


 2333
2333
对于运行中需要大量内存访问和数据处理的计算任务,比如HPC、数据分析、金融科技应用、网络安全、AI计算等。由于涉及大规模数据的读取、写入和处理操作,往往对系统内存带宽和存储性能有很高要求。
事实上,对于这些大规模数据处理任务来说,最佳性能不仅取决于原始计算能力,还取决于高存储器带宽。日前,AMD发布了全新的Alveo V80加速卡,通过FPGA灵活应变的能力来实现工作负载优化。

应对大数据集负载存储和网络瓶颈
AMD 自适应和嵌入式计算事业部( AECG )高级产品线经理Shyam Chander指出,传统处理架构在运行大数据集工作负载时,CPU+FPGA和PCIe的带宽远高于DDR内存和网络接口可以提供的带宽,因此无论是存储器还是网络访问等方面,都非常容易形成瓶颈。
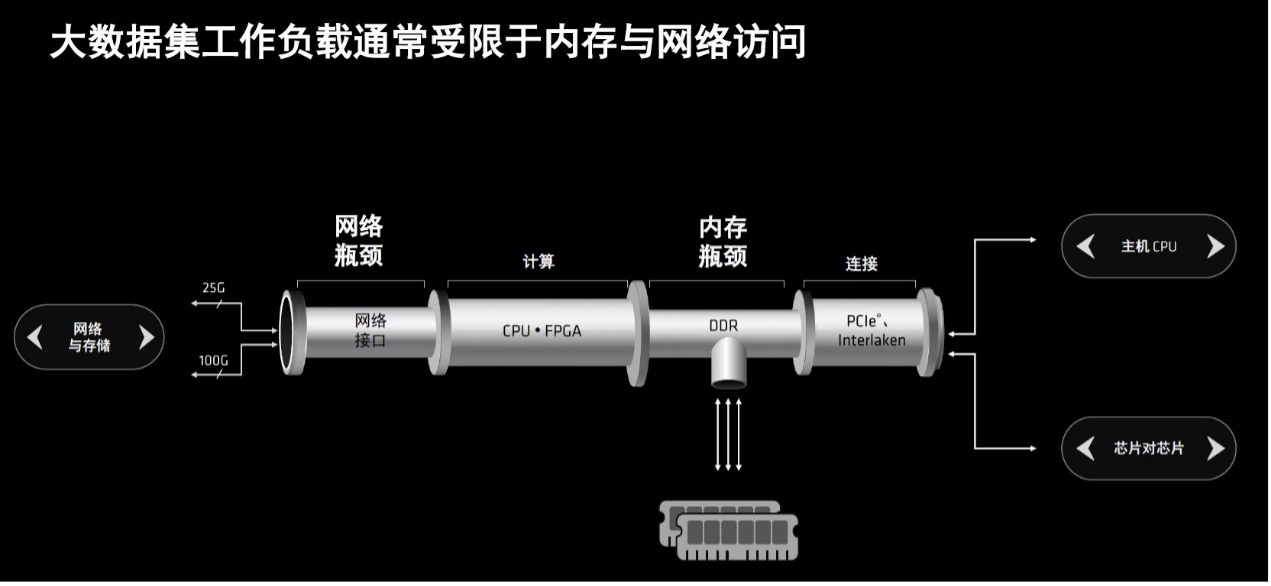
AMD全新加速卡Alveo V80采用全高、3/4 长( FH¾L )尺寸规格,由 AMD Versal HBM 自适应 SoC 提供支持,具备 2,600,000 个 LUT 逻辑单元的 FPGA 架构、10,848 个 DSP 计算逻辑片以及820 GB/s的存储器带宽,从而助力克服性能瓶颈。

Alveo V80还包括一个32GB的DDR4 DIMM扩展插槽,并支持PCle Gen5接口,64G传输速率是第四代的2倍。整卡功率300W,采用被动散热,总热设计功耗TDP则取决于器件和服务器。
通过这样的硬件灵活性,可以实现跨不同的自定义工作负载进行广泛应用。作为一款4x200G网络附接加速卡,该卡可以实时处理大量传入数据,避开GPU遇到的PCIe连接限制。
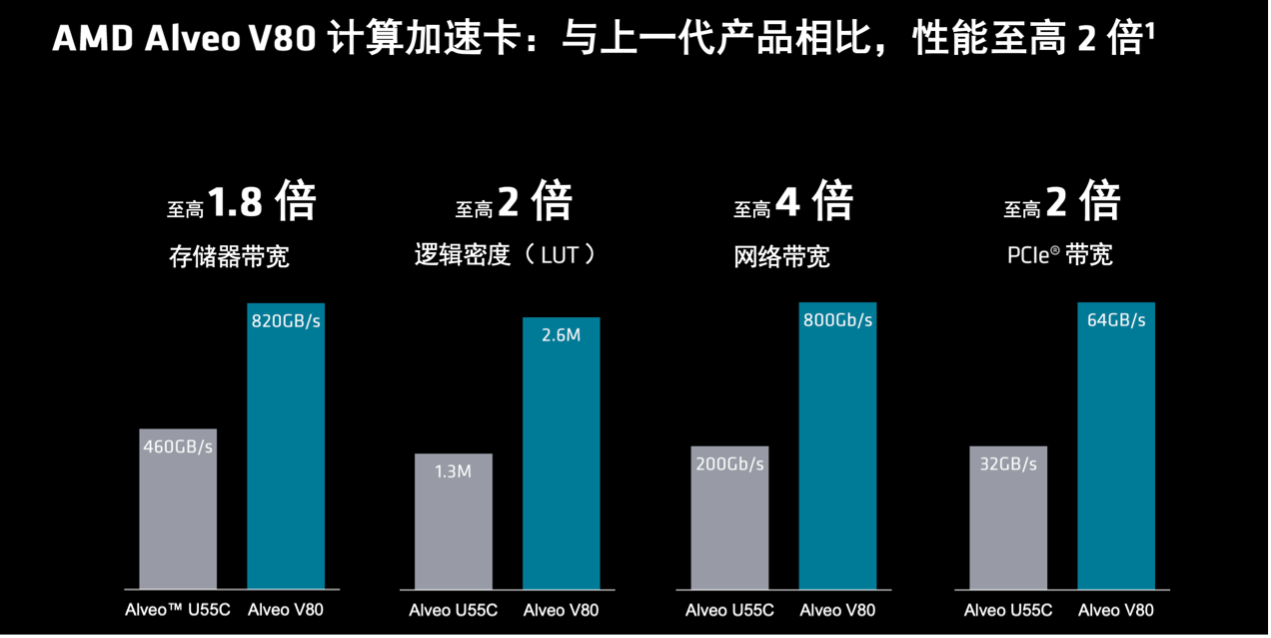
与前代产品AMD Alveo U55C计算加速卡相比,Alveo V80 的逻辑密度至高翻倍、存储器带宽至高翻倍且网络带宽可高至4倍,可以实现强大的计算集群,同时还能优化卡、服务器数量以及机架空间。
Shyam Chander介绍,在传统的处理架构中,存储器和网络访问容易成为性能瓶颈,尤其在高性能计算场景中更为常见。这是因为传统上通常采用芯片对芯片的PCIe连接方式,同时,DDR4存储器所提供的带宽可能不足以满足高性能计算的需求,在存储器访问上也存在瓶颈。
这种架构的局限性在于,尽管FPGA等加速器组件具备高带宽处理能力,但受限于DDR4存储器的带宽,无法充分发挥其性能潜力。为了突破这些瓶颈,可能需要采用更高带宽的存储技术,或者改进系统架构以更有效地利用FPGA等加速器的高带宽优势。
通过Versal HBM技术支持的AMD Alveo V80计算加速卡,可以融合FPGA的灵活应变来处理大数据集的工作负载。与前代产品相比,它的性能提升至高2倍,包括逻辑密度翻倍、存储器带宽翻倍。
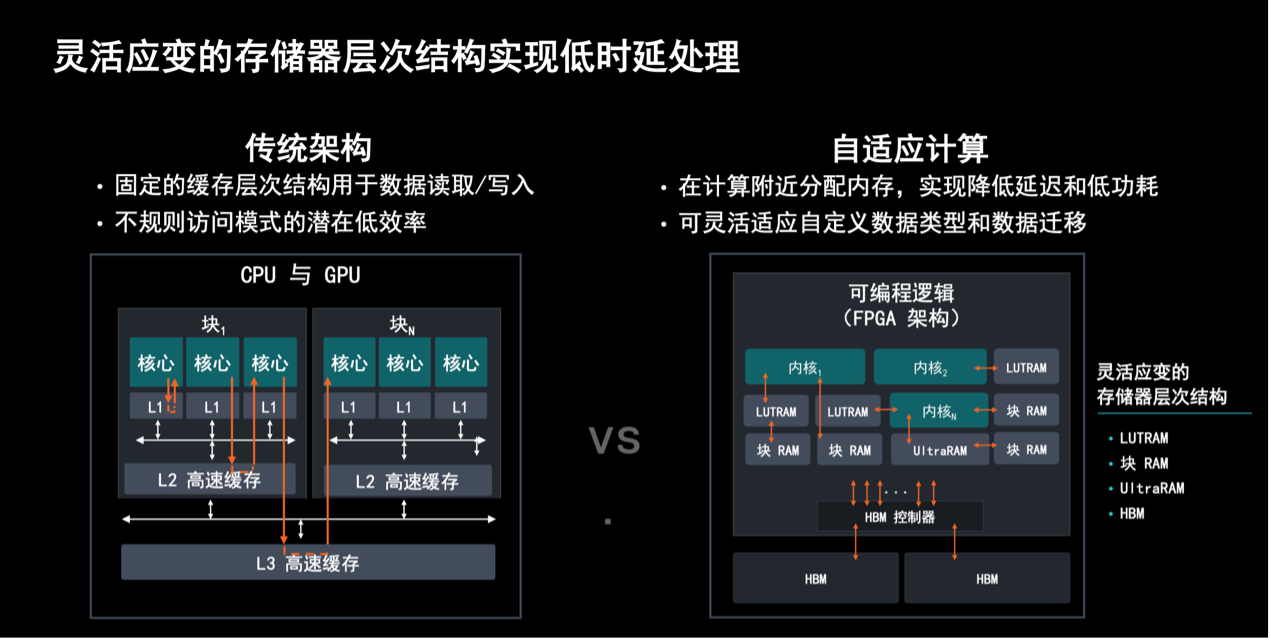
这其实就是CPU/GPU传统架构和自适应计算拥有的灵活应变架构之间的不同。“传统架构是固定的缓存层次结构,用于数据的读写和输入,在这个过程中不规则的访问模式会引起潜在的低效率”,Shyam Chander指出,“灵活应变的存储器层次架构是在计算附近分配内存,实现降低延迟和低功耗,而且可以灵活适应自定义的数据设计和数据建议。”
灵活应变,适用于内存密集型工作负载
Alveo V80 加速卡可通过以太网扩展到数百个节点实现计算集群,非常适合一系列高性能计算应用,包括基因组测序、分子动力学和传感器处理。在网络安全方面,内置400G 加密引擎和 600G 以太网硬块,加之FPGA的硬件灵活性,使其适用于线速数据包检测和 AI 支持的异常检测。
该加速卡还非常适合计算存储和数据分析,能够在同一张卡上集成压缩和查询加速,从而增加有效存储容量,同时更快获得洞察。因此它适合于各种金融科技应用,包括策略回测、期权定价以及金融建模与仿真。
用例1:天体物理学实现计算飞跃
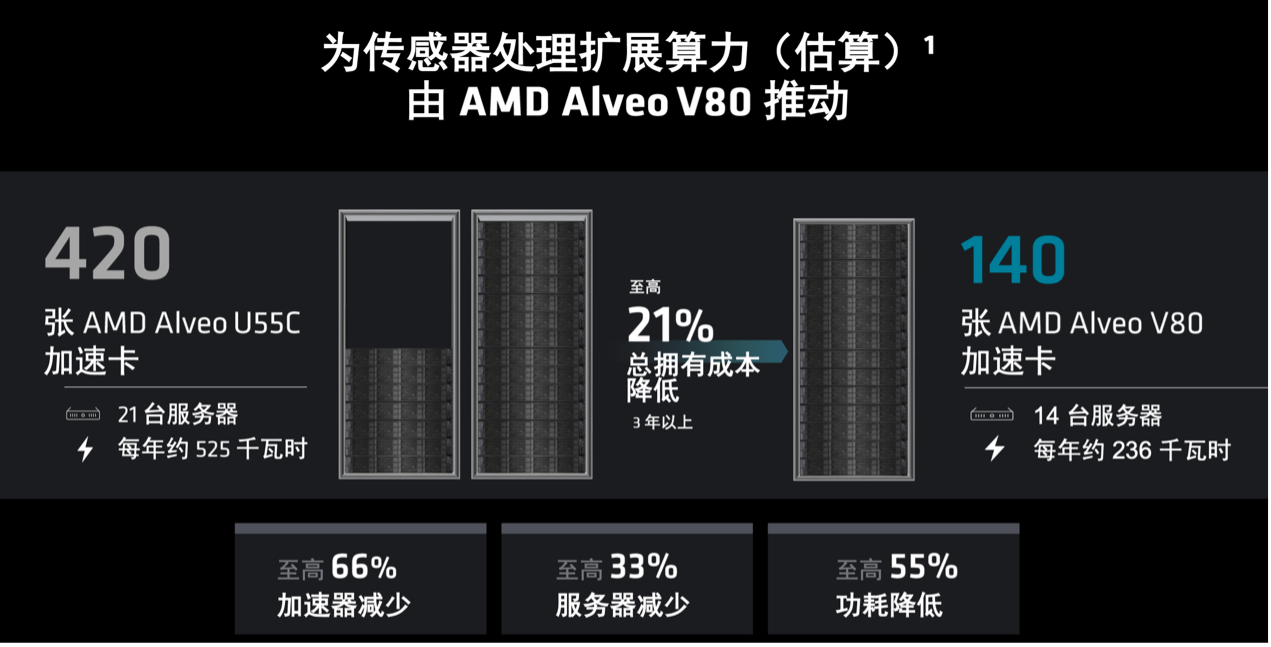
联邦科学与工业研究组织( CSIRO )是澳大利亚的国立研究组织,其参与建造了世界上最大的射电天文学天线阵列,该天线阵列目前包含 420 张 Alveo U55C 加速器卡用于处理无线电波,以研究早期宇宙并探索星系演化。
CSIRO计划借助 Alveo V80 加速卡缩减占板面积与成本,并将所需加速卡的数量精简多达 66%,同时应对来自望远镜 131,000 个天线的新信号处理任务。考虑到卡、服务器、机架空间和功耗的潜在减少,每卡算力的跃升预计可带来最高20%的TCO下降。
CSIRO 空间与天文学部研究工程师 Grant Hampson 表示:“我们起初采用 Alveo 产品线是因为它能够实时处理大量传感器数据。对于我们的下一代波束成形器和相关器来说,降低总拥有成本势在必行。Alveo V80 加速卡是对上一代 Alveo U55C 卡的技术阶跃提升,以经济高效的占板面积提供了紧凑、节能的解决方案。”
用例2:压缩和数据分析服务器存储节点
在具备压缩和数据分析功能的服务器存储节点的用例中,通过Alveo V80实现了三大特点:第一,服务器存储节点采用了FPGA架构和AMD的压缩IP,使得存储节点在处理数据压缩任务时具有可扩展性;第二,通过MCIO直接将FPGA架构连接至NVMe, 实现了高速数据传输;第三,服务器节点整合了额外的功能,如查询加速,有助于提升执行速度并降低时延。
此外,在该服务器存储节点中,通过Versal HBM与FPGA的结合,使得服务器存储节点的算力得到显著提升。HBM技术的高带宽特性允许在内存中直接进行计算操作,避免了数据在系统总线上的迁移,进一步加速了查询处理速度。这种设计不仅提高了数据处理效率,还减少了因数据传输引起的时延,使得服务器存储节点在执行数据压缩和分析任务时更为高效。
从总拥有成本的角度来分析,比如10Pb数据存储,没有压缩时需要55台服务器,1303个SSD驱动器,每年约427千瓦时的功耗。如果进行压缩,同样是10Pb数据只需要21台服务器,504个SSD驱动器,每年能耗约233千瓦时,使用42张AMD Alveo V80卡进行压缩,总拥有成本三年以上至高可以达到56%的降低,而且服务器的数量、服务器成本以及功耗也都有非常显著的降低。
用例3:金融建模和算法交易
在金融科技领域,用户在建模、仿真与回测的用例场景中,用户可以用FPGA架构和DSP进行密集计算,HBM用于大数据集、历史定价数据。而在低时延算法交易中,752Mb的RAM用于定价数据、交易记录,HBM则用于订单信息。

在简化开发方面,Alveo V80 加速卡经由 Alveo Versal 示例设计( AVED )完全可为传统硬件开发人员使用,现已在 GitHub 上提供。AVED 利用传统 FPGA 和 RTL 流程简化了硬件启动,并且基于常见的 Vivado 工具流程。示例设计采用在 AMD Versal 自适应 SoC 上实现并专门针对 Alveo V80 加速器卡的预构建子系统,提供了高效的起点。
在系统层面,Alveo V80 计算加速卡简化了系统集成并提供了快速的量产路径。通过使用预先验证的部署卡,设计团队可以避开 PCB 集成、库存管理和产品生命周期管理任务。
Versal HBM SoC提供支持,应对广泛负载需求
在Alveo V80加速卡中,Versal HBM 自适应 SoC 的支持无疑是一大亮点。不过,HBM的价格几乎是DDR的三倍,这是否会影响客户的采用?
Shyam Chander强调了Alveo V80的设计考虑,该加速卡是由UltraScale+ U55C过渡而来。首先,在性能提升基础上,目前的成本增加最有限;其次,HBM可以应对非常广泛的工作负载,包括内存带宽计算,通过这样的方式可以实现最高的性价比;第三,从工作负载和计算资源的角度来看,Versal架构中HBM的封装尺寸和PCB占板面积较小,这在成本、性能和占板面积方面带来了优势,通过合理配置FPGA资源,可以实现高性价比。
至于市面上多样化的算力加速卡类型,包括FPGA加速卡、GPU加速卡、AI芯片加速卡等等,Shyam Chander认为FPGA自适应SoC更适合硬件开发者的需求,特别是在需要降低时延、实时数据处理和减少功耗的应用场景中。并且,Alveo V80加速卡有直接的I/O连接和相关示例,对开发者非常有帮助。
对于未来趋势,Shyam Chander认为不同类型的加速卡将根据工作负载的需求继续共存。Alveo V80卡的低时延和灵活性使其适合于硬件开发者,而软件工程师可能更倾向于使用CPU等其他类型的加速器。他强调,Alveo V80作为一个网络附接的加速器卡,可以和存储驱动器连接,应对非常广泛的工作负载和需求。

 下载ECAD模型
下载ECAD模型










 [课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
[课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
