


 1905
1905
这两天的加州圣何塞,绿意浓浓。当爱尔兰人的圣帕特里克节,遇上英伟达的GTC大会,街头随处可见身着绿色服饰、庆祝节日的爱尔兰人,还有挂满城区的GTC海报,大大地写着:What’s Next in AI Starts Here,昭示着AI发展的新起点。
当地时间3月18日上午10点,黄仁勋在SAP中心发表主题演讲。一早乘车过去,就看到SAP几公里开外,候场人群已经排起长长的队伍,一路绵延好几个街区。你无法准确说出这是AI的热度所致,还是英伟达和黄仁勋本人的感召力。

波动下,Token撬动AI商业版图快速成形
受推理模型DeepSeek重创、股价经历了戏剧性波动的英伟达,本次GTC生动演绎了“在哪跌倒,就在哪爬起来”。黄仁勋在2个多小时的演讲中,重点围绕推理机遇,讲述了通过Token(信息单元)撬动新AI商业版图的三层逻辑:
技术层面,当前仍以Blackwell架构为核心,未来三代GPU架构都在开发中,分别是Rubin、Rubin Ultra、Feynman。并且,通过软件将硬件潜力转化为用户可感知的Token效率,这包括开源的推理软件工具、加速库、套件等。
战略层面,强化“AI基础设施企业”定位,覆盖AI训练、推理,抢占云端、边缘的多样化场景,牢牢巩固护城河。
商业层面则蕴含了黄仁勋对Token经济的深刻洞察,全栈生态层层铺就,通过Agentic AI和Physical AI两个大招,几乎覆盖了大部分行业和需求,有望加速AI普及。
事实上,在AI云端训练最为炙手可热的时候,黄仁勋已经预测了推理需求的爆发。在Keynote中,他进一步解释,推理的本质就是Token生成,这对企业至关重要。随着最新一代推理模型能够思考和解决日益复杂的问题,业界对Token的需求将会持续增长。
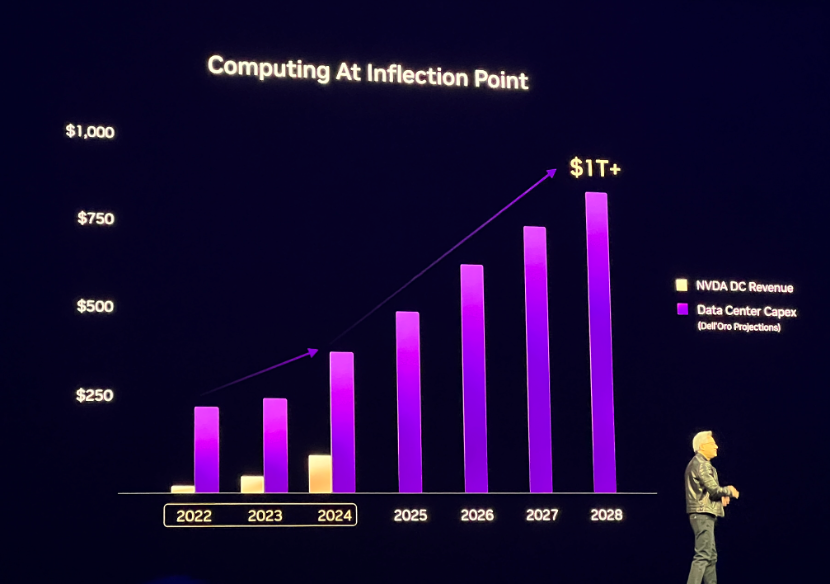
AI的发展其实也是具备“逐步推理”能力的成长历程,而推理和强化学习需求等等,正在持续推动AI计算需求的增长。黄仁勋透露,全球前四大云服务商去年采购了超130万片Hopper架构GPU,今年或将采购360万片Blackwell架构GPU。
“计算正处在拐点”,黄仁勋表示,拐点可能出现在2024至2025年间,预计数据中心建设的市场价值将达到 1 万亿美元。
第一层逻辑:Blackwell为核心,软件提升Token效率
目前,Blackwell 已进入全面量产阶段,“增长非常迅猛,客户需求也非常强劲,”黄仁勋表示,“这是有道理的,因为 AI 到达了一个拐点,推理AI的出现使我们需要的计算量大大增加,同时推理AI系统和代理式系统的训练也在推动这一变化。”
他详细介绍了 Blackwell 如何支持极限扩展。最新发布的Blackwell Ultra GPU架构更擅长满足AI推理需求,它是全球首个288GB HBM3e GPU,通过先进封装技术将2块GPU拼装在一起,可实现多达1.5倍的FP4推理性能,最高15PFLOPS。该GPU增强了训练和测试时推理扩展,可轻松有效地进行预训练、后训练以及深度思考(推理)模型的AI推理,构建于Blackwell架构基础之上,还包括GB300 NVL72机架级解决方案和HGX B300 NVL16系统。
要帮助客户扩展到更大规模的系统,下一步的关键还在于Photonics 技术——这是一种依赖于光而非电信号传输数据的网络技术,它将紧密集成到加速计算基础设施中。
NVIDIA Spectrum-X和NVIDIA Quantum-X 硅光网络交换机通过融合电子电路和光通信技术,支持AI工厂能够在多个站点之间连接数百万个 GPU,同时降低能耗和运营成本。
与传统方法相比,英伟达硅光交换机创新地集成了光器件,减少了4倍的激光器数量,能源效率提高到3.5倍,信号完整性提高到63倍,大规模组网可靠性提高到10倍,部署速度提高到1.3倍。
黄仁勋表示,之所以要做到大量的工作,就是为了应对一个极端挑战——推理。而为了充分发挥硬件的潜力,实现更高效的推理,英伟达在软件方面也进行了更为全面的布局。
最新推出的开源软件NVIDIA Dynamo,是一个用于大规模服务推理模型的AI推理软件,旨在为部署推理模型的AI工厂实现Token收入最大化。它能够跨数千个GPU编排和加速推理通信,并使用分区分服务来分离不同GPU上大语言模型的处理和生成阶段,使每个阶段可根据特定需求独立优化,并确保GPU资源的最大利用率。
在GPU数量相同的情况下,Dynamo可将Hopper平台上运行Llama模型的AI工厂性能和收益翻倍。在由GB200 NVL72机架组成的大型集群上运行DeepSeek-R1模型时,Dynamo的智能推理优化也可将每个GPU生成的token数量提高30倍以上。
基于Dynamo,Blackwell比Hopper在性能方面提升25倍,可以基于均匀可互换的可编程架构。在推理模型中,Blackwell性能是Hopper的40倍。
第二层逻辑:战略上强化“AI基础设施公司”定位
近年来,英伟达逐渐将自身定位于产业的 “AI工厂”,能够帮助客户赚钱、转化为客户收入。
当前,业界正站在计算范式的转折点,即将从检索式计算转向生成式计算 。而下一步,要从ChatGPT这样的生成式AI,迈向Deep Research、Manus这样的Agentic AI应用,届时,每一层计算都将不同,所需要的Token比想象中多100倍。这是因为在Agentic AI应用中,上一个Token是下一个Token生成时输入的上下文、是感知、规划、行动的一步步推理。
而AI 工厂就是要高效地处理这些Tokens,通过软硬协同优化,以更低的计算成本处理更多Token。如此一来,当更复杂、智能的推理模型,需要更快、更多地吞吐Token时——如何能够有一套更高效的系统,就成为AI应用能不能赚钱的关键。
这也从另一方面论证了AI工厂的重要性:客户公司所能实现的最大收入其实取决于AI工厂是否以最佳目标运行,因为其性能将直接转化为Token百分比。
“我们现在的AI工厂业务,竞争门槛远高于以往,客户的风险容忍度也远低于以往。因为这可能是一个涉及数千亿美元的多年周期的投资,这是一项基础设施业务”,黄仁勋强调,“英伟达其实是基础设施公司,是全世界的工厂,也是无数企业的基石。
在进一步加速大规模推理方面,NVIDIA Dynamo,本质上就相当于是AI工厂的操作系统。他表示,商业门槛越来越高,竞争门槛越来越高,但应用AI的门槛在降低,英伟达要通过软件来降低使用门槛,让AI更易用、更普及。
目前,NVIDIA CUDA-X GPU 加速库和微服务现在服务于各行各业。CUDA的安装基础“无处不在”,他认为,“我们已经到达了加速计算的临界点——CUDA 让这一切成为可能。”
迄今为止,AI已经历了三代技术范式的转移。最早是判别式AI(语音识别、图像识别),接着是生成式AI,然后就是当下身处的Agentic AI,未来会是影响物理世界的Physical AI。
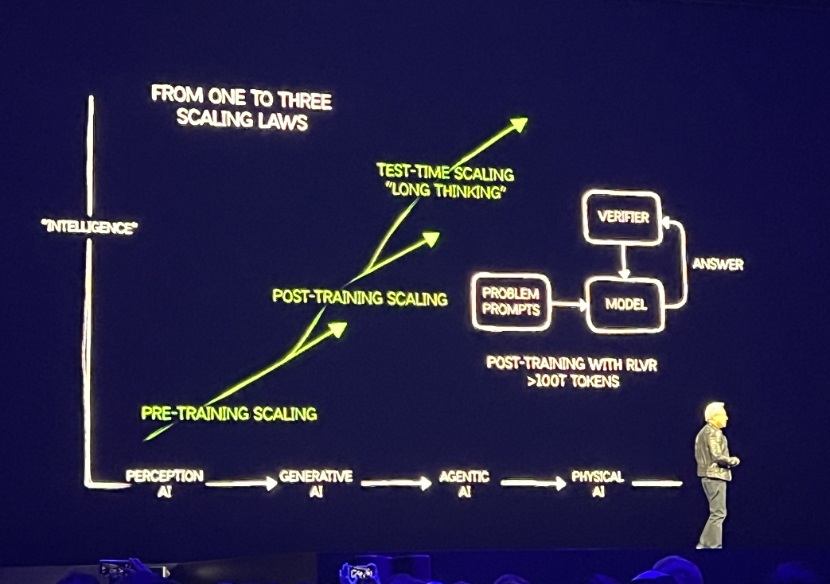
而每一代AI技术迁移,计算的方式都会发生改变。从AlexNet到ChatGPT,是从检索的计算方式转变为生成的计算方式,也需要更多的算力来提供支持。
黄仁勋强调,除了预训练和后训练(微调),测试时的Scaling Law才刚刚开始。也就是说,模型的推理阶段,动态分配计算资源以提升性能。例如,根据问题复杂度自动延长“思考时间”,或通过多次推理生成多个候选答案并择优输出。
特别是对于长思考任务(如复杂决策)需处理百万级token/查询,算力需求呈指数增长。这些复杂的推理场景(如客服、医疗诊断)等,将成为企业AI落地的关键场景。
上述趋势之下,英伟达将继续进行全栈优化。黄仁勋强调,一方面,英伟达通过CUDA-X工具链、Megatron框架等,实现从数据预处理到推理的全流程加速,降低单位token成本;另一方面,将继续推动可扩展的算力基础设施,服务好企业级客户。
第三层逻辑:Agentic AI和Physical AI扩大商业版图,加速AI普及
黄仁勋提到,当AI基于思维链进行一步步推理、进行不同的路径规划时,它不是生成一个Token或一个单词,而是生成一个表示推理步骤的单词序列,因此生成的Token数量会更多,甚至增加100倍以上。而这对计算提出指数级需求,随着计算成本增加,就需要全栈创新来降低成本/Tokens。
Agentic AI方面,英伟达推出了具有推理功能的开放Llama Nemotron 模型系列,希望为开发者和企业提供业务就绪型基础,从而构建能够独立工作或以团队形式完成复杂任务的高级AI智能体。
这一推理模型系列是基于Llama模型构建的,能够提供按需AI推理功能。NVIDIA 在后训练期间对该推理模型系列进行了增强,以提升多步数学运算、编码、推理和复杂决策能力。
此外,他认为机器人是下一个10万亿美元的产业。预测到2030年年底,全球将面临至少5000万劳动力短缺的问题。为此,英伟达提供了一整套技术,用于训练、部署、仿真和测试下一代机器人技术。并且,英伟达还最新宣布推出全球首个开源且完全可定制的基础模型 NVIDIA Isaac GR00T N1,该模型可赋能通用人形机器人实现推理及各项技能。
针对企业级AI这个超大规模的市场,英伟达正为全球企业提供构建Agentic AI的核心模块。英伟达的Llama Nemotron可以在任何地方运行,包括DGX Spark、DGX Station以及OEM制造的服务器上,甚至可以将其集成到任何Agentic AI框架中。
此外还有新一代 NVIDIA Cosmos 世界基础模型的重大更新,为Physical AI开发引入了一个开放式和可完全定制的推理模型,并为开发者提供了前所未有的世界生成控制能力。
黄仁勋表示:“使用Omniverse来调节Cosmos,并通过Cosmos生成无限数量的环境,从而支持我们能够创建既扎根于现实、由我们掌控,同时又在系统上可以实现无限的数据。”
他补充,这其实也是为了解决Agentic AI和Physical AI的核心问题:数据问题、训练问题、以及如何通过大规模扩展让AI更聪明。显然,英伟达一直在不遗余力推动将先进的模型开源,再加上完整的合成数据生成与仿真、训练等进行融合,试图推动AI更大范围的铺开。
写在最后
某种意义上,今年的GTC大会不仅对于英伟达自身发展路线具有重要意义,也是AI真正开启商用时代的风向标。本次GTC不仅展示了英伟达从计算机技术公司向AI基础设施公司的转型,展示了数据中心从单纯存储数据、托管应用的角色向AI工厂的转型,同时也证明了Token经济带动的一个全新产业的诞生。
“买得越多理论”也被黄仁勋再次提及,只不过现在的版本是“The more your buy, the more you make”。Token经济的未来,应该是买得越多,赚得越多,这是黄仁勋最大的期望。













 [课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
[课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
