


 2322
2322
1. 方案背景和挑战
在传统的云环境中,通常存在着不同的技术栈,支撑多样化的计算服务,具体如下:
① OpenStack环境与虚拟化云主机及裸金属服务
OpenStack是一个开源的云计算管理平台项目,它提供了部署和管理大规模计算、存储、网络等基础设施的一整套软件堆栈。在OpenStack技术栈中,Nova服务主要负责管理虚拟化云主机,而Ironic服务则专注于裸金属资源的管理。
② Kubernetes环境与容器服务
Kubernetes(简称K8s)是广受欢迎的容器管理平台,是行业内的事实标准,主要用于自动化容器应用的部署、扩展和管理。Kubernetes技术栈围绕容器化应用构建,通过其核心组件如kubelet、kube-apiserver、scheduler等,实现了容器资源的高效调度与管理。
虚拟化云主机、裸金属、容器这三种计算服务及其对应的资源池通常独立运行和管理,各自遵循不同的管理和调度规则。
这种分池管理的方式虽然在一定程度上保证了资源的专属性和安全性,但也构成了一个明显的瓶颈,严重制约了资源的灵活性、扩展性和整体利用率,对运营效率和成本控制带来了多重挑战。以下是对这一问题的深入剖析:
1.1. 扩展性受限
在分池管理的框架下,业务的可扩展性受到了严重制约。首先,由于资源池的容量是固定的,当某一资源池的资源即将耗尽时,即便其他类型的资源池中尚有大量闲置资源,也无法实现快速调配。其次,资源池的扩容往往需要人工介入,包括资源的重新规划、配置、测试等一系列繁琐流程,不仅耗时费力,还可能因为预判失误导致资源闲置或供给不足,从而影响业务的连续性和服务质量。这种扩展性差的问题,使得企业在面对市场变化和业务增长时,难以做到敏捷响应和快速扩张,进而错失商机。
1.2. 资源分配僵化与切换困难
资源池之间的独立管理进一步加剧了资源分配的僵化,使得在不同资源池之间进行资源切换或重新分配变得异常困难。例如,在虚拟机资源池接近满负荷运行的同时,裸金属资源池可能仍存在大量未充分利用的节点,但由于缺乏有效的资源池间通信和资源共享机制,这些裸金属节点无法被快速转换为虚拟机资源,以缓解虚拟机资源池的压力。这种资源分配的不灵活性不仅限制了系统的弹性伸缩能力,还导致了资源的冗余和浪费。
1.3. 整体资源利用率低下
资源池的独立管理导致了资源利用率的显著下降。由于各资源池之间的资源无法实现共享,即便某些资源池存在资源过剩的情况,也无法有效支援资源紧张的池子,从而造成了资源分配的不平衡。例如,容器资源池中创建的节点可能只承载了少量的容器应用,而与此同时,虚拟机资源池却可能面临严重的资源挤兑现象,导致新虚拟机的创建受阻。这种资源孤岛现象不仅降低了整体资源的使用效率,还可能引发一系列连锁反应,如服务延迟、性能下降和客户满意度降低等问题。
综上所述,传统云环境中资源池的独立管理方式暴露出了一系列问题,包括扩展性差、资源分配不灵活和资源利用率低等,这些问题共同构成了云计算资源管理的一大难题。为了解决这一挑战,业界正在积极探索和实践资源池融合、自动化资源调度和智能资源配置等创新技术,以期实现资源的高效利用和灵活调度,推动云计算基础设施向着更加智能、弹性和经济的方向发展。
2. 方案介绍
2.1. 整体方案架构
为了解决上述问题,我们提出了基于DPU的云原生计算资源共池管理解决方案,结合了DPU的硬件优势与Kubernetes的能力和插件生态,在Kubernetes架构下实现了虚拟机、裸金属和容器资源的无缝整合与统一管理,可以实现当某一类资源池(如虚拟机资源池)面临资源紧张时,系统能够自动从共享资源池中调用资源,实现Worker节点的快速扩容,而当资源需求下降时,又能够智能缩容,将多余Worker节点回收至共享池中,确保资源的按需分配与适时释放。
本方案中包括了BareMetalManager,这是基于DPU的裸金属管理软件包,由bm-controller、bm-api、bm-handler三个组件组成。它负责管理裸金属机器的生命周期,实现裸金属服务器的无盘启动、云盘的动态热插拔以及网卡动态热插拔。BareMetalManager 将裸金属服务器作为 k8s资源进行统一管理,从而提升裸金属服务器的管理效率,并为虚拟机、容器资源池Worker节点的快速部署提供基础保障。
本方案的核心部分包括资源池状态感知、评估和调度,基于Kubernetes Cluster AutoScaler进行设计,其整体架构如下:
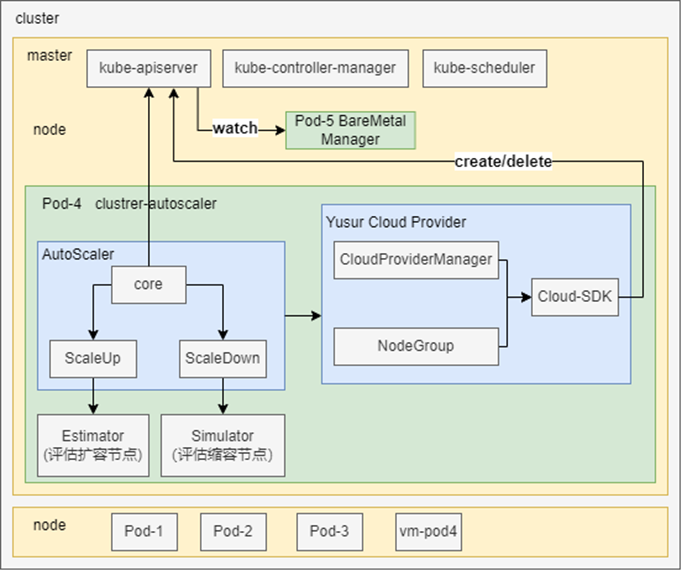
该架构主要是由以下几个核心组件完成:
- AutoScaler:核心模块,负责集群节点及Pod信息检查,调用扩缩容功能。
- Estimator:负责评估worker节点扩容需求,进行Pod预调度。
- Simulator:负责评估worker节点缩容需求,模拟节点缩容。
- Yusur Cloud Provider:负责将裸金属资源注册到为供Cluster AutoScaler扩缩容使用的NodeGroup。管理裸金属实例的创建和删除,并将裸金属实例加入或移出 Kubernetes 集群。
2.2. 方案详细描述
本节主要对云原生计算资源共池管理方案的核心部分,即Cluster AutoScaler模块、扩缩容逻辑以及cloud provider进行介绍。
2.2.1. AutoScaler
AutoScaler启动后触发循环控制逻辑。每10s执行一次,检测集群状态,决定是否执行扩容或缩容操作。整体流程图如下:
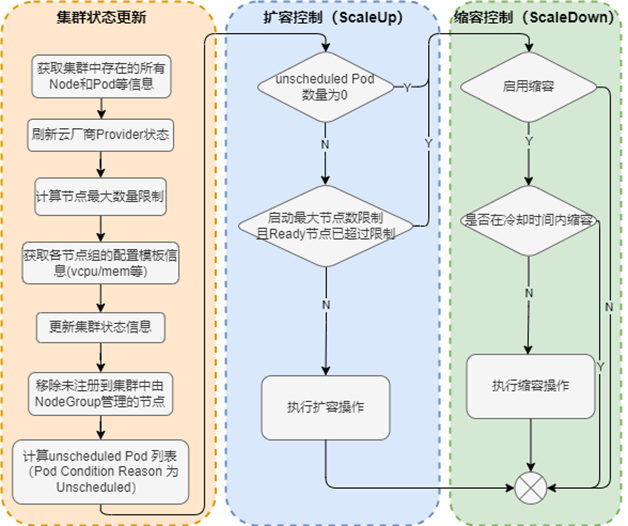
从流程图中可以看到,AutoScaler关键逻辑为发现node,pod以及cloud provider信息。经过几个模块处理,将因资源不足导致未调度的pod缓存起来。然后进行下一步判断,是否需要调用ScaleUp或者ScaleDown进行扩缩容控制。
2.2.2. ScaleUp
ScaleUp是AutoScaler评估后需要执行扩容操作后调用的模块,其流程图如下:
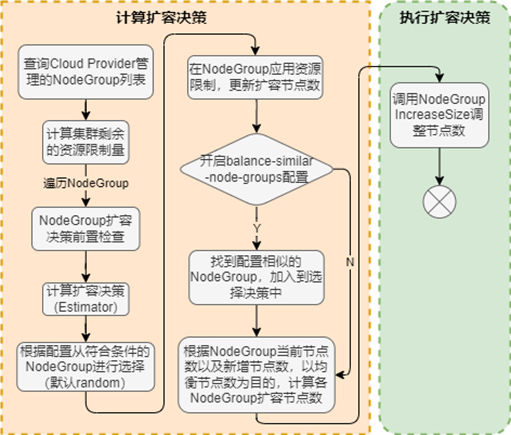
从流程图中可以看到,当AutoScaler检测到需要进行扩容操作后,ScaleUp还是会进行一些基础检查,如当前计算节点数量是否达到最大限制、扩容后资源是否超限等前置检查。然后通过调用Estimator,进行Pod预调度,进行扩容决策,最终选出一个NodeGroup,从该NodeGroup中申请节点对k8s集群进行扩容。
当集群中有多个 Node Group 可供选择时,可以通过expander选项配置选择 Node Group 的策略,支持如下三种方式:
- random:随机选择;
- most-pods:选择容量最大(可以创建最多 Pod)的 Node Group;
- least-waste:以最小浪费原则选择,即选择有最少可用资源的 Node Group。
2.2.3. ScaleDown
ScaleDown是AutoScaler评估后需要执行缩容操作后调用的模块,其流程图如下:
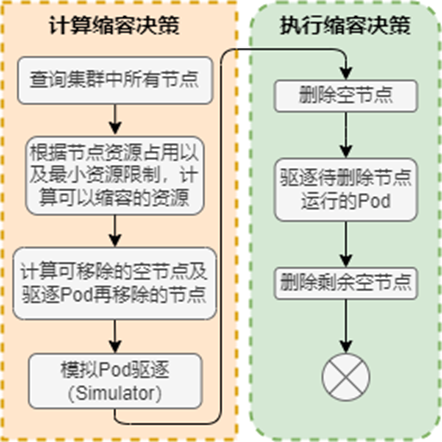
从流程图中可以看出,缩容也会进行前置检查。缩容过程中最重要的是检查需要驱逐pod再移除相应节点的流程。当节点上需要驱逐Pod才能回收时,会调用Simulator模拟Pod驱逐,为被需要驱逐的Pod寻找可调度节点。由于在删除worker节点时会发生Pod重新调度的情况,所以应用必须可以容忍重新调度和短时的中断(比如使用多副本的 Deployment),当满足以下条件时,worker节点不会删除:
- 节点上有pod被PodDisruptionBudget(PDB)控制器限制,PDB是k8s中的一种资源,它为 Pod 提供了一种保护机制;
- 节点上有命名空间是kube-system的pods;
- 节点上的pod不是被控制器创建,例如不是被deployment, replicaset, job, statefulset创建;
- Pod 使用了本地存储;
- 节点上pod驱逐后无处可去,即没有其他worker节点能调度这个pod;
- 节点有注解:”cluster-autoscaler.kubernetes.io/scale-down-disabled“:“true”,可以通过给节点打上特定注解保证节点不被Cluster AutoScaler删除;
- 配置 `cluster-autoscaler.kubernetes.io/safe-to-evict=false 注解,可以确保 pod不被驱逐,pod所在 worker节点不被缩减。
2.2.4 Yusur Cloud Provider
yusurCloudProvider会在Cluster AutoScaler初始化的过程中进行注册NodeGroup信息,在执行ScaleUp和ScaleDown后得到实际的调用。其具体流程如下:
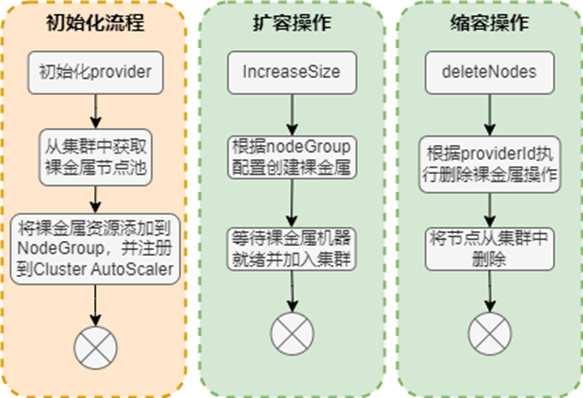
其中将裸金属资源添加到集群共享资源池(NodeGroup),可以根据指定规则(如机型、CPU 等)将其划分为多个组。每个 NodeGroup 需要包含当前组中机器的详细配置,用于扩容过程中的模拟调度。
扩容与缩容操作中,裸金属实例的生命周期由BareMetalManager控制。
3. 方案优势
本解决方案针对传统云环境中资源池独立管理的挑战,提出了创新的资源共池管理机制,旨在大幅提升资源的灵活性、效率和利用率,以下是该方案的三大核心优势:
3.1. 增强业务可扩展性与弹性
该方案通过构建统一的资源池,打破了不同资源类型之间的界限,实现了资源的动态调配与共享。当某一资源类型(如虚拟机)面临资源瓶颈时,系统能够自动从共享资源池中申请额外资源,快速扩容以满足业务需求。反之,在资源空闲时,又能自动缩容,将多余的资源节点归还至共享池,避免了资源浪费。这种机制显著增强了业务的可扩展性和弹性,使得企业能够更加从容地应对业务波动和突发流量,提高服务的连续性和用户满意度。
3.2. 提升资源分配的灵活性与效率
通过资源共池管理,实现了资源的自动化和智能化分配,显著提升了资源分配的灵活性与效率。不再局限于固定资源池的限制,系统能够根据实时的资源需求和业务负载,自动在共享资源池中寻找最优的资源匹配,进行即时的资源调度。这种动态分配机制不仅简化了资源管理的复杂度,还极大地提高了资源分配的精准度和响应速度,使得资源能够更加高效地服务于业务需求,减少人为干预,提升整体运维效率。
3.3. 最大化资源利用率,降低成本
云原生计算资源共池管理解决方案通过打破资源池之间的壁垒,实现了资源的全局优化与共享,有效解决了资源孤岛问题,大幅提高了资源的整体利用率。在传统模式下,由于资源池的独立管理,资源分配往往呈现出不均衡状态,导致部分资源长期闲置。而共池管理方案能够根据实际需求动态调整资源分配,避免了资源的冗余和浪费,从而显著降低了企业的运营成本。此外,通过智能的资源调度算法,该方案还能进一步挖掘资源潜力,提升资源使用效率,为企业带来更大的经济效益。
基于DPU的云原生计算资源共池管理解决方案通过实现资源的统一管理、动态调配与智能优化,有效解决了传统云环境中资源管理的痛点,为构建更加灵活、高效和经济的云基础设施提供了有力支撑。
本方案来自于中科驭数软件研发团队,团队核心由一群在云计算、数据中心架构、高性能计算领域深耕多年的业界资深架构师和技术专家组成,不仅拥有丰富的实战经验,还对行业趋势具备敏锐的洞察力,该团队致力于探索、设计、开发、推广可落地的高性能云计算解决方案,帮助最终客户加速数字化转型,提升业务效能,同时降低运营成本。

 下载ECAD模型
下载ECAD模型


