


 720
720
一、准备
本项目使用 www.perfxcloud.net 大模型平台,网站上有详细的说明文档。
注意:PerfXCloud的API接口兼容 OpenAI 的ChatGPT,可以直接使用 OpenAI SDK或者其他中间件来访问 PerfXCloud。这使得开发者从ChatGPT或者其他平台切换到PerfXCloud变得非常非常容易。
1.如果还没有PerfXCloud的账号,可以登录网站创建一个。
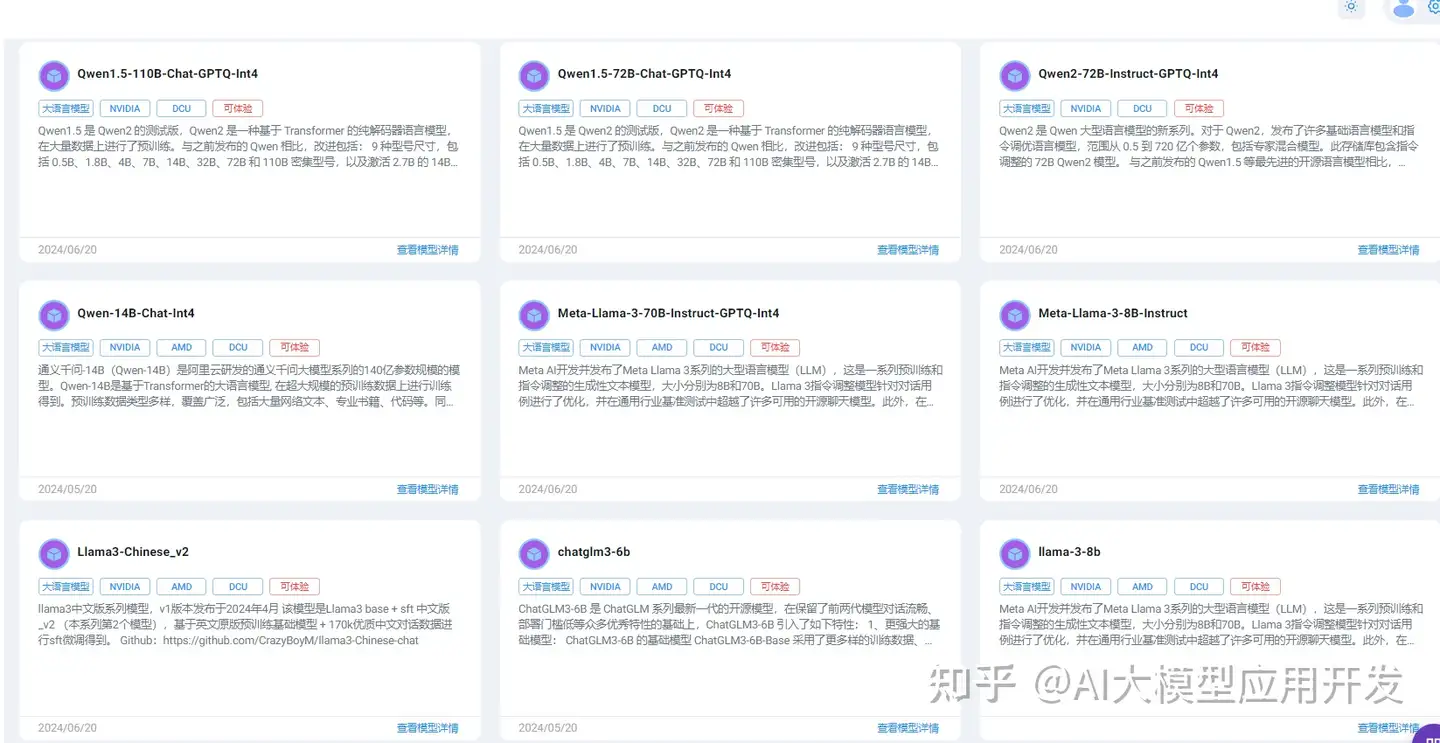
2.PerfXCloud目前支持:
Qwen1.5-110B-Chat-GPTQ-Int4, Qwen1.5-72B-Chat-GPTQ-Int4, Qwen2-72B-Instruct-GPTQ-Int4, Meta-Llama-3-70B-Instruct-GPTQ-Int4, Qwen-14B-Chat-Int4, Meta-Llama-3-8B-Instruct,Llama3-Chinese_v2, chatglm3-6b,llama-3-8b, Qwen1.5-7B,Qwen2-7B,gpt2, SOLAR-10_7B-Instruct,llama-2-7b, PHI_1-5,opt-1b3, phi-2,internLM, Mistral-7B-Instruct, MindChat-Qwen-7B-v2,StarCoder-1B (还在持续更新中)
二、论文搜索与总结
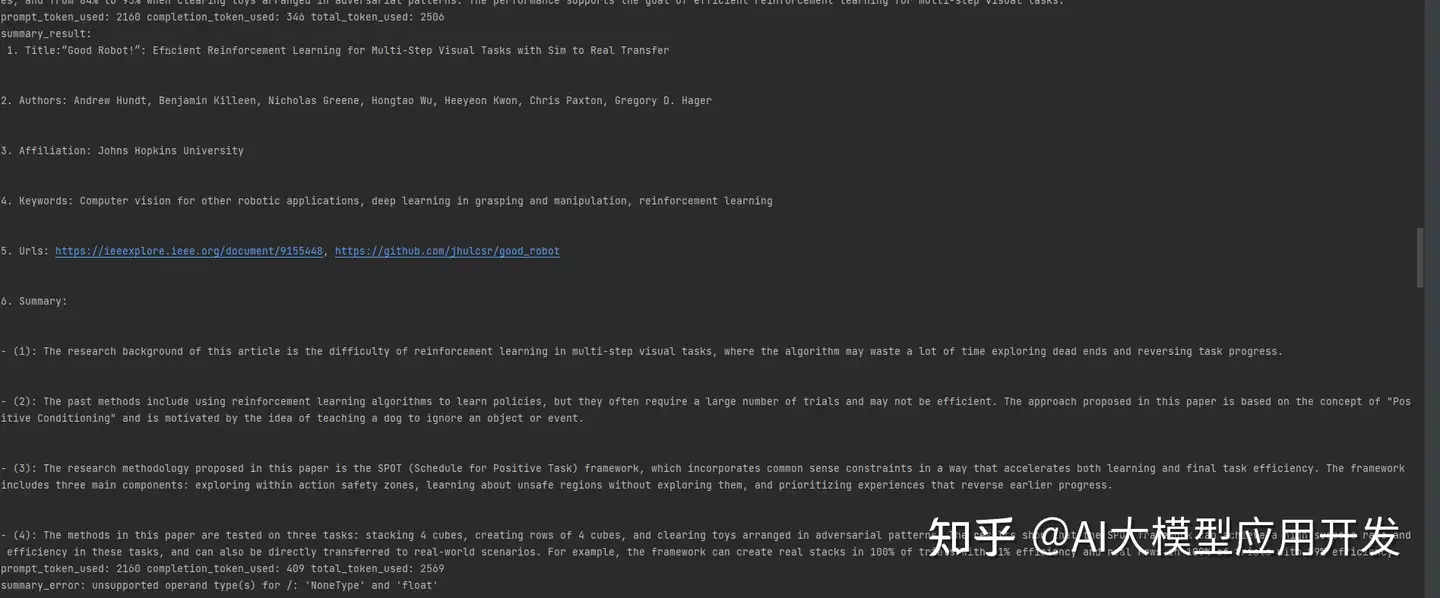
本项目是一个基于大型语言模型搭建的智能论文搜索总结,可根据自己设定的关键词搜索相关的论文,大模型会自动总结论文给出相关的简要信息。本项目基于https://github.com/kaixindelele/ChatPaper进行开发。
论文搜索总结效果图如下:
三、程序部署
本地开发环境支持 MacOS、Windows、Linux 系统,需要安装 python环境,python推荐的版本在 3.8.9 ~ 3.9.X 之间,建议3.9,numpy版本需要在1.24.2版本或者更高,python可前往官网下载。
(1)下载源码
可以在项目地址下载相关文件 或者在命令行使用 git 克隆项目并进入目录(进入你所下载的文件目录即可):
git clone https://gitee.com/PerfXCloud-APP/chat-paper.git
cd chat-paper/项目也可通过docker等方式部署,详细可见具体项目地址
(2)安装依赖
pip install -r requirements.txt 如果使用的是pycharm部署并使用的是虚拟环境,最好提前激活你所需要的虚拟环境,可以用下面的命令来激活 .Scriptsactivate
(3)配置
打开apikey.ini文件,修改所需配置,具体配置含义参考配置说明。
[OpenAI]
introduction = the api key does not ''
OPENAI_API_KEYS = [令牌, ]
# the base URL for openai or other proxy
OPENAI_API_BASE = https://cloud.perfxlab.cn/v1
# If you are using the forward API, you need to replace the base url above with the forward link, and enter the key as usual, for example:
# OPENAI_API_BASE = httpts://chatnext.lan-qian.top/v1
CHATGPT_MODEL = llama-3-8b配置的效果如下,可以配置自己的模型和api-key api-key获取方式 :

四、运行
本地运行项目
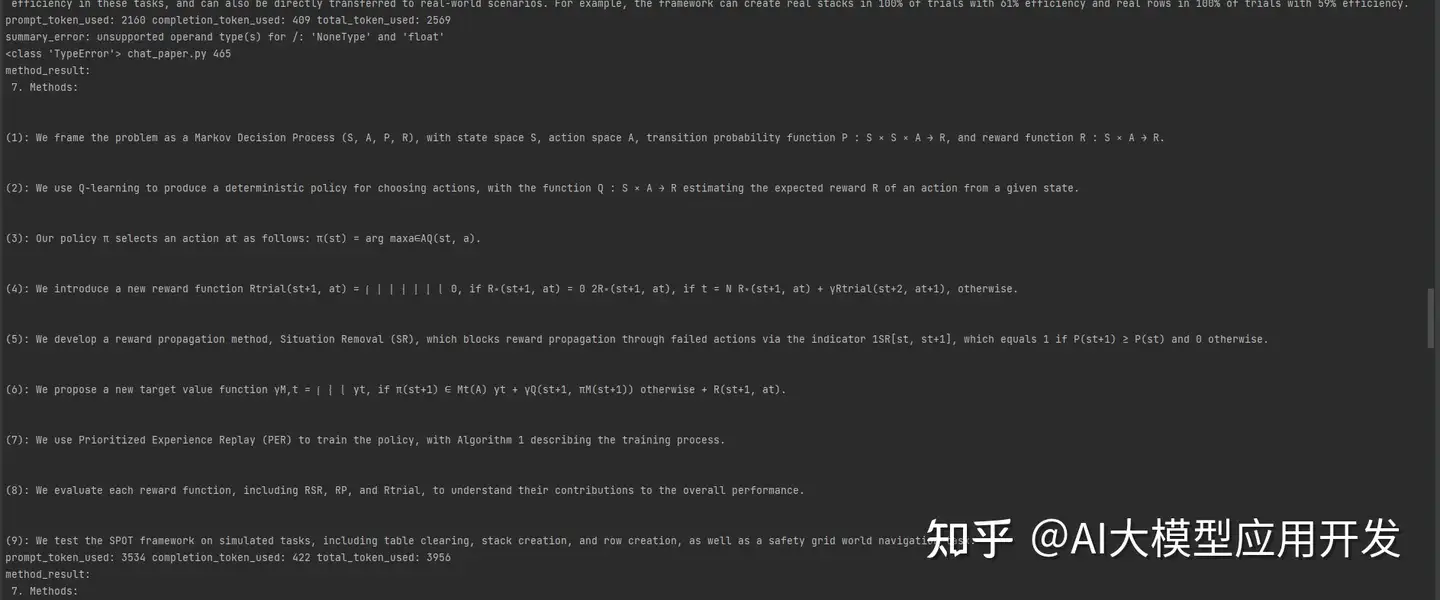
Arxiv在线批量搜索+下载+总结 使用命令行进行运行 python chat_paper.py --query "chatgpt robot" --filter_keys "chatgpt robot" --max_results 3 前两个引号中的内容是你设定的关键词,最后的数字是每次搜索的最大文章数,只需更改这三个参数即可 运行后会出现搜索出的文章的标题,作者等信息,还会给出相应的方法总结,文章总结等 还有更多的运行方式与功能,详细可见具体项目地址
部分运行参数介绍说明:
[--pdf_path 是否直接读取本地的pdf文档?如果不设置的话,直接从arxiv上搜索并且下载]
[--query 向arxiv网站搜索的关键词,有一些缩写示范:all, ti(title), au(author),一个query示例:all: ChatGPT robot]
[--key_word 你感兴趣领域的关键词,重要性不高]
[--filter_keys 你需要在摘要文本中搜索的关键词,必须保证每个词都出现,才算是你的目标论文]
[--max_results 每次搜索的最大文章数,经过上面的筛选,才是你的目标论文数,chat只总结筛选后的论文]
[--sort arxiv的排序方式,默认是相关性,也可以是时间,arxiv.SortCriterion.LastUpdatedDate 或者 arxiv.SortCriterion.Relevance, 别加引号]
[--save_image 是否存图片,如果你没注册gitee的图床的话,默认为false]
[--file_format 文件保存格式,默认是markdown的md格式,也可以是txt]也可以在代码中使用parser方法提前写入参数
parser.add_argument("--pdf_path", type=str, default='', help="if none, the bot will download from arxiv with query")
parser.add_argument("--query", type=str, default='all: ChatGPT robot', help="the query string, ti: xx, au: xx, all: xx,")
parser.add_argument("--key_word", type=str, default='reinforcement learning', help="the key word of user research fields")
parser.add_argument("--filter_keys", type=str, default='ChatGPT robot', help="the filter key words, 摘要中每个单词都得有,才会被筛选为目标论文")
parser.add_argument("--max_results", type=int, default=1, help="the maximum number of results")
parser.add_argument("--sort", default=arxiv.SortCriterion.Relevance, help="another is arxiv.SortCriterion.LastUpdatedDate")
parser.add_argument("--save_image", default=False, help="save image? It takes a minute or two to save a picture! But pretty")
parser.add_argument("--file_format", type=str, default='md', help="导出的文件格式,如果存图片的话,最好是md,如果不是的话,txt的不会乱")
本项目视频教程地址
本项目代码地址
-----------------------------------------全文完-----------------------------------------

 下载ECAD模型
下载ECAD模型





