


 4920
4920
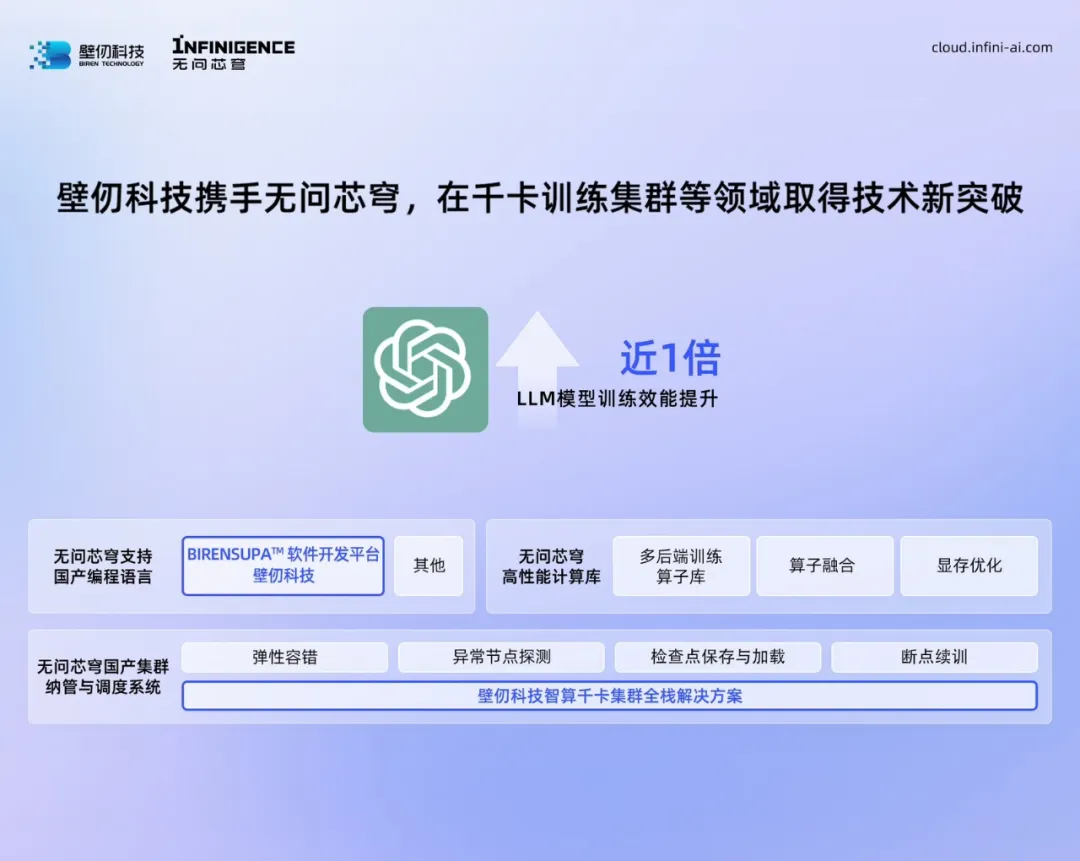
随着智能算力需求的倍增,到2024年,千卡算力集群已成为国内大模型训练的必备场景。壁仞科技,作为国内少数拥有原创训推一体架构的高端算力芯片厂商之一,与在AI算力市场具有重要影响力的无问芯穹在千卡训练集群、大模型推理服务等领域开展了深度的研发合作。
近日,经壁仞科技与无问芯穹联合研发攻关,成功将壁仞科技的千卡规模训练集群在无问芯穹Infini-AI异构云平台上进行纳管和调度,已实现并完整验证了弹性容错、异常节点探测、检查点保存与加载、断点续训四大功能。
与此同时,基于壁仞科技BIRENSUPA™️软件工具链和无问芯穹大模型训练引擎,双方通过并行策略层和计算加速层优化,持续深挖壁仞大算力优势,在壁仞科技GPU上实现了LLM模型训练性能提升近1倍。
在大模型推理服务方面,壁仞科技最新发布的高性能、低功耗壁砺110E推理卡在同机架高度下,AI算力密度最高可达到市场主流云端PCIE8卡服务器方案的1.3倍以上。此外,能耗节省达70%,显著降低整体系统的总拥有成本。
当前,壁砺110E推理卡已在无问芯穹Infini-AI异构云平台的GenStudio大模型服务平台中上线,可广泛应用于大模型多模态生成、图像及语音识别、自然语言处理、搜索与推荐等人工智能推理应用场景,支持大规模分布式推理。在基于壁砺110E的多级推理平台上,结合无问芯穹GenStudio精选模型开放API,已经形成文生图/图生图的秒级出图、多模态大型语言模型(LLM)图文交互和图像理解、移动端聊天应用等多个大模型推理应用场景的商业级用户业务支撑能力。

壁砺110E GPGPU卡
目前,壁仞科技的“壁砺106系列”和“壁砺110系列”GPU产品已完成与无问芯穹Infini-AI异构云平台的全面接入。这些产品支持中间层、大模型算法库、工具库和应用层的分级部署、管理、加速等平台能力,以及各项优化策略。未来,双方将继续携手,在大规模自主可控智能算力集群优化与运营等方面深化合作,进一步提升面向商业化算力客户场景的联合服务水平。
壁仞科技作为国内领先的GPU芯片厂商,秉承“担当、卓越、协作、创新、务实、共赢”的价值观,不断提升技术竞争力,并与合作伙伴携手,从实际用户需求出发,致力于打造性能卓越且具有高性价比的国产AI训练集群方案。







