


 2379
2379
近年来,全球消费电子市场经历了起起落落,如今正展现出复苏的积极态势。从手机和 PC 市场的数据报告中,我们能清晰地捕捉到这一趋势。
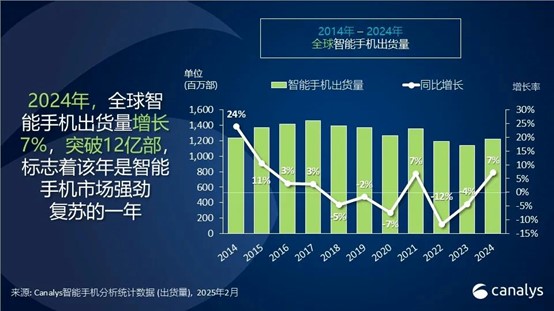
图 | 2014-2024年全球智能手机出货量情况;来源:Canalys
根据Canalys发布的数据显示,2024年全球智能手机市场出货量达到12.2亿部,同比增长7%;同时,全球PC市场也呈现出稳步回暖的态势,全年出货量同比增长3.8%,达到2.55亿台。这一复苏趋势不仅体现在出货量的增长,还反映在消费电子产业链的盈利改善上。
AI正在成为消费电子换新潮的核心驱动力
纵观这场全球性的消费电子复苏,除了经济环境的改善和消费者信心的恢复,人工智能(AI)无疑成为了引领换新潮的核心驱动力。
事实上,AI正在重新定义手机和PC的功能边界,为用户带来全新的体验。如今,AI已经成为各大手机厂商竞相发力的核心领域。例如,苹果在2024年推出了Apple Intelligence,试图通过自研芯片与生成式模型对用户体验进行全面提升;三星通过与AMD合作,在Exynos芯片中引入了高性能GPU,以支持AI负载和游戏性能;华为、OPPO等厂商也纷纷接入DeepSeek等AI大模型,加速AI端侧部署。
结合当下形势,Counterpoint预测,2024年全球AI手机渗透率约4%,出货量有望超1亿部;而到2027年,全球AI手机渗透率将达到40%左右,出货量有望达5.22亿部。
值得一提的是,当AI 手机、AI PC等AI负载为消费电子行业带来新增长动力的同时,相关产业链也同步进入高速发展期,产业升级过程中,处理器芯片、内存、传感器和散热解决方案提供商成为最大受益群体。
AI负载离不开GPU,为什么?
为什么处理器芯片、内存、传感器和散热解决方案提供商将成为最大受益群体呢?首先,我们要弄清楚AI负载的特色。
AI负载的核心特点是高并行计算和大量数据处理。无论是图像识别、自然语言处理还是深度学习模型推理,都需要强大的计算能力来支持,而存取、加载大模型需要搭载更高容量 和性能的存储,以AI手机为例,16GB RAM或将成为新一代AI手机的基础配置。此外,AI任务的高频高密特性对手机散热、摄像头、电池、PCB等零部件同样提出了更高的标准。
联发科无线事业部AI技术高级经理庄世荣曾表示:“端侧130亿参数大模型需要配备70TOPS算力的处理器芯片以及13GB容量的内存。”
而对于端侧AI设备来讲,AI用例需求存在多种类型,具有复杂性、并发性和多样性,对应对芯片的性能及资源调用提出不同要求。其中,在深度学习领域,GPU 已经成为了主流的算力硬件。例如,AI手机中的图像识别、语音翻译和个性化推荐等功能,都需要GPU的强大算力支持。这是为什么呢?
因为GPU 具有强大的并行计算能力,能够同时处理大量的数据和复杂的计算任务。在 AI 训练和推理过程中,需要进行大量的矩阵运算,GPU 的并行架构能够显著加速这些运算过程,大大缩短训练时间和提高推理效率。与 CPU 相比,GPU 在处理大规模数据时具有更高的性能和更低的能耗,因此成为了 AI 负载的首选硬件平台。
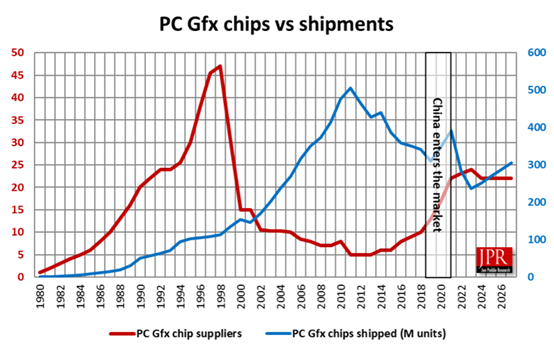
图 | 2024年GPU出货量超2.51亿块,同比增长6%;来源:Jon Peddie Research
受到下游需求的驱动,近年来GPU产业发展迅速。根据Jon Peddie Research 发布的数据显示,2024 年全球 GPU 市场规模将超过 985 亿美元,出货量超2.51亿块,同比增长6%。
另外,Yole Group 预测,2023-2029年,高性能计算GPU市场复合年增长率(CAGR)将达到25%,远超CPU的5%和APU的8%;到2029年,GPU 细分市场收入预计将比 CPU 细分市场大两倍;到2034年,GPU市场规模有望突破1.4万亿美元,成为处理器市场增长的核心驱动力。
AI负载对GPU提出了哪些新的要求?
如上所述,随着 AI 技术的不断发展和应用场景的日益丰富,GPU 市场迎来更为广阔的发展空间。
与此同时 ,AI 负载的不断升级也对 GPU 提出了新的挑战和要求。一方面,为了支持更复杂的 AI 模型和算法,GPU 需要具备更高的计算能力、更大的显存容量和更强的兼容性。另一方面,随着 AI 应用对实时性要求的提高,GPU 需要具备更快的数据传输速度和更低的延迟。此外,为了降低成本和提高能效,GPU 的设计还需要更加注重集成化和优化架构。
众所周知,在GPU领域,Imagination Technologies(以下简称“Imagination”)一直是行业的风向标。近年来,Imagination逐步调整资源配置,将资源集中在AI、汽车电子、桌面和数据中心等高增长领域,推出了多款高性能GPU IP产品。接下来我们以Imagination在GPU领域的产品创新为例,来了解GPU产业对AI负载的需求跟进。
去年9月,面向车载智能和交互设计需求,Imagination 推出了一款可扩展、灵活GPU IP ——IMG DXS,峰值性能比 其上一代汽车 GPU 提高了 50%,计算工作负载的性能提升多达10倍,能够支持驾驶舱、信息娱乐和高级驾驶辅助系统。此外,Imagination还通过与全球领先的安全关键型软件提供商合作,进一步巩固了其在AI和汽车领域的领先地位。
而在移动设备领域,继2023年1月推出移动光追IMG DXT GPU IP,带领行业实现从PC和主机游戏向移动平台的跨越后,就在今天,Imagination再次推出重磅GPU IP——Imagination DXTP,为智能手机和其他电力受限设备上图形和计算工作负载的高效加速设定了新的标准。
图 | IMG DXTP示意图;来源:Imagination
DXTP,让AI负载“高帧率、高能效”全都有
根据Imagination提供的消息,DXTP提供高达64 GPixel/s的图形处理能力,2 TFLOPS的FP32性能和8 TOPS的INT8 AI性能,采用超并行计算引擎,工作频率为1GHz。
关于工作频率,据悉DXTP 的时钟频率可以超过 1GHz,以实现更高的性能,具体取决于所使用的工艺节点和可用的功耗预算。
据悉,Imagination此次提供了两种现成可售的 DXTP 配置。最小的配置是 DXTP-48-1536,提供 48 GPixel/s、1.5 TFLOPS FP32、3 TFLOPS FP16 和 6 TOPS INT8(均为 1GHz 时的性能),另一种是 DXTP-64-2048,它的性能在各方面提升了 33%。
在能效方面,得益于一系列微架构改进,DXTP在常见图形工作负载上,相比其前代产品DXT,功耗效率(FPS/W)提高了最多20%。
那么,此次Imagination到底在微架构上做了哪些调整呢?这些调整对GPU的性能、能效有产生了哪些影响?
-
DXTP,性能全面升级
Imagination方面表示:“Imagination DXTP 的基本布局与其在移动市场的前款产品 DXT 略有不同。我们做了一些工作,包括通过将计算和纹理处理单元以不同的方式组合在一起,并增加缓存和系统级带宽的大小,我们将每个 GPU 可处理的几何图形量额外增加了 50%,并提高了 GPU 的性能维持能力。”
此外,为了提升AI性能,Imagination不仅在 DXTP 中将本地计算内存增加到 32KB,同时还采用了高能效的处理和数据管理技术。其内存结构能够处理针对移动平台需求特别进行优化的模型,而不是需要大量计算资源在云端运行的重型模型。
据悉,DXTP 支持 FP32、FP16、INT8 和 DOT8 操作。与前系D系列GPU类似,DXTP具有双倍提升 FP16工作负载性能的能力。INT8 DOT操作的速度是 FP32 操作的四倍。通过使用GPU内部的不同处理流水线,我们还可以高效地打包和解包神经网络中使用的各种数据类型,包括 INT4。许多层可能会受到带宽限制,因此INT4可以帮助改善这一问题,同时解压缩 INT4 为 INT8 的额外成本较低,能够有效缓解带宽瓶颈,提升整体吞吐量。支持灵活的数据类型使得GPU相比于具有特定数据类型要求的NPU设计更加具有未来适应性和灵活性。
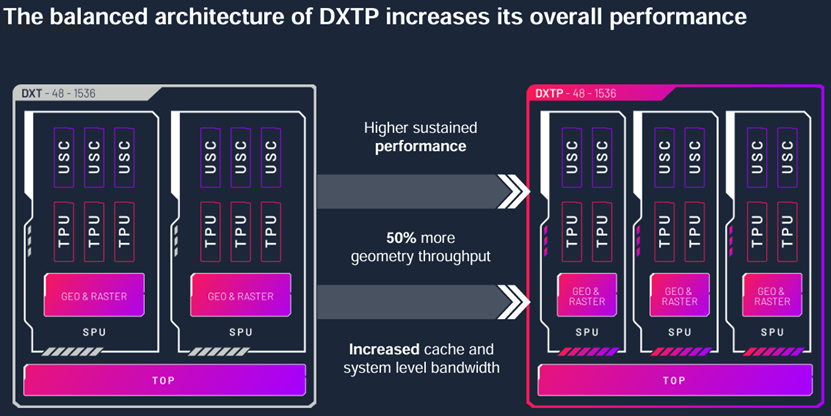
图 | IMG DXTP采用可扩展处理单元(SPU),并配备两个计算集群;来源:Imagination
此外,DXTP 考虑到了复杂网络带宽需求的增加,通过采用可扩展处理单元(SPU),并配备两个计算集群(ALU 和纹理单元),显著提升了每个计算单元的带宽。与 DXT 设计中三个计算集群不同,DXTP 只需要为两个计算集群提供带宽,这意味着每个计算集群的带宽最多提升 50%。
-
DXTP,能效提升20%
在能效提升方面,此次Imagination还通过调整 GPU 内的子单元,将已经非常高效的图形和计算处理器的能效提高了 20%。
也许有人对能效提升20%这一数据来源有一些疑问,这是如何的出来的呢?
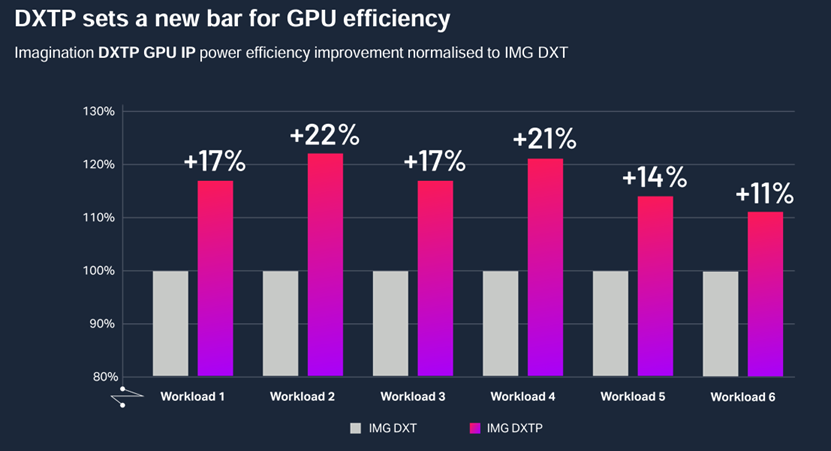
图 | 相比前代产品DXT,DXTP的功耗效率(FPS/W)提高了最多20%;来源:Imagination
对此,Imagination方面表示:“关于DXTP能效提升的研究,我们比较了 DXT-48-1536 和 DXTP-48-1536 在各种基准测试和游戏中的能效。如上图所示,结果因工作负载而异,在所分析的工作负载中,功效提升了 11% 到 22%。功耗效率是基于 ISO 工艺之上的功耗模拟,使用了我们的 RTL 硬件仿真器去捕捉GPU设计的栅极切换率,并将其输入到模拟每个晶体管功耗特性的工具,从而进行流片前功耗效率分析工作。我们对等效的 DXT 和 DXTP 设计采用了相同的方法,因此可以通过遵循这一流程,在各种工作负载中实现可靠的能效改进。”
生态就绪,DXTP等你来战
如今,不管是AI手机还是其他AI终端,CPU+GPU+NPU的异构计算架构已成为市场主流,如前面提到的,GPU是其中重要的加速器之一。
与CPU相比,GPU的并行性为图形和人工智能工作负载提供了更好的性能;与许多NPU相比,它提供了更好的可编程性和标准化编程模型,如 OpenCL和Vulkan Compute,而不是复杂的定制工具流和API。
在多核协同方面,当前通过集成的 RISC-V 固件处理器(可调度和管理 GPU 内的所有工作负载和事件),我们可以使用 GPIO 接口直接与第三方处理模块(如NPU)进行最小延迟的交互。这样,当各层从NPU转移到GPU时,就能以最少的空闲时间实现峰值性能。
对此,Imagination方面表示:“我们在 UXL 基金会等组织中发挥了领导作用,该项目现已成为 Linux 基金会的一部分,它正在帮助开发人员使用oneAPI标准,以加速他们在多供应商、多处理器环境中的工作负载。”

图 | IMG DXTP生态已就绪;来源:Imagination
据悉,在操作系统适配层面,DXTP 支持标准的 Linux 和 Android操作系统,并与领先的游戏引擎提供商和开发商密切合作,确保消费者在基于Imagination的设备上运行游戏和其他应用程序时获得最佳体验。
除了对标准的Linux 和 Android支持外,Imagination 还向直接客户提供对DDK源代码的完全访问权限,以便与各种定制操作系统(如 RTOS)进行移植和集成。
在操作系统层以上,DXTP在SDK及工具支持方面同样具备优势。其中,PowerVR SDK 帮助开发者通过一步步的示例代码入门,了解如何为Imagination GPU编写代码,并提供了关于Imagination GPU工作原理的详细文档以及创建最佳图形应用程序的技巧。该 SDK 配备了一系列行业领先、功能丰富的工具,能够为软件开发者提供有关其应用程序性能的详细见解(PVRTune),并帮助他们识别需要优化的领域(PVRCarbon 和 PVRStudio)。
综上,随着生态建设的不断完善,IMG DXTP GPU的舞台已经搭建完毕。从AI加速到图形渲染,从游戏到专业创作,强大的GPU性能正等待每一位开发者和创作者的探索。
来源: 与非网,作者: 夏珍,原文链接: https://www.eefocus.com/article/1806617.html







