


 2152
2152
1. 方案背景和挑战
Apache Spark,作为当今大数据处理领域的佼佼者,凭借其高效的分布式计算能力、内存计算优化以及强大的生态系统支持,已牢固确立其在业界的标杆地位。Spark on Kubernetes(简称K8s)作为Spark与Kubernetes这一领先容器编排平台深度融合的产物,不仅继承了Spark的强大数据处理能力,还充分利用了Kubernetes在资源管理、服务发现和弹性伸缩方面的优势,正逐步引领大数据处理迈向更加灵活、高效的新纪元。
与此同时,随着云计算技术的飞速发展,NVMe/TCP云盘作为一种创新的高性能存储解决方案,凭借其在低延迟、高吞吐量以及易于集成到现代云架构中的特点,日益受到大规模数据中心和云环境用户的青睐。这种存储方案通过TCP/IP协议实现远程NVMe设备的直接访问,极大地拓展了数据存取的边界,但也随之带来了特定的技术挑战。
具体而言,NVMe/TCP云盘在利用TCP/IP协议进行数据交互时,不可避免地涉及到了复杂的数据包处理流程,包括用户态与内核态之间的频繁数据拷贝、网络报文的接收、峰值流量的处理以及协议栈的深入解析等。这一系列操作大幅增加了CPU的负担,尤其是在高并发、大数据量场景下,大量CPU资源被非业务核心的数据包处理工作所占用,导致CPU资源利用率低下,甚至成为性能瓶颈。
当Apache Spark试图挂载并利用NVMe/TCP云盘进行大规模数据处理时,上述挑战便显得尤为突出:
1、Spark作业在执行过程中,若频繁遭遇CPU资源被TCP/IP协议栈处理所挤占的情况,不仅会直接限制Spark任务的处理速度,还可能导致任务执行延迟增加,进而影响整个数据处理流水线的吞吐率和效率。
2、由于CPU资源的争夺,Spark原本有望进一步提升的磁盘I/O性能也受到了限制,难以充分发挥NVMe/TCP云盘应有的高性能潜力。
为了解决Spark在挂载NVMe/TCP云盘时面临的CPU资源占用过高和磁盘吞吐性能受限的问题,亟需探索并实施一系列优化策略和技术方案。这可能包括但不限于:采用更高效的数据传输协议或技术(如RDMA),以减少CPU在数据拷贝和网络处理上的负担,提升数据传输性能;优化Spark作业的调度与执行策略,以更加合理地分配CPU资源;以及针对NVMe/TCP云盘特性进行专门的性能调优,如调整TCP窗口大小、优化网络队列配置等。
RDMA技术允许数据在远程主机的内存之间直接传输,无需经过CPU处理,从而极大地降低了数据传输的延迟并减少了CPU的负载。这一特性直接解决了Spark和Kubernetes集群中,尤其是在使用NVMe-oF云盘时,因网络传输效率低下而可能导致的性能瓶颈问题。
本方案通过DPU实现NVMe/RDMA的云盘挂载,从而提升Spark在云环境下处理大数据时的整体性能和效率。
2. 整体方案概述
本方案采用云原生架构,Spark采用Spark on Kubernetes部署模式,并且引入DPU为集群之上的容器提供存储服务的卸载和加速,融合了云原生架构与高性能存储的优势。方案整体架构如下图所示:
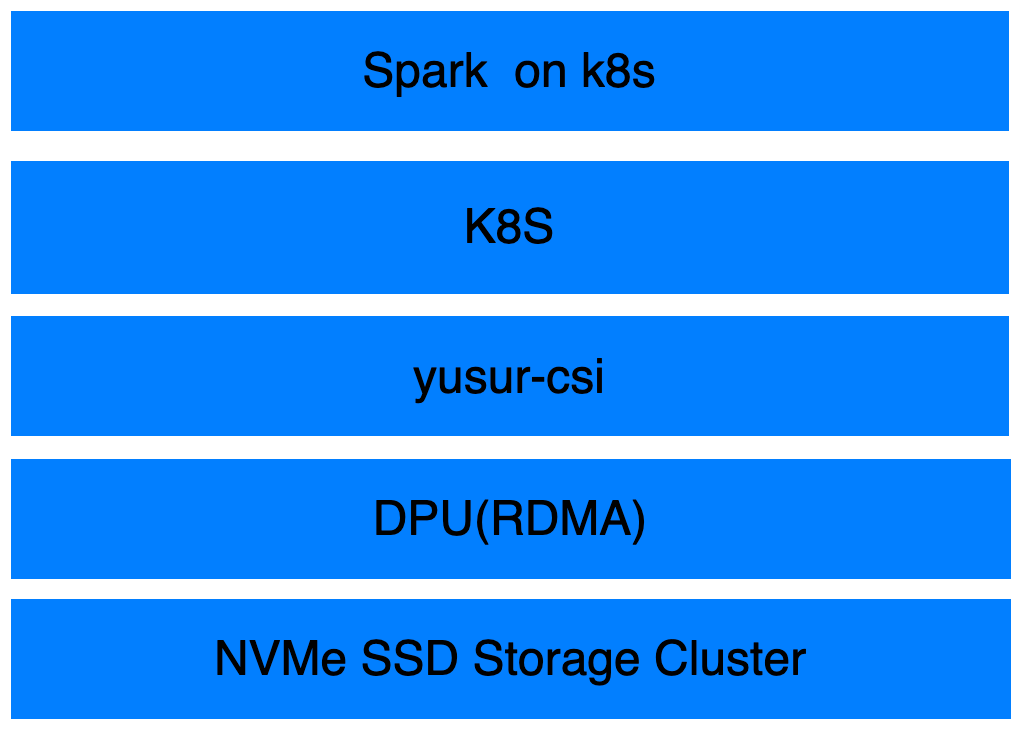
l 存储集群把NVMe存储设备以裸盘方式部署,计算节点通过硬件模拟向宿主机提供标准的nvme/virtio块设备,对存储协议的处理都卸载到DPU,提供硬件加速的NVMe over RDMA能力。
l K8S平台通过yusur-csi存储插件提供基于DPU的云盘挂载能力。
l 将Spark应用部署在K8S集群之上,Spark Pod挂载DPU硬件加速的NVMe/RDMA云盘,以更低的资源消耗获得更高的读写效率。
3. 测试方法和结果
3.1. 软件环境
软件包/工具/数据集列表
| 名称 | 版本 | 来源 | 备注 |
| Spark | 3.4.2 | 社区开源项目 | 开源大数据处理框架 |
| Java | 17.0.10 (Eclipse Adoptium) | 开源项目Spark自带 | Spark镜像内置的依赖环境 |
| containerd | 1.6.21 | 社区开源项目 | 容器运行时 |
| Kubernetes | v1.26.5 | 社区开源项目 | 开源容器编排框架 |
| yusur-csi | V6.0 | 自研 | Kubernetes存储插件,为裸金属提供云盘挂载功能。 |
3.2. 测试方案
Spark SQL是Spark开发常用的编程接口,本方案使用Spark SQL运行一个聚合查询,SQL语句如下:
| select count(1) from tblong where id=1 |
Spark使用Spark on Kubernetes部署模式,为了数据加载的完整性,关闭Spark SQL的谓词下推机制。输入数据是Parquet文件,包含一个Long类型的数据列,所有输入文件大小之和是45G。
Spark 分配4个Executor(Pod),每个Executor分配8个core,Spark核心参数如下
| $SPARK_HOME/bin/spark-submit
--master k8s://https://10.0.151.186:6443 --deploy-mode cluster --driver-cores 4 --driver-memory 40G --executor-cores 8 --executor-memory 40G --num-executors 4 --conf spark.executor.memoryOverhead=2G --conf spark.dynamicAllocation.enabled=false --conf spark.sql.parquet.filterPushdown=false --conf spark.kubernetes.namespace=spark --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.container.image=harbor.yusur.tech/bigdata/spark:spark3.2.0-hadoop3 |
3.3. 节点网络拓扑
测试环境包含一个存储节点和一个计算节点,各有一个DPU加速卡,两个节点之间通过100G交换机连接。测试环境节点网络拓扑如下图所示:
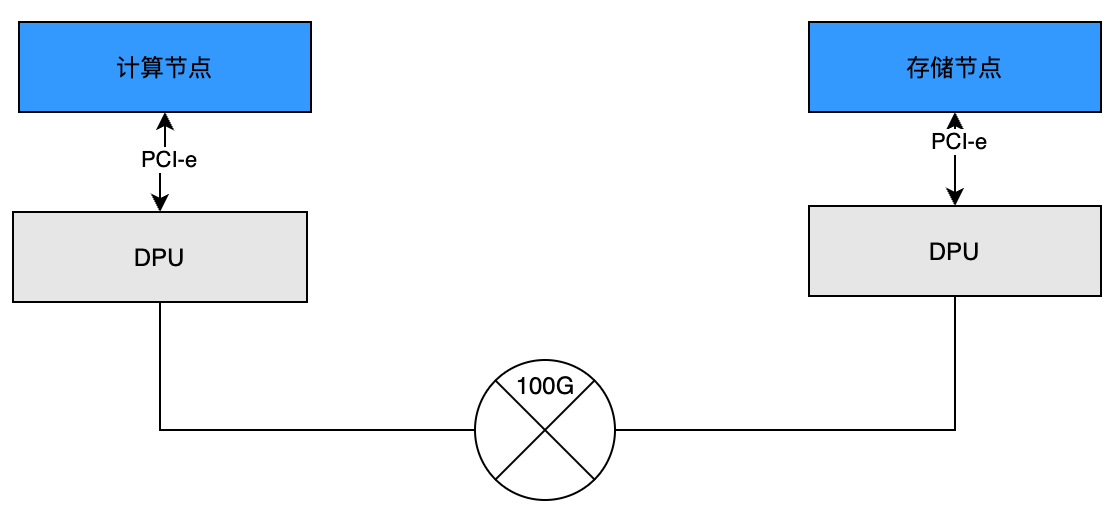
对于NVMe/TCP云盘,DPU使用TCP协议连接存储服务,不卸载存储协议的处理,这种情况下,DPU充当普通网卡。
对于NVMe/RDMA云盘,DPU使用RDMA协议连接存储服务,把存储协议卸载到DPU硬件。
3.4. 关注指标
本方案重点关注CPU资源的使用率,包括系统内核CPU使用率和用户态CPU使用率。
| 指标名称 | 指标描述 |
| 数据加载时间(单位:秒) | 对于Spark SQL任务,对应Scan算子时间 |
| E2E时间(单位:秒) | 从数据加载开始到结果输出结束的时间间隔 |
| 磁盘吞吐量(单位:MB/s) | 磁盘在单位时间内能够读写的数据总量,通过fio工具测试 |
| 内核态CPU使用率 | 主机CPU运行在用户态的时间占比,通过top命令采集 |
| 用户态CPU使用率 | 主机CPU运行在用户态的时间占比,通过top命令采集 |
3.5. 测试结果
3.4.1性能数据
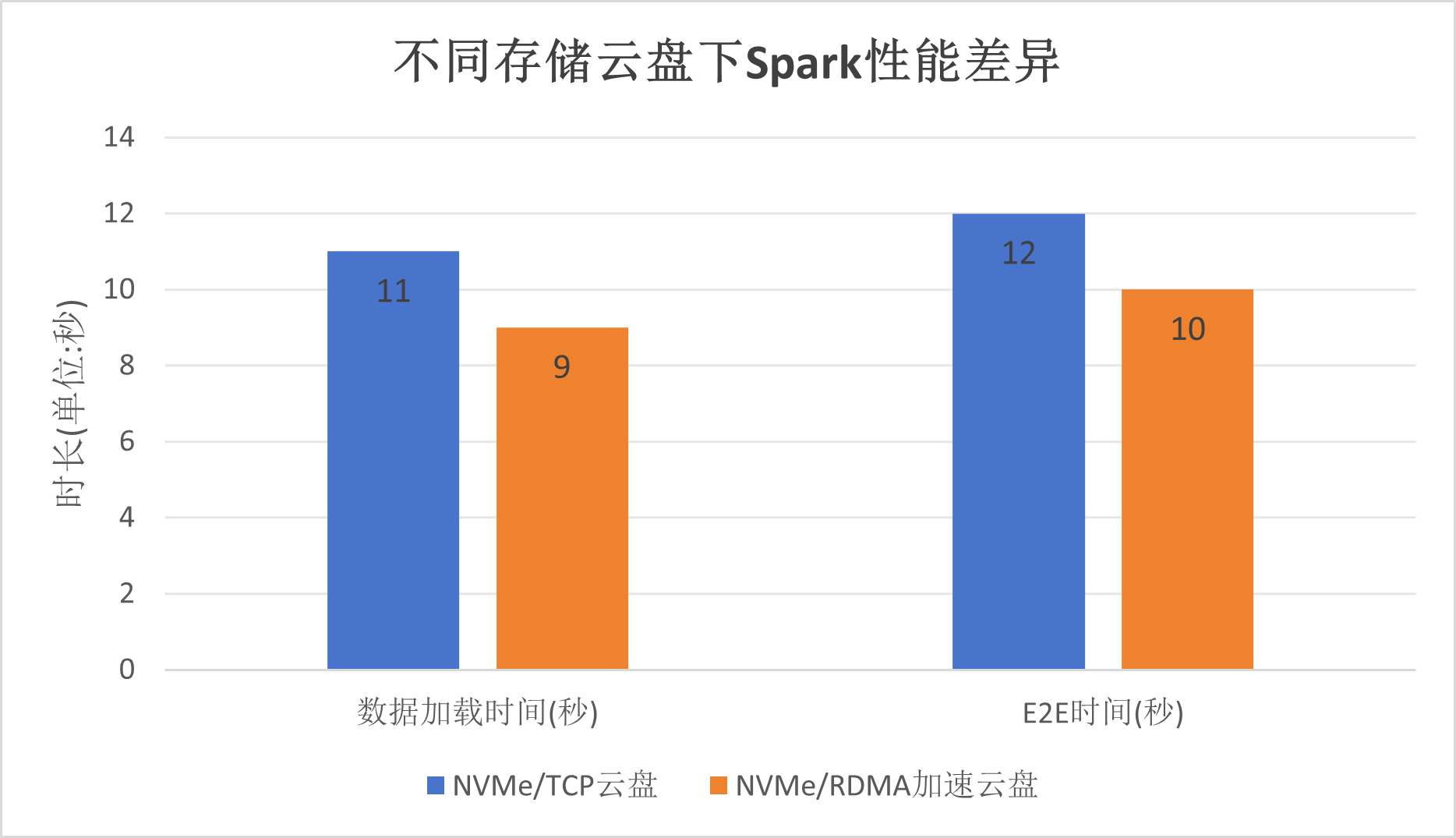
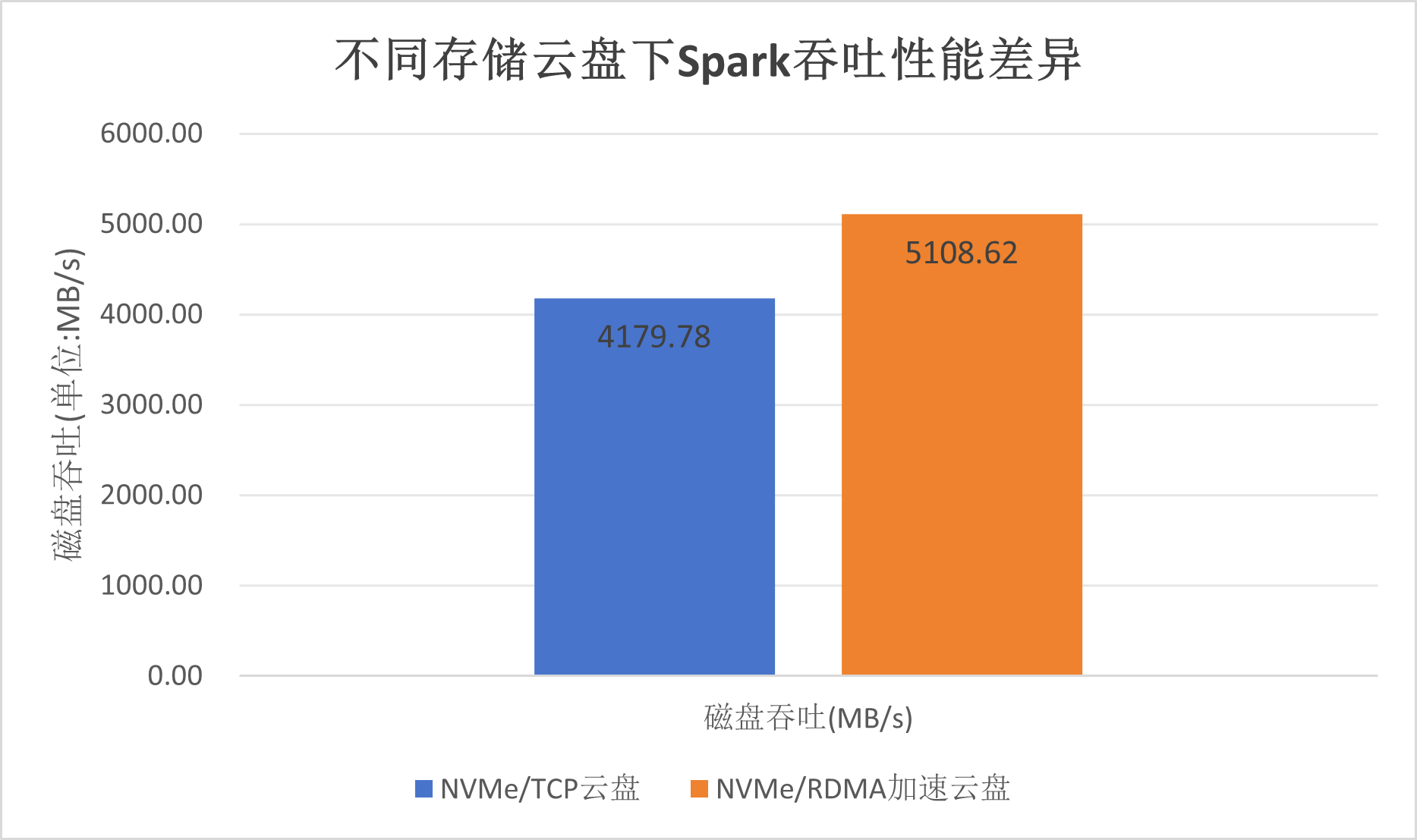
Spark 分配4个Executor(Pod),每个Executor分配8个core。 相比于挂载云盘,挂载NVMe/RDMA云盘,Spark数据吞吐性能提升22.2%,数据加载时间缩短18.2%。
不同存储云盘下,数据加载时间及E2E时间对比如下图所示:
Spark磁盘吞吐性能对比如下图所示:
具体数据见下表:
| 对比指标 | NVMe/TCP云盘 | DPU NVMe/RDMA云盘 |
| 数据加载时间(秒) | 11 | 9 |
| E2E时间(秒) | 12 | 10 |
| 磁盘吞吐(MB/s) | 4179.78 | 5108.62 |
3.4.2资源使用数据
运行过程资源监控图如下图所示:
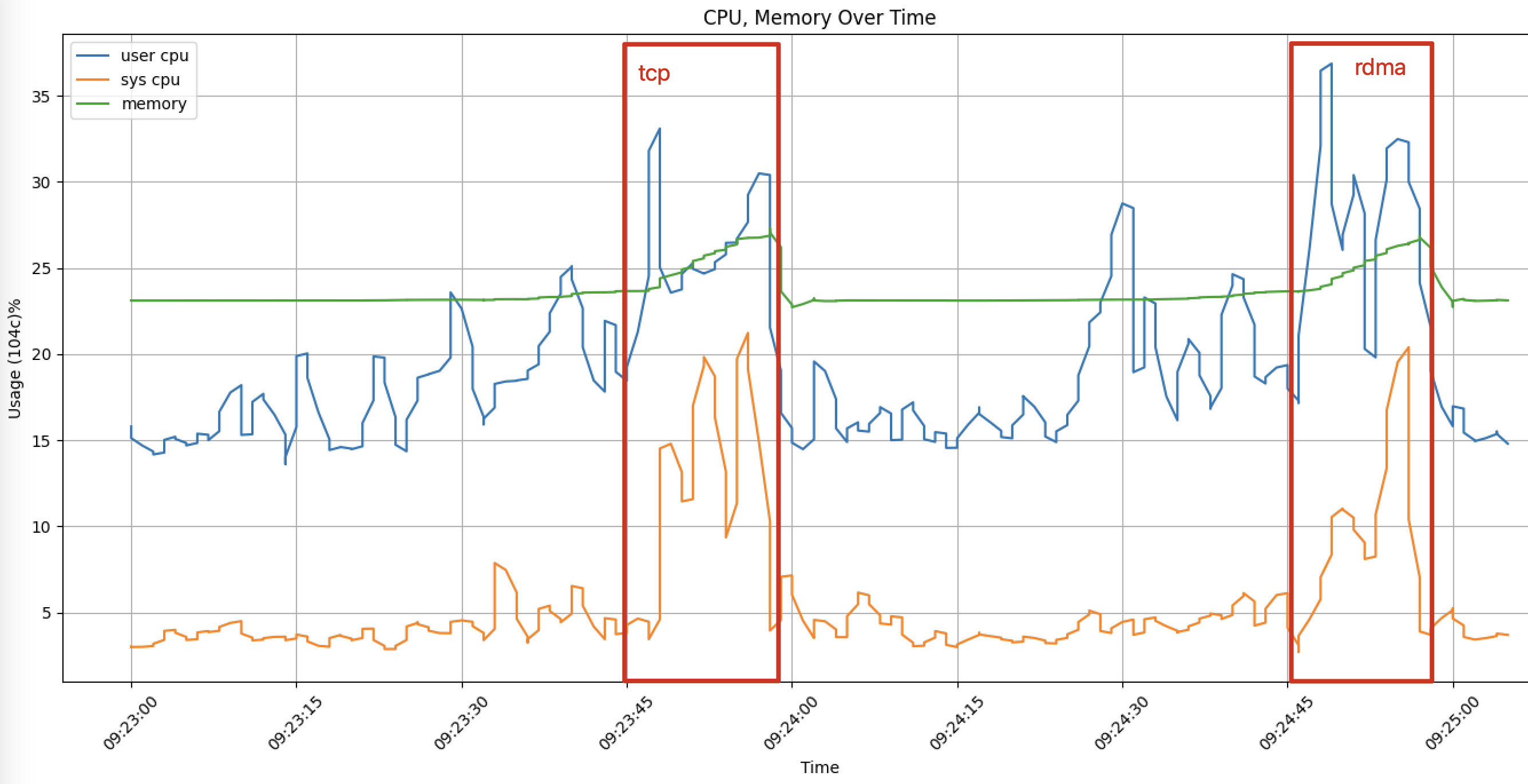
从监控图发现内存使用波动较少,本方案内核态CPU使用率平均减少17.14%,用户态CPU使用率平均增加7.39%,平均CPU资源消耗如下图所示:
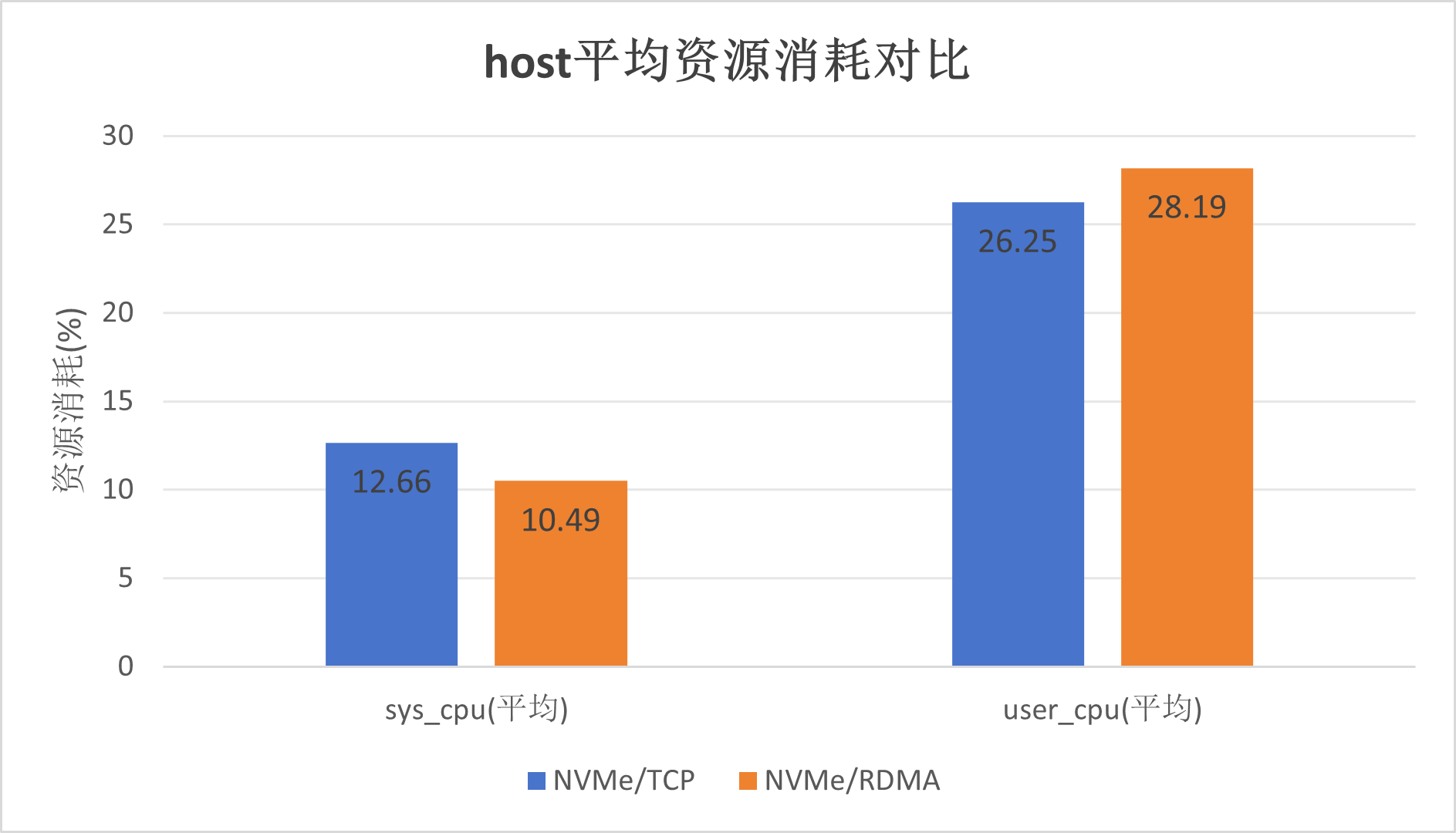
平均CPU资源占用数据如下表所示
| 存储云盘类型 | sys_cpu(均值) | user_cpu(均值) | 合计 |
| NVMe/TCP云盘 | 12.66% | 26.25% | 38.91% |
| NVMe/RDMA云盘 | 10.49% | 28.19% | 38.68% |
3.4.3测试数据分析
本次试验通过测试Spark SQL读取Parquet文件做聚合计算,分配4个Executor(Pod),每个Executor分配8个core,也就是说实际运行过程中并行度为32。
相比于挂载NVMe/TCP云盘,挂载NVMe/RDMA云盘可使Spark数据吞吐性能提升22.2%,数据加载时间缩短18.2%。
从运行过程中的资源监控图来看,挂载NVMe/RDMA云盘,Spark消耗更少的内核态CPU资源。内核态CPU资源使用率减少17.14%,但数据加载性能更高,因此占用了更多的用户态CPU资源。这与RDMA本身的特点是相符的,RDMA 将协议栈的实现下沉至DPU硬件,绕过内核直接访问远程内存中的数据。
综合用户态CPU和内核态CPU使用情况,不管是挂载NVMe/TCP云盘还是挂载NVMe/RDMA云盘,Spark的资源消耗都在一个水平上,但是挂载NVMe/RDMA云盘时,Spark运行速度更快,对资源占用时间更短,所以整体来看,本方案事实上节省了系统CPU资源。
4. 优势总结
本方案通过引入DPU(数据处理单元)实现NVMe/RDMA云盘挂载,以优化Spark在云环境下处理大数据的性能和效率,其优势可以总结为以下几点:
1、显著提升数据吞吐性能:
采用NVMe/RDMA技术相比于传统的NVMe/TCP,能够大幅提升数据在云环境中的传输速度。本方案测试结果显示,数据吞吐性能提升了22.2%,这意味着Spark作业在处理大规模数据集时能够更快地读取和写入数据,从而显著减少数据处理的总时间。
2、大幅缩短数据加载时间:
数据加载是大数据处理流程中的关键瓶颈之一。通过NVMe/RDMA云盘的挂载,数据加载时间缩短了18.2%,这对于需要频繁访问大量数据集的Spark应用来说尤为重要,可以显著提高应用的响应速度和整体效率。
3、减少非业务负载对CPU资源的占用:
NVMe/RDMA技术通过减少数据传输过程中对CPU的依赖,将数据传输的负载从主机CPU转移到DPU上。这不仅降低了主机CPU的负载,还使得CPU资源能够更多地用于数据处理等核心业务逻辑,从而提升整体的系统效率和性能。
4、优化资源利用率:
由于数据加载和传输速度的提升,Spark作业可以更快地完成数据处理任务,从而提高了云资源的利用率。云环境中的资源(如CPU、内存、存储)通常按使用量计费,因此更快的处理速度意味着更低的成本。
综上所述,本方案通过引入DPU实现NVMe/RDMA云盘挂载,为Spark在云环境下处理大数据提供了全面的性能优化,显著提升了数据吞吐性能、缩短了数据加载时间、减少了CPU资源占用,并优化了系统的资源利用率。
本方案来自于中科驭数软件研发团队,团队核心由一群在云计算、数据中心架构、高性能计算领域深耕多年的业界资深架构师和技术专家组成,不仅拥有丰富的实战经验,还对行业趋势具备敏锐的洞察力,该团队致力于探索、设计、开发、推广可落地的高性能云计算解决方案,帮助最终客户加速数字化转型,提升业务效能,同时降低运营成本。

 下载ECAD模型
下载ECAD模型


