


 2736
2736
中国信通院发布的《2024全球数字经济白皮书》显示,2023年至2024年第一季度,中国共涌现出71家AI独角兽企业,其中大模型数量占比高达36%,即478个。随着基础通用大模型的能力上限被不断刷新,算力成本、功耗、技术门槛、行业落地等问题与挑战也越来越突出,如何从底层算力、平台、应用场景等维度寻求破局,成为大模型落地的关键。
对于企业来说,如何更好地迎接以大模型为基础的AI时代?这其实需要在性价比、创新性以及安全等方面做好准备,也意味着需要打造以AI负载为中心的基础架构新范式。日前,在2024火山引擎FORCE原动力大会期间,英特尔与火山引擎联合发布的第四代云服务器实例引起了广泛关注,该实例不仅降低了大模型的应用门槛,更通过云与AI深度融合的服务能力,推动了AI技术边界的不断拓展。
生成式AI推动下,云计算+AI的交融创新
大模型应用首先离不开强大的算力支持,尤其是随着需求增长,高性能异构算力的重要性越发突显,同时,绿色节能方案变得至关重要,以确保技术发展的可持续性。
过去十几年,移动互联网迅猛发展,英特尔作为基础技术提供者,支持了字节跳动等新一代互联网企业的崛起。如今,随着ChatGPT等技术的推动,生成式AI技术迎来了快速发展,一个波澜壮阔的新纪元即将开启。
“在生成式AI主导的新时代,融合AI技术与云计算成为了必然趋势。云计算作为一个强大的支撑平台,将持续助力大模型效果、性能的不断提升。而反过来,大模型技术的每一次创新,又会成为推动云计算技术发展与创新的强大动力”,英特尔市场营销集团副总裁、中国区云与行业解决方案和数据中心销售部总经理梁雅莉谈到。
移动互联网时代,应用的核心在于连接——无论是人与人之间,还是人与世界的联系,其本质都是提升协作效率。而大模型技术催生的智能体通过协作共进,解锁了更高级的能力,为实现更高级的通用人工智能打下了坚实的基础,未来将是一个虚实交融、智能互连的新世界。
梁雅莉表示,在这一过程中,AI和云计算将会是不断更迭、不断创新的交融。移动互联网时代,行业熟知的云计算服务以IaaS、PaaS为代表,分别为云原生应用的构建提供基础计算资源和软件平台级服务。而迈入AI时代,面对重新定义的大模型应用架构和开发运营模式,云计算的边缘在不断扩展,MaaS(模型即服务)会成为互联网企业核心的AI技术输出能力,也是主要变现的能力。

面对新的发展趋势,英特尔与字节跳动旗下的云服务平台——火山引擎密切合作,从算力、平台、应用场景等多个维度探索创新的解决方案。
对于火山引擎来说,PaaS层面衍生出了扣子Coze这样基于智能体、工作流方式的大模型应用孵化平台;IaaS 层面聚焦于满足训练、开发验证等多样算力的需求。对于轻量级大模型应用开发场景,火山引擎为开发者提供了g4il云实例,相较于GPU实例,资源门槛直降50%,背后正是英特尔至强6性能核的加持。
并且在智能体领域,英特尔与“扣子”合作推出了增强版的扣子智能体开发平台——Coze-AIPC。通过引入基于英特尔PC端平台的扣子App,并通过创新的“端插件”机制,使PC操控、本地知识库等AIPC的端侧能力可以被无缝嵌入扣子大模型与工作流,从而为开发者提供便捷、低时延和具备成本效益的端云协同智能体新体验。

值得强调的是,至强6性能核主要用于通用计算、数据Web服务、科学计算、AI等场景。性能相比上一代平均提高超过2倍,尤其是科学计算,有超过2.5倍的提高,对AI大语言模型甚至有超过3倍的性能提高。与此同时,至强6性能核还兼顾了能效,是上代的1.5倍甚至更高。通过至强6性能核,英特尔满足了AI数据中心对高性能、低成本、稳定性、安全性和绿色节能的需求。
火山引擎基于此打造的新一代云实例,不仅具备高效弹性能力,还能充分保障数据安全,并在AI推理等智算任务上实现性能的大幅提升。
豆包大模型高速增长背后——高性能、智能算力底座的重要性
在竞争激烈的大模型市场,豆包大模型脱颖而出,日均调用量从5月份的1,200亿tokens增长至12月的4万亿tokens,7个月内增长超过33倍,成为国内AI应用中的佼佼者。并且,豆包大模型仍正不断优化和扩展,包括新成员豆包视觉理解模型的加入,都标志着大模型向多模态应用迈进的关键一步。
豆包大模型的高速增长,是市场快速发展的一个缩影,体现了算力在AI技术发展中的核心作用——高性能的异构算力直接关系到大模型的性能和效率,以及迭代创新的速度。
火山引擎弹性计算产品负责人王睿,分享了火山引擎基于英特尔技术打造的弹性算力底座的产品化实践。他强调,随着生成式AI和大模型训练的兴起,全球对算力的需求激增,凸显了智算平台基础设施的重要性。火山引擎通过海量资源共池,满足企业在AI技术和智算化转型中的算力需求,同时通过共池释放成本红利给客户,实现了百万规模的资源弹性,天级别可实现50万核的弹性能力,峰值可以达到100万核,分钟级别可达10万核。
据介绍,全新发布的第四代通用计算型实例g4il,搭载了最新的英特尔至强6性能核处理器和火山引擎自研的DPU,实现了计算、存储和网络性能的全面升级。相比上一代产品,g4il在视频转码、Web应用、和数据库应用方面分别实现了17%、19%和20%的性能提升。此外,g4il进一步丰富了实例的功能,比如新增了大包传输能力(Jumbo Frame)、机密计算能力(TDX)、以及支撑最新云盘吞吐类型SSD。
王睿强调,英特尔至强6性能核处理器上新增了高速内存MRDIMM,同时新增了支持AMX FP16指令集,更大的内存带宽叠加更强的矩阵运算能力,为AI推理加速提供了更优的底层基础环境。火山引擎基于开源模型Llama2 7B上实现了大幅性能提升。GNR加上MRDIMM,实测的吞吐性能相比英特尔EMR CPU加上通用型DDR5内存,最高提升可以达到80%。同时相比单卡的A10和L20 GPU测试结果也得到了印证,有很大的优势。
除了AI推理方面的极致性能,用户也越来越关注整体安全性。针对云上的AI场景,火山引擎打造了端到端安全解决方案,基于CPU和GPU硬件机密计算能力,火山引擎在固件、内核、虚拟化以及操作系统等方面做了深度调优,在云服务器产品上,高效使能了机密计算能力,将内存加密等特性造成的性能损失降到最低。
此外,火山引擎还推出了业界首创的弹性预约制售卖方式,支持免费资源提前预约,自动交付,节省成本超过33%。百万规模的弹性资源池为各种极致弹性应用场景提供了澎湃算力。
“在新一代AI基础架构中,我们判断大模型对算力规模、算力性能,集群内通信效率、模型训练和并行模式、存储性能、隐私安全等都会有更高要求,我们希望和英特尔持续携手,更好应对智算时代的新挑战”,王睿表示。
走近至强6——生成式AI基础设施的“超级大脑”
为了满足数据中心对高性能、低成本、稳定性、安全性以及绿色节能的需求,英特尔推出了新一代至强6处理器。这款处理器结合了能效核和性能核的双微架构设计,实现了性能的大幅提升和能效比的重大突破,契合了AI数据中心对高性能、低成本、稳定性、安全性以及绿色节能的需求。特别是在AI推理方面的表现尤为突出,它就像是一个超级“大脑”,提供强大的计算能力和高效的数据处理速度,使得复杂的AI任务能够快速且高效执行。
QAT加速器实现云存储性能提升
其中,内嵌式加速器QAT、IAA、DSA、DLB等,实现了在不同场景下卸载CPU算力,助力了整机算力的综合提升。目前,英特尔和字节跳动在QAT方面的合作已经取得了显著成效。

事实上,QAT并不是一项新技术,而是英特尔至强6处理器第一次把它用于CPU中。据英特尔技术专家解释说,QAT主要带来三方面好处:
- 第一,性能。Gzip的压缩每个核大概每秒只能达到100MB的速度,相对QAT来说,是5GB/s的速度,这是非常大的提升。
- 第二,可扩展性。CPU上的QAT最多可以支持四个,一方面可以针对实际需求进行定制化,另一方面也可以选择所需要的CPU型号。
- 第三,QAT在带来高性能的同时,功耗也非常低,在性能功耗比方面有显著提升。在很多应用场景中,例如存储,用户需要通过QAT节省CPU核,提升TCO。
QAT主要提供三种能力:第一,非对称加解密,用于Web服务、负载均衡器、内容分发网络中的TLS握手过程;第二,压缩和解压缩:支持多种格式,如LZ4、Gzip,以及最新版本中的ZSDT;第三,对称加解密:利用CPU的AVX-512指令集,减少CPU消耗。
用QAT来测TLS卸载的每秒连接数,通过8核16线程加上4个QAT,可以提供的计算能力相当于是超过50个CPU核的计算能力,可以达到节省84%的核的效果。压缩性能方面,第四代至强处理器的QAT相比PCIe形式的QAT,性能提升2倍。
在英特尔和火山引擎云存储团队共同开发的底层的存储库veSAL中,成功引入了QAT。压缩时,一个QAT提供3.8GB/s的带宽,大概可以节省6-8个核心的计算能力;解压缩时,大概是2.5个核的计算能力(这是基于公开数据集得出的结论)。
至强6机密计算的虚拟化实践
伴随机器学习、大模型应用等高算力场景越来越多,用户数据需要在通用处理器和异构加速器之间进行协同计算。英特尔TDX Connect技术,能够使用户数据在异构加速场景中得到机密性保护,既保障了数据安全,又满足了异构加速对高算力的需求。
TDX本身基于虚拟化技术,针对机密计算需求,英特尔做了芯片微架构层面的扩展,引入了新的机密虚拟化模式。英特尔技术专家表示,今天在云场景中,大部分业务都是运行在虚拟化环境里面的,所以用户的应用只要能跑在虚拟化环境中,就可以不做任何应用层面的代码修改,直接升级迁移为机密计算的解决方案。基于这种方式,可以大大降低用户存量应用升级为机密计算的成本。
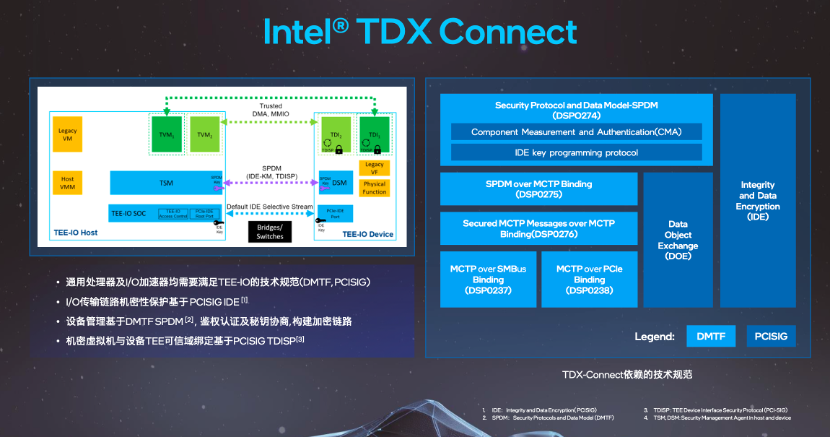
TDX为数据安全提供了多层次的保护能力,当用户虚拟化实例数据写入内存的过程中,利用内存控制器上基于硬件的加解密引擎进行实时加密,可以确保用户数据在内存中始终是密态隔离方式,即便是在云计算这种复杂环境中,哪怕系统中有不可靠、不可信的软件,甚至是黑客攻击,只要不进入虚拟机内部,用户数据始终是安全的。
如今,互联网应用迭代速度之快,部署模式之复杂多样,早已超出了传统应用的范畴。为了确保用户应用从传统计算模式向机密计算迁移过程中在基础软件上实现零投入,英特尔在TDX或机密虚拟化软件生态秉承全面开源策略,包括操作系统、虚拟机控制器以及云原生软件栈和远程证明软件栈,统统提供了开源的生态支持。基于开源生态,用户应用可以弹性支持IaaS、PaaS、FaaS等多种业务模型。
写在最后
底层算力是推动AI释放巨大潜能的关键要素之一,一个功能全面、性能卓越、可靠且具有高可扩展性的计算平台是当前所需。
得益于至强6性能核处理器的领先性能,英特尔助力火山引擎第四代通用计算型实例g4il显著提高了计算效率和系统稳定性。基于英特尔至强6火山引擎云实例进行大模型开发应用,一定程度上实现了资源低门槛和软件高起点。它让大模型推理性能升级,大模型应用开发前期可多聚焦于应用效果优化。软件方面,英特尔携手火山引擎,提供预验证优化模块与组件、集成镜像达成应用一键部署,确保基于开源方案开发也可以有更好的效果和性能。
此外,英特尔至强处理器也为火山引擎带来了更高的数据存储效率和可靠性。正如前文所说,英特尔的QAT、TDX等技术,对云存储效率、云上AI的端到端机密计算都带来了显著的性能提升。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1787256.html


