


 3017
3017
要点 中国是开发GenAI最为积极的市场。据 Omdia 估算,截至 2024 年 1 月,中国厂商开发的基础模型总数已超过 230 个。客户可供选择的模型种类繁多,能力属性各不相同。人工智能工程师和企业常常发现,要为自己的用例确定最佳基础模型是一项挑战。要全面的了解、比较和识别合适的基础模型变得非常困难,但是愈加无可避免。
因此,通过这份《中国商用大模型厂商竞争力排名报告》,Omdia旨在为中国商业基础模型基准测试提供一个全面客观的方法,帮助企业用户了解市场,选择理想的解决方案和厂商。本排名是最佳厂商之间的竞争,所列出的 12 家厂商都是中国最好的基础模型开发商。所有这些厂商都拥有强大的人工智能工程能力,是 GenAI 商业部署的坚实合作伙伴。
Omdia 主要用两个维度来评测厂商,即模型能力和执行能力。此次评测侧重于模型对一般知识和特定领域知识的语言处理能力。本排名中评估的产品是基础模型的语言能力水平和知识深度,以及基于这些基础模型的相应聊天机器人。
模型能力的评测主要借助来自主要研究和独立第三方基准的数据,重点关注基础模型以准确、可预测和安全的方式执行通用任务和特定领域任务的能力。
基础模型能力、一致性和安全性评估完全基于著名的学术研究论文和第三方评估。这种方法可确保评估过程不受参与者的偏见和影响:用任务执行能力:主要用CLiB、FoundaBench、Open LLM Leaderboard 2、OpenCompass 、SuperCLUE、LHMKE、AC-EVAL 、C3Bench和 Conceptmath的评测结果。同时也会考虑国际基准,如 MMLU、HellaSwag 和 LMSYS 等。对齐:主要用AlignBench的评测结果。
安全性:主要用CHiSafetyBench、CRiskEval、MLLMGuard 和 S-Eval。特定领域任务执行能力和可信度:主要用CFLUE、 SuperCLUE-Fin 、CMB 、CS-Bench 和NewsBench的评测结果,同时也会考虑国际基准,如 HumanEval 和 MBPP。多样性: 指基础模型除上述评测外,还能覆盖多种能力。
执行力的评测主要基于Omdia自身定性的研究来评测以下七点:
- 创新力:指厂商在支持 GenAI 开发和部署的基础设施方面的创新,如芯片、云基础设施、开发平台以及智算中心。
- 战略和路线图:指厂商针对特定垂直需求、目标受众以及与合作伙伴的需求而开发的创新。
- 上市战略: 指厂商进入市场的渠道以及对基础模型的销售和营销支持。
- 垂直行业覆盖率:指基础模型所能服务的垂直行业。
- 客户数量:指基础模型的客户总数,尤其是大型国内客户和国际客户。
- 实施服务:指厂商帮助企业实施基于基础模型的定制应用程序的能力。
- 合作伙伴和生态系统:指厂商在本地市场和全球渠道分销合作伙伴及系统集成商的多样性,以及对全球开源生态系统的贡献。
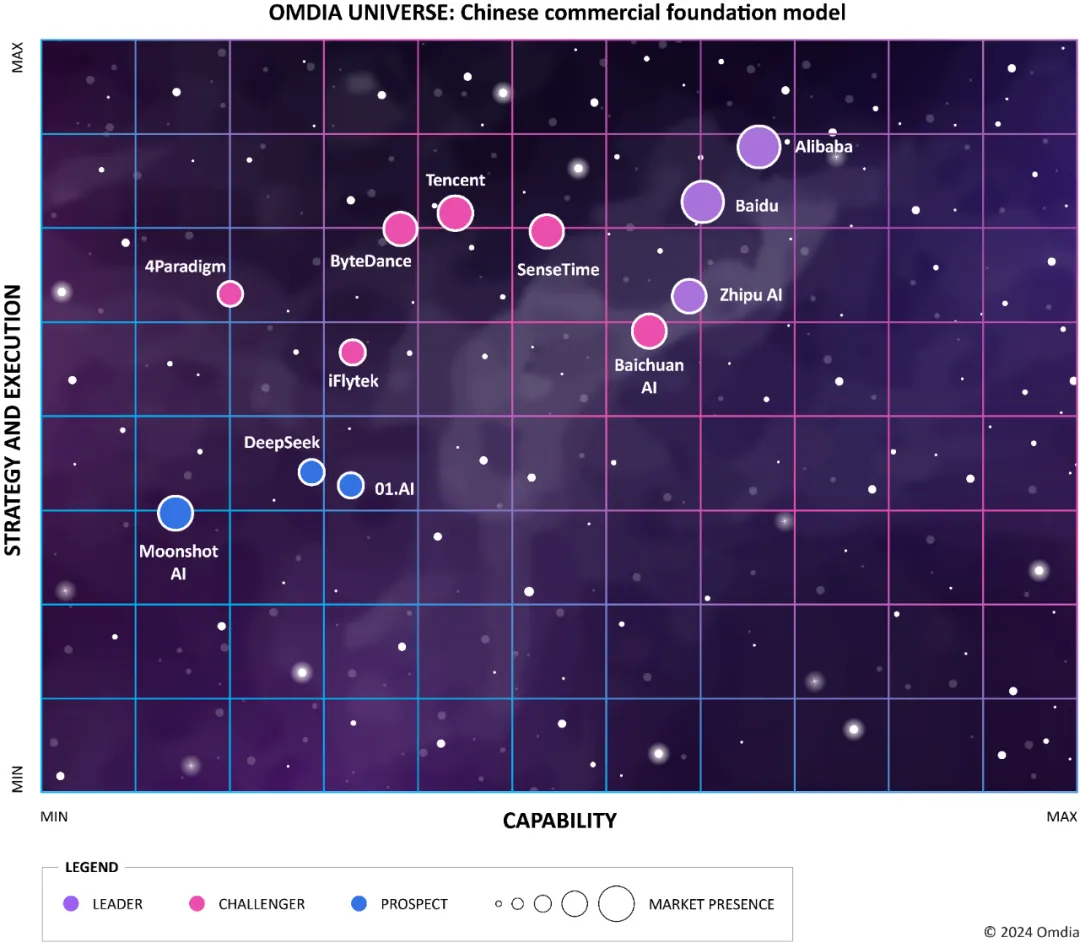
市场领先者必须拥有顶级的通用和特定领域任务性能。阿里、百度和智谱这些基础模型在能力、一致性和安全性方面都获得了高分。其中,阿里在通用任务执行能力上有着显著的能力,领先于其他领导者。相比之下,百度在某些特定领域任务执行能力有着卓越表现,智谱则是在基础知识能力的评测表现优异。
市场挑战者主要包括中国的云计算和人工智能巨头,它们拥有强大的基础设施和通用人工智能能力。它们并不缺乏开发强大基础模型的资源。相反,它们将重点放在选定的用例或专有解决方案上。其中最明显的例子就是腾讯。腾讯依托自身最新发布的混合专家模型的架构,将大模型结合到其用户广泛的软件应用中。
《Omdia中国大模型厂商竞争力排名报告》代表着 Omdia 对目前百模大战的一个主观判断。阿里、百度和智谱是目前的领先者,而腾讯和商汤等在背后虎视眈眈。云大厂依仗其云基础设施的优势在大模型时代大放光彩。其他厂商想在市场分一杯羹,就得依赖更显著得差异化和对细分赛道的深耕。














 [下载]LAT1482 STM32G0单线串口通信帧错误问题解析
[下载]LAT1482 STM32G0单线串口通信帧错误问题解析
