


 1224
1224
近日,Meta重磅推出其80亿和700亿参数的Meta Llama 3开源大模型。该模型引入了改进推理等新功能和更多的模型尺寸,并采用全新标记器(Tokenizer),旨在提升编码语言效率并提高模型性能。
在模型发布的第一时间,英特尔即验证了Llama 3能够在包括英特尔®至强®处理器在内的丰富AI产品组合上运行,并披露了即将发布的英特尔至强6性能核处理器(代号为Granite Rapids)针对Meta Llama 3模型的推理性能。
英特尔至强处理器可以满足要求严苛的端到端AI工作负载的需求。以第五代至强处理器为例,每个核心均内置了AMX加速引擎,能够提供出色的AI推理和训练性能。截至目前,该处理器已被众多主流云服务商所采用。不仅如此,至强处理器在进行通用计算时,能够提供更低时延,并能同时处理多种工作负载。
事实上,英特尔一直在持续优化至强平台的大模型推理性能。例如,相较于Llama 2模型的软件,PyTorch及英特尔® PyTorch扩展包(Intel® Extension for PyTorch)的延迟降低了5倍。这一优化是通过Paged Attention算法和张量并行实现的,这是因为其能够最大化可用算力及内存带宽。下图展示了80亿参数的Meta Lama 3模型在AWS m7i.metal-48x实例上的推理性能,该实例基于第四代英特尔至强可扩展处理器。
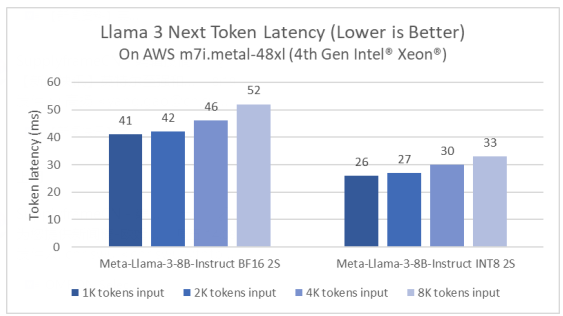
图1:AWS实例上Llama 3的下一个Token延迟
不仅如此,英特尔还首次披露了即将发布的产品——英特尔®至强® 6性能核处理器(代号为Granite Rapids)针对Meta Llama 3的性能测试。结果显示,与第四代至强处理器相比,英特尔至强6处理器在80亿参数的Llama 3推理模型的延迟降低了2倍,并且能够以低于100毫秒的token延迟,在单个双路服务器上运行诸如700亿参数的Llama 3这种更大参数的推理模型。
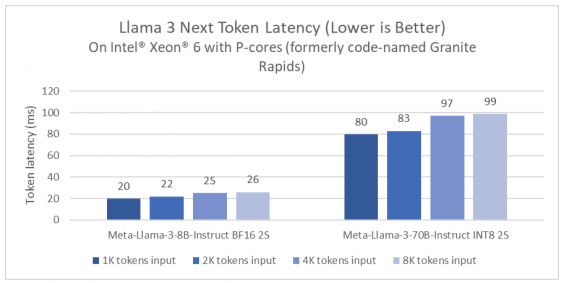
图2:基于英特尔®至强® 6性能核处理器(代号Granite Rapids)的Llama 3下一个Token延迟
考虑到Llama 3具备更高效的编码语言标记器(Tokenizer),测试采用了随机选择的prompt对Llama 3和Llama 2进行快速比较。在prompt相同的情况下,Llama 3所标记的token数量相较Llama 2减少18%。因此,即使80亿参数的Llama 3模型比70亿参数的Llama 2模型参数更高,在AWS m7i.metal-48xl实例上运行BF16推理时,整体prompt的推理时延几乎相同(该评估中,Llama 3比Llama 2快1.04倍)。
开发者可在此查阅在英特尔至强平台上运行Llama 3的说明。

 下载ECAD模型
下载ECAD模型






