


 2918
2918
1. 方案背景
1.1. KubeVirt介绍
随着云计算和容器技术的飞速发展,Kubernetes已成为业界公认的容器编排标准,为用户提供了强大、灵活且可扩展的平台来部署和管理各类应用。然而,在企业的实际应用中,仍有许多传统应用或遗留系统难以直接容器化,通常采用传统的虚拟化技术来支撑。因此,企业需要同时运行容器和虚拟机的混合云或私有云环境,以便开发者和运维人员方便地管理和维护这两种类型的工作负载,这促使了KubeVirt项目的诞生。
KubeVirt是一个开源项目,由Red Hat、IBM、Google、Intel和SUSE等多家公司共同推动和贡献。该项目旨在通过Kubernetes来管理和运行虚拟机(VMs),使虚拟机能够像容器一样被部署和消费。KubeVirt扩展了Kubernetes的API,增加了VirtualMachine和VirtualMachineInstance等自定义资源定义(CRDs),允许用户通过YAML文件或kubectl命令来管理虚拟机,极大简化了虚拟机的创建、更新、删除和查询过程。
KubeVirt 的价值主要体现在统一的资源管理,使得 Kubernetes 能够同时管理容器和虚拟机,为用户提供统一的资源管理界面。这消除了容器和虚拟机之间的管理界限,提高了资源管理的灵活性和效率,为用户提供了更多的选择,确保了应用的完整性和性能,促进了传统应用的现代化和云原生转型。
1.2. 问题与挑战
KubeVirt在提供虚拟机实例的部署和管理能力时,会面临着诸多网络和存储方面的问题与挑战。
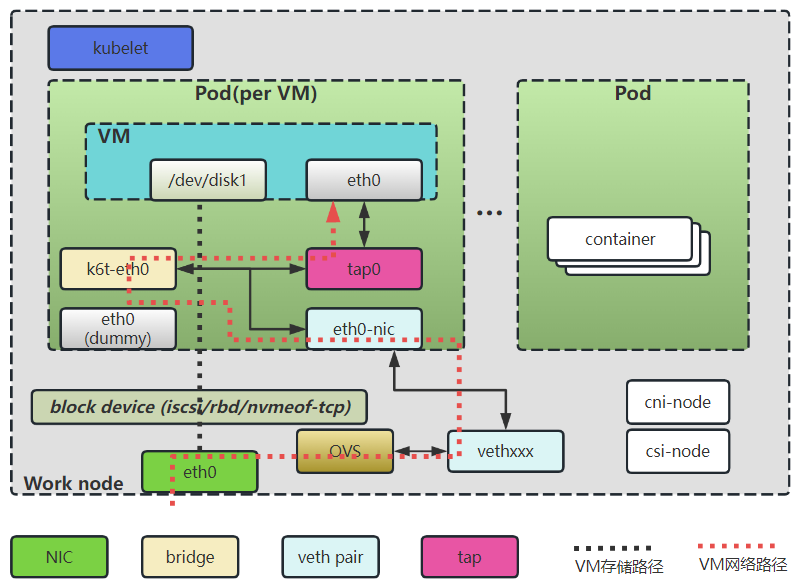
如上图所示,构建KubeVirt虚拟机环境需要先启动一个Pod,在Pod中构建虚拟机的运行环境。
在无DPU/SmartNIC的场景下,Pod通过Kubernetes CNI创建的veth pair连接网络, 虚拟机为了对接CNI接入Pod中的网卡(eth0-nic),传统的虚拟机环境是需要创建网桥设备(k6t-eth0),网卡(eth0-nic)连接到网桥设备,然后再创建TAP设备(tap0),TAP设备(tap0)的一端连接到网桥设备,另外一端连接虚拟机,这样虚拟机网络打通了与主机上OVS的网络连接。在上图中可以看到,虚拟机的网络路径为:ovs --> vethxxx --> eth0-nic --> k6t-eth0 --> tap0 --> eth0。
此外,Pod的存储是通过Kubernetes CSI挂载到主机上云盘设备,传统网络存储都是基于TCP的iscsi/rbd/nvmeof-tcp提供的远端存储,在KubeVirt虚拟机环境中,远端存储被CSI挂载到Pod中直接被虚拟机使用。
如上所述,在KubeVirt虚拟机环境中,网络和存储的配置面临着一系列问题与挑战:
1、网络路径复杂且冗长:
在无DPU/SmartNIC的场景下,虚拟机网络路径包含了多个虚拟设备(如veth pair、网桥、TAP设备等),这使得网络路径复杂且冗长,这种长路径不仅增加了数据包处理的复杂度,提升了运维排障难度,还可能导致更高的延迟和性能瓶颈。
2、资源消耗高:
路径中过多的网络虚拟设备需要CPU和内存资源来处理数据包的转发和路由。这些资源消耗在高负载场景下尤为显著,可能导致宿主机资源紧张,整体资源利用率低。
3、网络性能低下:
由于网络路径复杂和资源消耗高,虚拟机的网络性能往往受到限制,在高吞吐量或低延迟要求的应用场景中,这种性能问题尤为明显。
4、基于TCP的远端存储存在性能瓶颈:
使用iSCSI、RBD(Ceph RBD)或NVMe-oF(TCP模式)等基于TCP的远端存储方案时,数据需要经过网络协议栈的处理,这增加了CPU的负担并可能导致较高的延迟,这些存储协议没有硬件加速的支持,因此在高I/O需求下性能表现不佳。
2. 方案介绍
2.1. 整体方案架构
为了应对KubeVirt虚拟机在网络与存储方面所遭遇的问题与挑战,本方案创造性地集成了DPU(数据处理单元)硬件,以下将详细阐述基于DPU卸载加速技术的KubeVirt虚拟机网络及存储解决方案的架构。
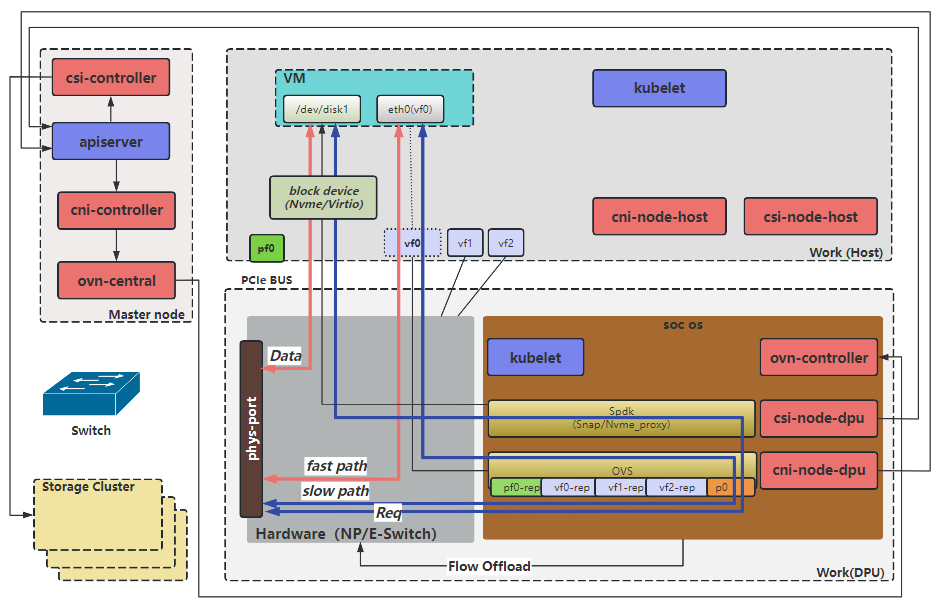
如上图所示,基于DPU改造后后,网络和存储都是从DPU卡接入的,DPU硬件支持数据包的高速处理和RDMA(远程直接内存访问)技术,提供对网络和存储的硬件加速能力。同时DPU集成了CPU核心,能够将OVS控制面卸载到DPU中,从而减少Host节点CPU的负载。为了把DPU接入K8S平台,需要使用基于DPU的CNI和CSI,用于对接DPU的网络和存储功能。
- cni-controller:该组件执行kubernetes内资源到ovn资源的翻译工作,是SDN系统的控制平面,也相当于ovn的cms云管理系统。其监听所有和网络相关资源的事件,并根据资源变化情况更新ovn内的逻辑网络。
- cni-node:为虚拟机提供虚拟网卡配置功能,调用 ovs 进行配置。
- csi-controller:用于创建volume和nvmeof target;针对pvc,调用第三方的controller创建卷,创建快照和扩容等。
- csi-node:为虚拟机所在容器提供云盘挂载功能,最终通过spdk 进行配置,spdk 通过 pcie 给虚拟机所在容器模拟磁盘。
2.2. 方案描述
2.2.1. 核心资源
KubeVirt的核心资源主要是虚拟机资源,围绕虚拟机生命周期管理定义了其他的CRD资源,包括:
- virtualmachines(vm): 该结果为集群内的VirtualMachineInstance提供管理功能,例如开机、关机、重启虚拟机,确保虚拟机实例的启动状态,与虚拟机实例是1:1的关系,类似与spec.replica为1的StatefulSet。
- Virtualmachineinstances(vmi):VMI类似于kubernetes Pod,是管理虚拟机的最小资源。一个VirtualMachineInstance对象即表示一台正在运行的虚拟机实例,包含一个虚拟机所需要的各种配置。
2.2.2. 网络
KubeVirt以multus(OVS)+sriov的网络接入方式使用DPU,虚拟机网络的接入定义需要分成2部分:
- 节点的基础网络如何接入pod中。
- pod中的网络如何接入虚拟机中。
2.2.2.1. 网络控制面
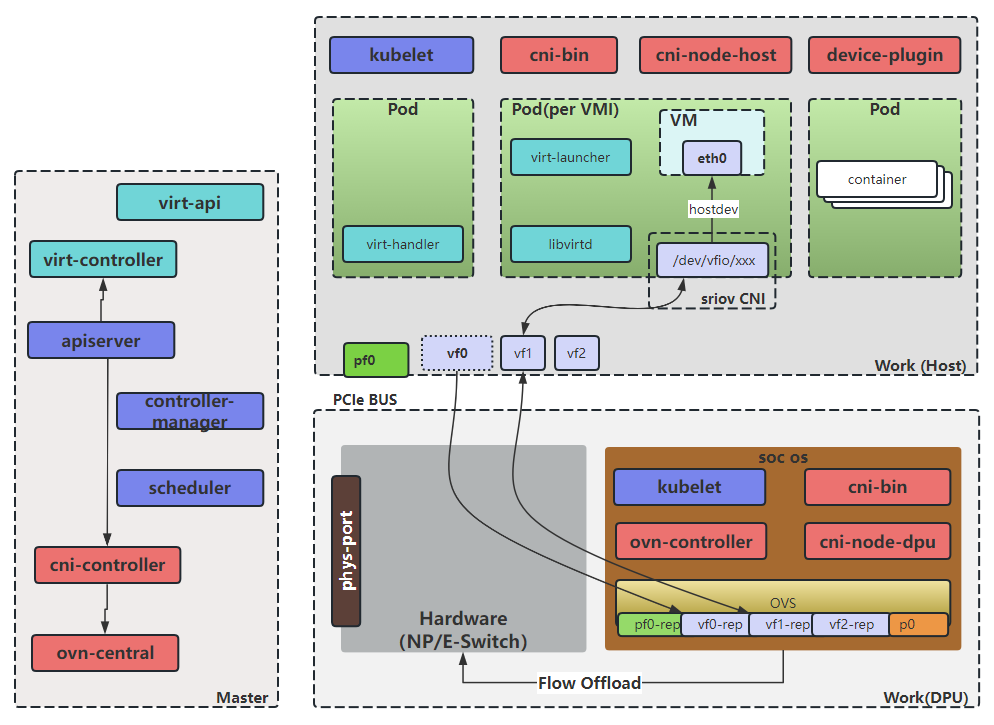
如上图所示,将master节点,dpu卡,Host都作为node加入k8s集群,这些node上运行着DPU CNI的相关组件,下面分别进行介绍:
- ovn和ovs为转发面核心组件,共同提供SDN(软件定义网络)能力,其中ovn负责网络逻辑层面的管理和抽象,而ovs则负责实际数据包的转发和处理。
- cni-controller,该组件执行kubernetes内资源到ovn资源的翻译工作,是SDN系统的控制平面,也相当于ovn的cms云管理系统。其监听所有和网络相关资源的事件,并根据资源变化情况更新ovn内的逻辑网络。
- cni-bin,一个二进制程序,作为kubelet和cni-node之间的交互工具,将相应的CNI请求发给cni-node执行。
- cni-node,该组件作为一个DaemonSet运行在每个节点上,实现CNI接口,并监听api-server配置本地网络,其会根据工作模式做相应的网络配置,工作模式有以下几种:
1)Default模式: cni-node的默认工作模式,master和带SmartNic卡的Host节点中的cni-node均工作于此模式。在该模式下,会对安置在其上的容器配置完整的虚拟网络配置,如容器网络和ovs网络。
2)DPU模式:DPU节点中的cni-node工作于此模式。在该模式下,会对安置在DPU内的容器配置完成的虚拟网络配置。而对安置在其Host的容器,会配置ovs网络。
3)Host模式:带DPU卡的Host节点中的cni-node工作于此模式。在该模式下,只会去配置容器网络,而对应的底层网络如ovs网络,则交由其对应DPU上工作在DPU模式的cni-node完成。
2.2.2.2. 网络数据面
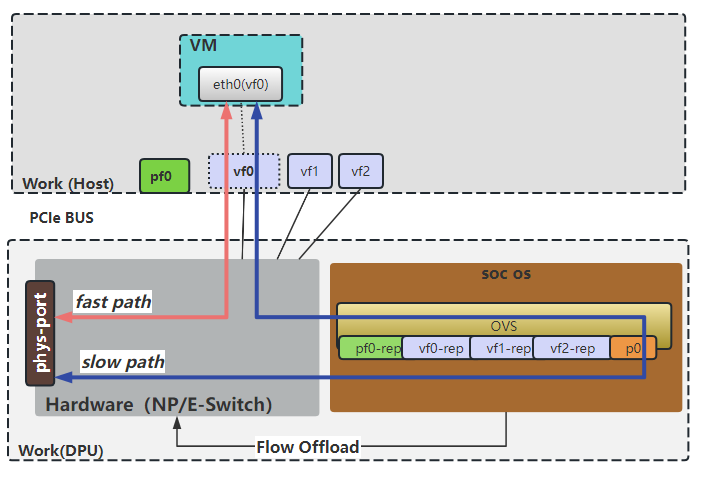
基于DPU卸载与加速的高性能网络,其核心技术的数据面原理如上图所示。基于ovn/ovs提供SDN的能力,并基于DPU提供的SRIOV及流表卸载功能,对网络进行了加速,为云上业务提高了高性能网络。
2.2.3. 存储
Kubevirt并没有重新定义存储,存储还是由Kubernetes定义的,所以还是沿用CSI规范创建/挂载/删除磁盘卷,如上图所示。主流平台的磁盘卷都是通过网络(TCP/RDMA)来挂载的,一般都是基于TCP的,RDMA需要硬件的支持。
2.2.3.1. 存储控制面
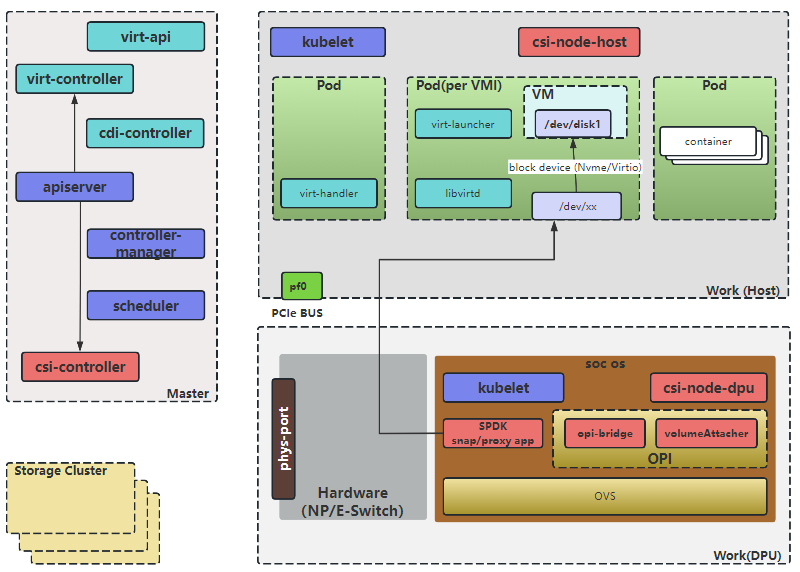
基于DPU的虚拟机磁盘卷架构如如上图所示,将master节点,dpu卡,Host都作为node加入k8s集群,这些node上运行着DPU CSI的相关组件,k8s node分为不同的角色,不同组件分别部署在不同的node之上。
- Master上,部署 csi的控制器csi-controller,其中部署包含了组件external-provisioner、csi-plugin、csi-attacher、csi-resizer和csi-snapshotter等组件,用于创建volume和nvmeof target;
- Host上,部署csi-node-host,配合csi-node-dpu,通过va发现DPU挂载的nvme盘,然后执行绑定或者格式化;
- DPU上,部署csi-node-dpu,volume-attacher,opi-bridge和SPDK,主要负责连接远端存储target,及向宿主机模拟nvme硬盘;
- opi-bridge是卡对opi-api存储的实现。
- volume-attacher是对DPU存储相关方法的封装;csi-node-dpu 调用volume-attacher给host挂盘 为了对接不同的存储,CSI提供了csi-framework, 通过csi-framework能快速的接入第三方的存储,让第三方存储很方便的使用DPU的能力;同时CSI提供基于opi框架的opi-framework,通过opi-framework能快速让DPU适配到K8S集群。
2.2.3.2. 存储数据面
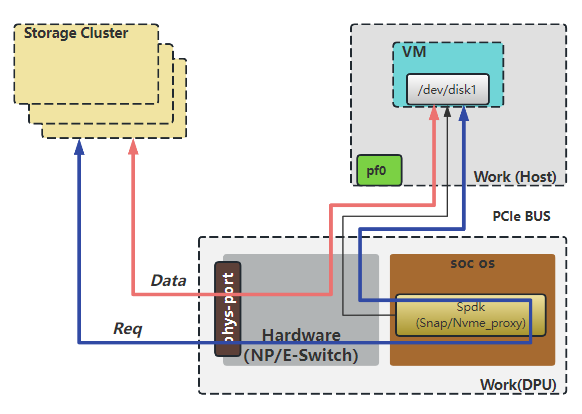
DPU通过网络连接远端存储target,实现了存储协议的卸载,同时能基于RDMA进行网络路径上的加速;另一方面,DPU模拟了nvme协议,通过PCIe向宿主机提供了nvme块设备。
3. 方案测试结果
3.1. 测试步骤说明
主要是对KubeVirt虚拟机的网络和存储进行性能验证:
- 网络性能主要测试卸载CNI方案和非卸载CNI方案下的虚拟机网卡性能,包括带宽、PPS、时延。
- 存储性能主要针对虚拟机的数据盘进行验证,包括顺序写吞吐、顺序读吞吐、随机写IOPS、随机读IOPS、随机写时延、随机读时延。虚拟机的数据盘来源于DPU模拟的nvme磁盘,后端存储协议有2种:nvme over tcp和nvme over rdma。
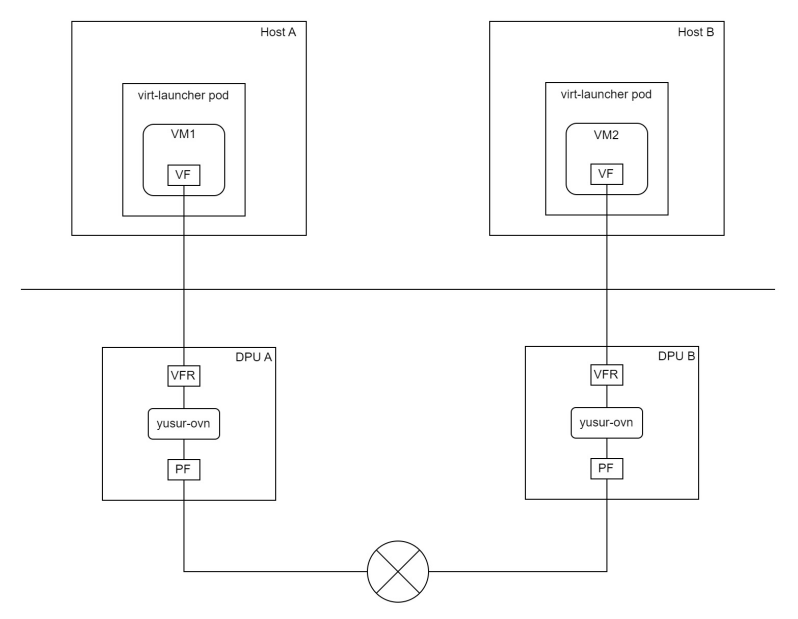
使用卸载CNI方案的虚拟机网络拓扑如下图:
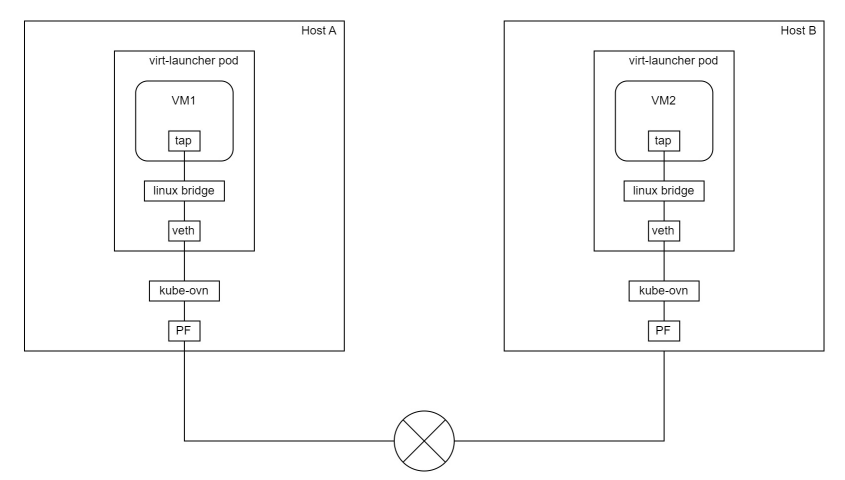
使用非卸载CNI方案的虚拟机网络拓扑如下图:
3.2. 性能测试结果
以下列举基于DPU (100G)网络方案的网络性能指标,并与非硬件卸载CNI方案做简单对比:
| 分类 | 性能指标 | 非卸载CNI方案 | 卸载CNI方案 |
| 网络 | 网络带宽 | 27.4Gbps | 137Gbps |
| 网络PPS | 3.4M | 26M | |
| 网络时延 | 783us | 18us |
从上表可知基于卸载CNI方案的网络性能相比于非卸载CNI方案来说,网络带宽提升了4倍,网络PPS提升了6.6倍,网络时延降低了97.7%
基于DPU(100G)存储方案性能指标,nvme over rdma对比nvme over tcp:
| 分类 | 性能指标 | nvme over tcp | nvme over rdma |
| 存储 | 顺序写吞吐 | 1146MiB/s | 2577MiB/s |
| 顺序读吞吐 | 431MiB/s | 5182MiB/s | |
| 随机写IOPS | 104k | 232k | |
| 随机读IOPS | 63.1k | 137k | |
| 随机写时延 | 164us | 60us | |
| 随机读时延 | 429us | 127us |
从上表可知,nvme over rdma方式的存储在吞吐、IOPS、时延方面全面优于nvme over tcp方式的存储。另外,nvme over rdma场景下的存储性能远低于容器挂载硬盘时的性能(650kiops),原因是当前虚拟机的硬盘是通过virtio方式挂载的,存在额外的虚拟化开销,性能上受到限制。
4. 优势总结
在KubeVirt虚拟机环境中,基于DPU硬件卸载的方案相较于传统的非卸载方案,具有显著的优势,这些优势主要体现在网络性能、资源利用率、时延降低以及存储性能加速等方面,具体总结如下:
1、降低网络复杂度和运维排障难度:
通过DPU的网络卸载能力,实现了网卡直通到虚拟机,减少了虚拟网络设备(veth pair、网桥、TAP设备等),极大地缩短了网络路径,降低了网络复杂性和运维排障难度,并减少了数据在传输过程中的延迟和损耗。
2、显著提升网络性能:
将虚拟机的流表卸载到DPU中,利用硬件进行流表处理,直接将网络数据对接到虚拟机,这一过程比软件处理更为高效,为虚拟机提供了接近物理网卡的极致性能。这种方式使得网络带宽提升了4倍,PPS(每秒包数)提升了6.6倍,网络时延降低了97.7%,显著提升了网络吞吐量和处理速度。
3、降低资源消耗:
将OVS(Open vSwitch)控制面和数据面都部署在DPU中,利用DPU的硬件资源进行网络数据包的转发和处理,大大减轻了Host主机CPU和内存的负担。在40Gbps的TCP/IP流量场景下,传统服务器容易因处理网络任务而耗尽CPU资源,而基于DPU的硬件卸载方案能够显著降低CPU占用率,使得服务器能够处理更多的计算任务或支持更高的网络负载。
4、加速存储性能:
通过yusur-csi提供的基于DPU的RDMA支持,相对于传统的TCP存储方案,能够实现硬件级别的性能加速。这种加速效果最低能达到2倍,最高能达到10倍,显著提升了存储系统的吞吐量和响应速度。
综上所述,基于DPU硬件卸载CNI方案通过缩短网络路径、降低资源消耗、减少网络时延以及加速存储性能等多方面优势,为云计算和虚拟化环境提供了更高效、更可靠的网络和存储解决方案。
本方案来自于中科驭数软件研发团队,团队核心由一群在云计算、数据中心架构、高性能计算领域深耕多年的业界资深架构师和技术专家组成,不仅拥有丰富的实战经验,还对行业趋势具备敏锐的洞察力,该团队致力于探索、设计、开发、推广可落地的高性能云计算解决方案,帮助最终客户加速数字化转型,提升业务效能,同时降低运营成本。

 下载ECAD模型
下载ECAD模型


