


 1860
1860
4.1 动态重构硬件加速器系统总体架构设计
动态重构硬件加速器架构最重要的特征体现在系统运行时能够利用动态重构技术,通过PS端主控制器通过加载新的可重配置文件,以此调用新运算算子IP核来完成新的图像预处理加速运算。本系统可以通过调用多个动态重构的加速器通过流水线方式组合成新的图像预处理硬件算法,并且能够通过调用和部署深度学习算法在DPU模块上,以满足系统运算、算法加速和不同环境下应用的需求。
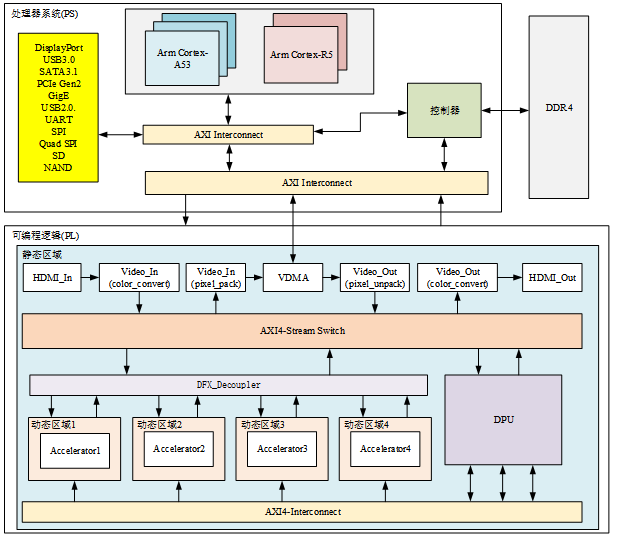
EDRCA-YOLO加速器的硬件系统架构框图
本文提出了一种可以部署YOLO算法的高效动态重构目标检测算法加速器架构(Efficient Dynamic Reconfigurable Target Detection Algorithm Accelerator Architecture for YOLO,EDRCA-YOLO),该加速器整体架构如图4-1所示。EDRCA-YOLO加速器系统在系统级层面,包含两个子系统,分别是视频图像预处理加速器系统和基于DPU的目标检测网络推理加速系统。而在硬件级层面,整个加速器分为处理器系统端(Processing System,PS)和可编程逻辑端(Progarmmable Logic,PL),并将PL端分为五个部分,分别是动态区域1、动态区域2、动态区域3、动态区域4和静态区域。
PL端的静态区域主要完成视频流数据的输入、视频帧传输以及输出,还有中断、时钟、复位信号的管理和对于动态区域的逻辑解耦,PL端与PS端的通信采用128位AXI4总线协议的总线,如S_AXI_HPC0_FPD、S_AXI_HPC1_FPD、S_AXI_HP0_FPD、S_AXI_HP1_FPD,以及32位的S_AXI_LPD、M_AXI_HPM0_LPD。其中S_AXI_HPC0_FPD、S_AXI_HPC1_FPD高性能接口提供了高性能计算(HPC)外设的AXI总线访问接口,其中FPD代表“Fixed Platform Domain”,而对应的M_AXI_HPM0_LPD接口是一种高性能主接口,并在低功耗域内访问PL端的主接口,其接口总线设置为32位,通过AXI Interconnect模块对PL端的动态重构模块和DFX_Shutdown管理器模块相连,作为传输控制命令信号的接口。S_AXI_HPC0_FPD、S_AXI_HPC1_FPD均为高性能接口通过与DPU模块相连,为DPU和PS端的处理器提供高速通信,而S_AXI_LPD为DPU与PS端处理器之间提供低速的AXI总线访问,使得主控制器能够发送控制命令,对DPU进行控制。S_AXI_HP0_FPD、S_AXI_HP1_FPD、S_AXI_HP2_FPD、S_AXI_HP3_FPD作为高性能的AXI总线从接口,接口设置为128位并与三个DFX_Shutdown管理器模块相连。DFX_Shutdown管理器模块用于在动态重构期间确保动态区域和静态区域之间的AXI总线接口的通信安全。当系统处于工作状态时,发送至可重配置模块的AXI通信任务以及从可重配置模块(RM)发出的AXI通信任务将会被终止,以确保系统不会因为RM的通信任务无法完成而造成系统死锁的状态,而当系统处于非工作状态时,通信任务按照先前的状态继续。EDRCA-YOLO系统架构中包含两个DFX_Shutdown管理器模块,分别与VDMA模块的M_AXI_MM2S接口和M_AXI_S2MM接口。
在信号管理上,系统利用时钟管理器Clocking Wizard IP进行时钟信号管理,利用中断管理器AXI Interrupt Controller IP对时钟信号和中断信号进行管理。EDRCA-YOLOv5s加速器共设置了三个初始时钟信号,分别是100MHz、200MHz和300MHz,分别为驱动静态区域的各模块,以及动态区域1、动态区域2、动态区域3和动态区域4的可重配置运算模块提供初始时钟,并通过Clocking Wizard IP 核对信号进行倍频处理,分别得到600MHz和300MHz的是时钟信号并与DPU IP核的dpu_2x_clk接口和m_axi_dpu_aclk接口连接。当一个中断信号被触发时,系统会保存当前的硬软件系统状态,并将控制权转移给负责处理中断事件的中断处理,然后系统恢复先前的程序状态,以便程序在中断发生前继续执行。复位信号则分为静态区域和动态重构区域,静态区域的时钟复位信号由处理器复位模块将系统复位信号同步到静态区域的时钟域,整个动态区域的时钟复位信号由单独的处理器系统复位IP核模块控制。此外在静态区域中为了确保EDRCA-YOLO加速器系统的硬件设计在运行中保持动态重构分区功能模块和静态逻辑功能模块之间不发生逻辑混乱的情况,本设计使用Decoupler模块对每个可重构模块做逻辑解耦处理,可以在重新配置期间对动态区域和和静态区域之间的逻辑进行隔离,并且在区域内使用DFX_Shutdown管理器模块管理AXI4-Lite、AXI4-Stream和AXI4总线接口,以此为加速器的运行提供一个安全的工作环境。
四个动态区域通过加载图像运算加速器负责EDRCA-YOLO加速器的图像预处理加速任务,因而需要动态重构加速器系统架构具备稳定和高带宽。故在动态区域构造可重构模块时,对可重构模块的接口进行专用化设计,各个信号接口和寄存器地址都是固定的,在VIVADO HLS开发工具中使用高层次编译语言(HLS)设计一个专用加速器模板,为每一个运算加速器生成统一的硬件接口,具体接口设置如4.2节的图4-2所示,其采用的32位地址位宽度的m_AXI4总线,该总线采用突发传输模式,适用大规模连续地址的数据读取和写入,最大运行带宽17GB/s,以满足图像处理算法部署在硬件上对运算速度的需求。
4.2 图像预处理算法硬件加速设计
由于军事战场的环境恶劣,移动端的自动目标识别系统所采集的图像往往会被阴天、雾霾天气、烟雾环境和高速移动带来的模糊所影响,使得系统拍摄的图像质量下降。由于FTDS数据集不能将军事战场上面临的所有环境都整合到一个数据集中,若目标检测网络输入图像的环境和训练集中的环境相差甚远,将会对目标检测系统的检测效果带来很大的影响,比如带来明显的精度下降。为了降低不利环境下对自动目标识别系统精度的影响,故本动态重构算法加速器系统在PL端增加了图像实时预处理环节,预先对采集的图像做图像增亮和去雾霾和烟尘的算法加速处理,之后再传输到以DPU IP核为运算核心的GSConv-YOLOV5s目标检测网络加速器子系统中做进一步的处理。
4.2.1 图像预处理算法
在实际的战地情况下,需要对不同的环境采用不同的图像处理算法,以适应不同的现场需求。通常遇到的环境情况有环境过暗、过亮、模糊、雾霾和烟尘,且考虑到本系统的硬件计算资源有限,适合采用基础算子通过本系统主控制端将各个算子调用组合为新的图像预处理算法,以节约硬件计算资源,故本系统对于这些环境下的图像增强处理算法和其组成算子,归纳为表4-1所示。其中,LUT(Look-Up Table)是颜色查找表算法,用于图像的亮度调节;add是图像加法算法,用于图像增强对比度;filiter2D是卷积滤波算法,用于对图像进行去噪和边缘的检测;rbg2gray是用于将图片由彩色转换为灰度的算法;gray2rgb是将图片由灰度转换成彩色的算法。

如表4-1所示,本系统采用的图像增强算法主要有伽马变换、基于拉普拉斯滤波的图像锐化和直方图均衡化算法。
(1)伽马变换算法,是一种基于灰度级的非线性图像增强算法,可以通过调整图像的灰度级分布来改变图像的对比度和亮度。伽马变换主要用于处理灰度图像,对于本系统所用三维彩色图像可以对每个颜色通道单独进行伽马变换,使得较暗的区域的亮度得到提升,而较亮的区域的亮度得到降低,经过伽马变换,图像整体的细节表现会得到增强。伽玛变换的数学表达公式如公式(4-1)所示。

式中:
r——灰度图像的输入值(原来的灰度值),取值范围为[0,1];
s——经过伽马变换后的灰度输出值;
C——灰度缩放系数,通常取1;
γ——伽马因子大小,控制了整个变换的缩放程度。
(2)基于拉普拉斯滤波的图像锐化算法,一种经典的图像增强算法,它通过增强图像的高频分量来使图像变得更加锐利,凸显图像中物体的边缘轮廓。但是拉普拉斯滤波算法对噪声比较敏感,因此本系统先通过高斯平滑算法去除图像中的高频噪声,再对相应的噪声进行抑制,然后采用3´3尺寸大小的拉普拉斯卷积核,对原始图像进行离散卷积运算得到高频分量图像,再通过叠加运算将原始图像和高频分量图像叠加,生成锐化后的图像。其中在叠加高频分量图像时,可以通过控制增益因子,以控制图像锐化程度。
(3)直方图均衡化算法,是一种用于提高图像对比度的数字图像处理技术,其通过图像的直方图将原始图像的像素值分布重新映射到一个均匀的分布上,从而使得图像中的雾霾和模糊效果得到一定程度的改善,使得图像更加清晰明亮。其表达式如式(4-2)所示。

式中:
L——灰度总数;
k——累计次数,k=0,1,2,…,L-1;
r——图像的灰度级数,
——各个灰度级治病像素在图像中出现的概率;
——图像中个灰度级中的像素个数;
M——图像高的像素数;
N——图像宽的像素数。
Sk——累计第K次的累计值。
4.2.2 可重构模块的接口设计

如图4-2所示,每个动态区域都对应着一个可重构模块,EDRCA-YOLO加速器架构的可重构模块(Reconfigurable Module,RM)有两条总线,它们分别是32位的AXI_Stream输入和输出数据总线和32位的S_AXI_Control命令总线。这两条总线都通过128位的系统总线与DDR4相连,通过地址寄存器即可调用可重构模块内部的加速器组对运算层并行加速。可重构模块的参考时钟为300MHz,由硬件平台的时钟通过内部PLL,输出控制时钟300MHz。系统的复位信号源来自FPGA外部的复位键。当系统上电后,硬件平台初始化DDR4控制器,并向复位模块发送复位信号,之后每个可重构模块和FPGA的外围设备就处于预备状态。
可重构模块根据不同的计算任务的需要,可在可重构模块内嵌不同规格和数量的图像处理运算加速器模块,为了提高可重构模块的集成度。当可重构模块分配到不同的重构区域时,需要遵循同一个重构区域的原则,即可重构模块占用的片上硬件资源数量应尽可能接近,以增强模块计算性能和减少硬件资源的浪费[25]。内嵌单个和两个的可重构模块模板顶层设计框图如图4-2所示,为了防止动态逻辑区域和静态逻辑区域的逻辑混叠让系统发生严重错误,故对可重构模块进行了解耦设计,在静态区域使用Decoupler模块对可重构模块的逻辑进行解耦。
4.2.3 预处理算法的IP核设计

图像预处理算法硬件加速核的设计在Vitis HLS(2020.2)开发工具上完成,并且通过调用Vitis视觉库的函数API接口加速硬件开发过程。其中Vitis视觉库提供了一种与OpenCV库函数类似的专用于FPGA的标准硬件函数库,并通过Vitis统一设计平台开发与部署应用。如表4-1所示,预处理算法所需算子有LUT、add、filter2D、GaussianBlur、rbg2gray、gray2rbg,均调用Vitis视觉库中对应的函数API接口。对于硬件加速核的IP核接口设计,以Filter2d算子为例,如图4-3所示,外设接口包含32位的AXI_Stream的输入与输出接口,时钟信号、复位信号和32位的s_AXI_Control接口,与可重构模块的外设接口设计相同。对于Filter2d算子顶层函数的设计,在HLS中综合的顶层函数是filter2d_accel( )函数:void filter2d_accel(stream_t& stream_in, stream_t& stream_out, short int filter[FILTER_SIZE*FILTER_SIZE], unsigned char shift, unsigned int rows, unsigned int cols)。其中的stream_in和stream_out为视频流的输入和输出;rows、cols分别为图像高度和宽度;FILTER_SIZE为卷积核尺寸;shift为移位步长。在该函数中,先通过xf::cv::AXIvideo2xfMat函数,将AXI_Stream数据类型的视频流数据转换成xf::cv::Mat数据类型,再调用Vitis视觉库中的xf::cv::filter2D函数,最后再通过xf::cv::xfMat2AXIvideo函数将xf::cv::Mat数据类型的视频流数据转换成AXI_Stream数据类型,之后通过Vitis HLS开发工具即可得到filter2d_accel 的IP核,其他算子的IP核设计过程与filter2d算子相同。根据上述表述,对图像预处理算子LUT、add、filter2D、rbg2gray、gray2rbg分别在Vitis HLS(2020.2)开发工具上进行设计并导出IP软核,并加载到Vivado(2020.2)开发工具的软核库中以备PL端的硬件系统设计使用。
4.3 基于Vitis AI的目标检测网络推理加速器方案

Vitis AI 集成开发环境框架图
基于Vitis AI的目标检测网络推理加速器方案是在XILINX公司的片上系统上部署深度学习网络推理的高效解决方案,并且通过Vitis AI的开发工具库可以依托Ubuntu Linux操作系统实现深度学习模型的网络优化、编译和部署[103]。如图4-4所示,Vitis AI的开发工具库支持Xilinx ZYNQ MPSoC系列的边缘嵌入式硬件平台和Xilinx Alveo系列的硬件加速卡。这些平台提供了高性能的计算资源,使得在这些硬件平台上通过Vitis AI开发工具库部署深度学习网络时可以获得很高的加速比。由图可知Vitis AI开发工具包包含AI优化器、AI量化器和AI编译器,在网络优化阶段,可以使用各种技术来减小网络的计算量和内存占用,如算法优化和剪枝,以最小的精度下降为代价以提高模型性能。除此以外算法优化部分还包括循环优化(展开、平铺和交换),以最大限度地提高片上存储器的数据流效率和缓存性能。为了提高系统数据吞吐量和减少延迟,最后的硬件架构设计包对于本文所提出的GSConv-YOLOv5s目标检测算法的硬件部署中需要较多运算量的图像前处理部分进行硬件并行加速设计,和合理的流水线并行设计与有效的内存管理。在网络编译阶段,可以选择使用Vitis AI提供的优化器来生成高效的硬件描述语言(Verilog HDL)代码,以便在硬件平台上实现网络推理。用户可以通过编写一些简单的脚本来自动化这些任务,从而简化整个流程。
论文中所采用的开发流程包括Vitis AI和PYNQ-Kria软硬协同框架。首先,通在Ubuntu 18.04的Linux操作环境下部署Vitis AI集成开发环境,用于将网络训练阶段得到的模型参数文件作为输入。然后在通过在Docker虚拟环境中采用PyTorch深度学习框架以及Vitis AI开发工具包来构建KV260硬件平台匹配的编译环境,并通过AI优化器将网络模型参数文件进行网络优化,还通过AI量化器将32位浮点型数据量化为8为整数定点型数据,再通过AI编译器构建出匹配KV260硬件开发平台的硬件部署文件。最后将文件部署在在KV260上事先安装好的PYNQ-Kria软硬协同框架的PetaLinux操作环境中,使用C++和Python调用Vitis AI集成开发环境下生成的硬件部署文件,来加载调用DPU完成网络推理加速任务。
4.3.1 网络压缩
网络压缩是通过减少模型参数的数量来减小模型大小的一种技术。可以使用剪枝和量化等技术来实现。其中,剪枝技术可以通过删除模型中不必要的连接来减少模型参数的数量,进一步提高建模的准确性和可靠性。虽然FPGA可以有效地处理定点型数据,但无法满足浮点数据计算所需的大量存储空间。因此,为了提高网络模型的性能,必须对其实行参量缩小,这一过程基本上包括参量剪枝和参数量化两个步骤。使用Vitis AI工具,可以有效地将参量缩小到图4-4中的形式。
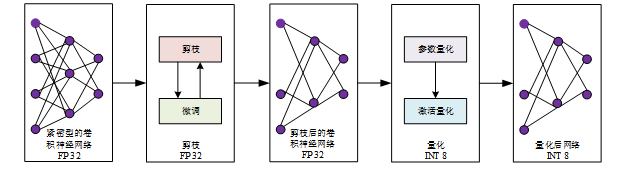
网络压缩流程图
一般来说,未经裁剪的卷积神经网络采取紧密型网络连接方式,当中含有大批权重值极低的网络连接分支,这些网络连接分支占用巨量存储和计算资源,但对网络性能的影响却很小。因此,通过参数剪枝技术,可以有效地去除权值极低的网络连接,从而减少网络参数量。在Vitis AI开发工具中,AI优化器可以通过不断重复的网络剪枝操作,将网络参数量减少到最小,从而达到最佳的运行速度,同时保证精度损失可接受。为了达到最佳效果,可以在每两轮剪枝期间加以微调,即经过几轮重训练,以达到5倍以上的压缩率。然而,剪枝性能与网络模型密切相关,不同的网络模型会产生不同的剪枝效果。
剪枝后的网络模型参数依然是32位浮点型数据,但是在将其送往FPGA执行加速运算之前,必须将其转化为8位定点型数据,这一过程被称之为参数量化。比如,8位定点量化可以将32位的浮点数取最近似的8位整数,从而将参数信息压缩至原来的1/4,以便更好地描述模型的特征。Vitis AI开发工具中的AI量化器可以有效地定量CNN模式,它可以将原始网络冻结,生成序列图GraphDef,接着从一分组无标记的数据集中抽取图像,经过定量校准,最后对网络系统中的卷积层、池化层等32位的浮点型参数加以定量量化,从而大大提高了量化后网络模型的准确性和可靠性,而且可以有效地减少精度损失,从而提升模型的性能和可靠性。最后,加入量化微调步骤,通过小批次的重训练让定点参数进一步收敛,从而避免过大的精度损失。
4.3.2 网络编译

网络编译是一个非常重要的步骤。网络编译的目的是将训练好的深度学习模型转化为能够在加速器上运行的代码。在Vitis AI中,可以使用Xilinx的DNNDK工具对深度学习模型进行编译。Vitis AI的网络编译技术主要包括两个方面:模型转换和模型优化。模型转换是将训练好的深度学习模型转换为能够在加速器上运行的代码。Vitis AI提供了多种模型转换工具,包括DNNC(Deep Neural Network Compiler)、DNNDK(Deep Neural Network Development Kit)和VART(Vitis AI Runtime)。这些工具可以将模型从不同的框架(如TensorFlow、PyTorch、Caffe和ONNX)转换为可以在加速器上运行的代码。模型优化是指对深度学习模型进行优化,以提高其性能和功效效率。在Vitis AI中,有多种模型优化技术可供选择,包括剪枝和量化、数据重排和内存对齐、层次并行、数据流。其中剪枝可以减少模型的大小和复杂度,从而提高推理速度。量化可以将高精度的浮点数转换为低位宽的定点数,从而减少存储和计算需求;重排数据可以减少内存带宽的需求,从而提高性能。内存对齐可以使数据存储在连续的内存位置上,从而提高缓存效率;层次并行可以将模型分成多个子模型,以在多个FPGA核心上并行执行,从而提高性能;数据流可以将模型分成多个流水线阶段,以最大化处理器的利用率,从而提高性能。
4.4 小结
本文重点描述了动态重构加速器系统架构EDRCA-YOLO的详细设计。首先,对介绍了动态重构硬件加速器系统总体架构的设计。然后,阐述了图像预处理算法及其硬件加速设计,详细描述了可重构模块和图像预处理算法的IP核接口设计。最后,阐述了基于Vitis AI的目标检测网络模型推理加速器方案及网络压缩和网络编译的步骤。

 下载ECAD模型
下载ECAD模型




