这也对应于内存接口宽度从256位增加到512位。400GB/s的巨大带宽,如果它是LPDDR5-6400,可能更准确地说是409.6GB/s。 这种带宽基本上只出现在高端GPU中而不是传统SoC。
根据上图可以看到,对比M1 Pro整体上部的架构还是近似的,另外两个128位LPDDR5块很明显,而且有趣的是,它们还增加了SLC块的数量。 如果确实是每个块16MB,那么整个SoC就可以使用64MB的片上通用缓存。
在如此巨大的内存带宽资源下,或许除了显卡的作用,也在功能上有其他方面的考量,笔者猜测这里与机器学习相关的模块有相关性。毕竟在对比i9等core的同类型产品,跑相同的ML Model,M1 Max的速度会快很多。
综上,毕竟ARM使用精简指令集,芯片子模块的门控时钟和电源开关通常是设计电路时就决定的。在后端设计方面,诸如处理电压,时钟等问题,控制在输入电压切换的时候产生的动态功耗和关断模块的漏电功耗至关重要。总体来讲,这个可能需要结合软件系统来看,比如app workflowdata数据的手机,可以帮助优化MacOS给中央处理器的各个核心分配的多线程任务等等。拥有自主OS的硬件在产品迭代的思路上有更多不可复制性。


.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)




-%E5%89%AF%E6%9C%AC.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)



 [课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
[课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
