


 3013
3013
NVIDIA创始人兼首席执行官黄仁勋,给COMPUTEX大会带来了一场极具“松弛感”的主题演讲。回到出生地的他,不论是逛夜市、吃美食还是登台演讲,都显得放松且亲切。他在演讲中不仅谈到了自己的“夜市情结”,还回忆了童年的夜市“趣事”……
演讲中,黄仁勋详细介绍了新的芯片平台、软件和系统,它们将为新型数据中心、工厂、消费级设备、机器人等提供助力,此外,降低成本和可持续增长的重要性也是他着重强调的一点。历数了加速计算的种种好处后,黄仁勋再现“名场面”:the more you buy, the more you save.
“夜市情结”和成为行业的“AI工厂”
身家已经超过900亿美元的黄仁勋,在这次公开演讲中谈到了自己的“夜市情结”。据他回忆,大约四五岁,他就非常喜欢去夜市,因为他喜欢在那里观察人群。有一次,有人洗刀不小心割伤了他的脸,这道伤疤一直留在了他的脸上……即便如此,夜市对他来说依然有着很大的吸引力,直到现在他都喜欢去。
黄仁勋“插播”这个小故事时正讲到了ChatGPT的变革。人都会有某些特别的想法或意图,不同于以往的计算机应用,ChatGPT能够清楚理解人的意图,并且像人类一样与之互动。
2016年,黄仁勋亲手将世界上第一台DGX-1超级计算机交给Open AI后,使得Transformer能够基于巨大的数据集进行训练。直到2023年,ChatGPT横空出世,业界现在开启了由AI工厂驱动的新产业革命。
黄仁勋谈到,几乎每天都有新的AI模型被发明,且每一个行业都在导入AI大模型应用。3万亿美元的IT行业,首次将创造能够直接服务于100万亿美元产业的价值,它不再仅仅是信息存储或数据处理的工具,而是为每个行业生成智能的AI工厂。
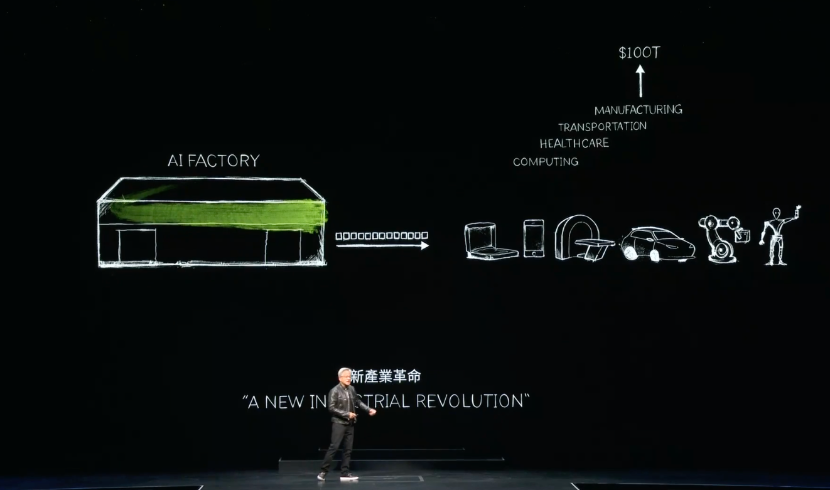
算力通货膨胀不能再继续,加速计算实现可持续增长
这一切,如果没有加速计算会怎么样?
黄仁勋指出,两件根本性的事情在发生:第一,中央处理单元(CPU)——计算机行业运行的核心部件,其性能扩展已经大幅放缓;第二,我们不得不进行的计算量,仍然在非常迅速地呈指数级翻倍。
“处理需求指数级增长,而性能却没有跟上,我们正在经历计算能力的通货膨胀。全世界数据中心的电力在大幅增长,计算成本正在上升,这种情况不能继续下去。这也是为什么,近二十年来,我们一直在致力于加速计算”,黄仁勋表示,“我们应该加速一切,每一个处理密集型的应用都将被加速。”
NVIDIA通过CPU与GPU的组合实现了这一点。由GPU加速所实现的100个时间单位的节约,也就是实现100倍速度的提升,相应所需付出的是3倍功耗、1.5倍成本。此处黄仁勋再次加入了那句经典广告词“The more you buy…The more you save”,他强调,加速计算可显著节约成本和能源,实现可持续的增长。

Blackwell——新产业革命的引擎
黄仁勋在演讲中提到,伟大的智慧是退后一步。在生成式AI的热潮来临之前,他需要思考:人工智能的背景是什么?深度学习的基础是什么?长期的影响是什么?它的潜力是什么?……
当他意识到这项技术有很大的潜力去扩展一个算法实现的时候,他认为这将需要更多的数据、更大规模的网络,非常重要的是——更多的计算能力,而Blackwell就是为了这一代AI而设计的。

Computex期间,NVIDIA与全球多家计算机制造商发布一系列采用Blackwell 架构的系统,这些系统搭载了Grace CPU 以及 NVIDIA 网络和基础设施。永擎电子、华硕、技嘉、鸿佰科技、英业达、和硕、QCT、Supermicro、纬创资通和纬颖将使用 NVIDIA GPU 和网络打造云、专用系统、嵌入式和边缘 AI 系统。
黄仁勋表示,“从服务器、网络和基础设施制造商到软件开发商,整个行业正在准备使用 Blackwell 来加速各个领域实现 AI 驱动的创新。”
为了满足各类应用的需求,所发布的产品配置非常丰富,涵盖了从单 GPU 到多 GPU、从 x86到Grace、从风冷到液冷技术等。
此外,为了加快不同规模和配置的系统开发,NVIDIA MGX 模块化参考设计平台加入了对 NVIDIA Blackwell 产品的支持,包括全新 NVIDIA GB200 NVL2 平台,该平台专为主流大语言模型推理、检索增强生成和数据处理提供卓越的性能而打造。借助 NVLink-C2C 互连技术带来的高带宽内存性能和Blackwell 架构中专有的解压缩引擎,较使用x86 CPU时数据处理速度可提速最多达18倍,能效提高了8倍。
值得一提的是,AMD和英特尔都支持MGX 架构,并首次计划打造基于他们自己 CPU 主机处理器的模块设计,其中包括下一代 AMD Turin 平台和基于P核心的第六代英特尔至强处理器(原 Granite Rapids)。服务器系统厂商可以借助这些参考设计节省开发时间,并确保设计和性能的一致性。
“人工智能的出现之所以成为可能,是因为我们有这样一种坚定的信念:如果我们使计算成本越来越低,总会有人实现它的伟大用途。如今,我们已经实现了一个循环:部署基础在增长、计算成本在下降,这驱动更多的开发者提出更多的创意,从而推动了更多的需求……现在我们正处于一个非常重要、非常重要的开始阶段”,他强调。


在Blackwell出现之前,Hopper平台可能是历史上最成功的数据中心处理器。但是对于生成式AI应用来说, NVIDIA构建了整个包括CPU、GPU、网络连接等在内的平台,使Blackwell成为了新的产业引擎。
“8年内,我们使用Blackwell,将原本的1000千兆瓦时减少到了3千瓦时,这是一个令人难以置信的进步”,黄仁勋表示,“我们不会就此止步。在这种难以置信的增长期间,我们要确保继续提高性能、继续降低训练成本、推理成本,并继续扩大AI能力,让每个公司都拥抱它。”
公布最新路线图,回应网络平台演进方向
“我们公司的更新节奏是以年为单位。我们的基本理念非常简单:打造数据中心规模,以每年的节奏分步骤实现、并向客户交付产品,在各个领域实现技术突破,”黄仁勋解释道。
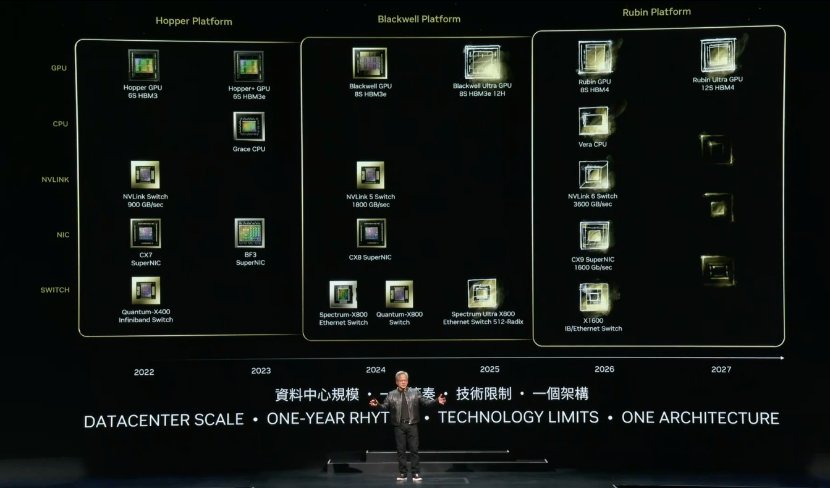
他“剧透”了最新的技术路线图,该路线图将每年更新。根据这一发布,我们可以看到NVIDIA将在明年推出增强版Blackwell Ultra GPU(配备8S HBM3e 12H)和Spectrum Ultra X800(Ethernet Switch 512 Radix)。
继加速计算能力的比拼之外,很显然,网络正在成为新的竞争焦点,特别是在以太网方面,多家行业巨头正在结成联盟。对于NVIDIA来说,其网络平台除了要考虑配合GPU的升级,同时也要面临业界的激烈竞争。这将如何推动NVIDIA网络平台的演进?核心的竞争点是什么?
对此,NVIDIA对<与非网>进行了回应:为了满足行业对性能的强烈需求,NVIDIA 计划每年推出新的Spectrum-X 产品,提供更高的带宽和端口,以及增强的软件功能集和可编程性,以推动领先的AI以太网网络性能。NVIDIA持续的性能改进节奏将建立在一系列关键创新之上,例如:自适应路由、拥塞控制和高频遥测等,这些创新加快了训练时间,同时还提供了噪声隔离、弹性和可编程性等优势。
NVIDIA方面强调,这些功能是他们所独有的,依赖于Spectrum交换机和NVIDIA BlueField 或 ConnectX SuperNIC 的专业化和差异化架构,同时保持完全以太网兼容,从而实现与现有数据中心基础设施的无缝集成。
此外,黄仁勋首次透露了Blackwell 的下一代平台Rubin。预计2026年推出的Rubin平台,将配备新 GPU、基于Arm的新CPU——Vera,以及采用 NVLink 6、CX9 SuperNIC 和 X1600、并融合 InfiniBand/以太网交换机的高级网络平台。
NVIDIA NIM让数百万人成为生成式AI开发者
在生成式AI推动的全栈重塑中,一个变革也在发生——计算机不再是我们使用的一个工具,它将具有生成AI的能力。
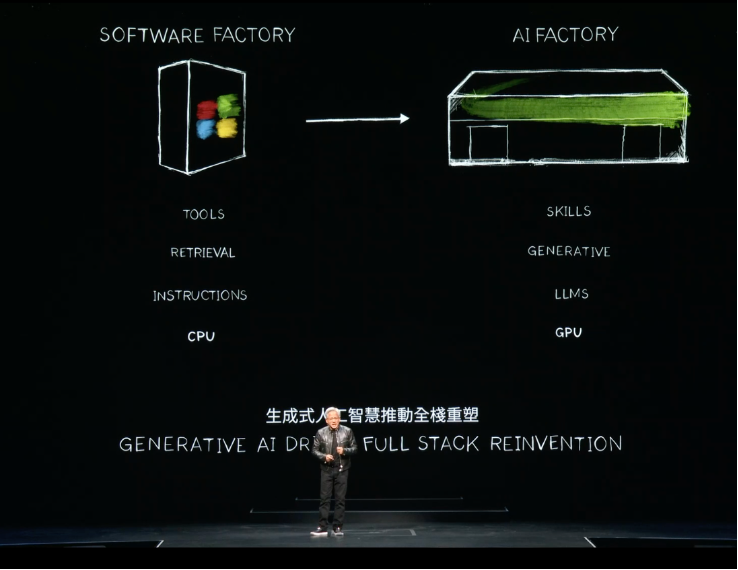
黄仁勋宣布,借助NVIDIA NIM推理微服务,全球2800万开发者都可以创建生成式AI应用。NIM 还能帮助企业实现基础设施投资的效果最大化。例如,与未使用NIM的情况相比,在NIM中运行 Meta Llama 3-8B 所能生成的加速基础设施AI token可以提升3倍。
Cadence、Cloudera、Cohesity、DataStax、NetApp、Scale AI 和新思科技等近 200 家技术合作伙伴正将 NIM 集成到他们的平台中,加快生成式 AI 部署到特定领域应用中的速度,例如copilots、代码助手、数字人虚拟形象等。从 Meta Llama 3 开始,在 Hugging Face上现已开始提供 NIM。
AI的下一波浪潮——物理AI
在演讲进入尾声时,黄仁勋强调了机器人和人工智能在未来发展中的重要性。他指出,“AI 的新一波浪潮是物理AI。AI能够理解物理定律,并与人类并肩作战。”
NVIDIA Isaac 平台为开发者构建AI机器人提供强大的套件,包括由 AI 模型以及Jetson Orin、Thor 等超级计算机驱动的 AMR、工业机械臂和人形机器人。
黄仁勋也强调了NVIDIA Isaac在提高工厂和仓库效率方面的作用,比亚迪电子、西门子、泰瑞达、Intrinsic 等企业都在使用 NVIDIA Isaac 的高级程序库和 AI 模型。
“机器人将遍布所有工厂。工厂将实现对机器人的统筹,而这些机器人将制造新的机器人产品,”黄仁勋表示,“机器人和物理AI正在成为现实,而不仅是出现在科幻小说。”

来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1703009.html

 下载ECAD模型
下载ECAD模型

