


 1701
1701
生成式AI正在对算力产业产生更多需求。不过,这里所指的“算力”并不是单一维度的GPU或CPU性能和出货规模,插槽数量已经不能完全反映处理器芯片给市场带来的价值。底层技术和产业生态正在形成新的格局,这些变化已经给头部半导体企业带来紧迫感,他们在重新构思产品和商业模式。
英伟达和英特尔近期的一些新动向,非常明确地反映了这些变化,竞争已经不止于xPU异构处理器之间,而是聚焦于更广泛的软件服务、网络连接等全方位竞争。这种转变不仅重塑了两家公司的发展战略,也为整个行业带来了新的风向标。
AI推理成为重要方向
不约而同,英伟达和英特尔今年都在公开场合多次强调了AI推理的重要性和巨大潜力。英伟达2024财年Q4财报更是直接显示,其数据中心40%的收入来自推理。这其实是AI应用开始转向的重要标志,AI推理甚至可能比预期中的发展速度更快。
相较于训练,推理能够在已有模型训练的基础上响应指令,并且对功耗和成本的要求没那么高,这是否意味着推理业务更容易推进?当前又有哪些行业痛点需要解决?
埃森哲首席AI官Lan Guan近日在英特尔Vision大会上,谈到了企业部署AI的三个常见挑战:首先,企业难以从AI投资中获取更大价值,即使他们有明确定义的AI KPI,但这些通常只是任务为导向的方法,缺乏整体层面的聚合价值;其次,数据质量不足,大多数都是基于互联网的通用数据,而企业的隐私数据和通用模型结合是一个很大的挑战;第三是AI技能缺口,企业需要额外的培训或是专门的人才来构建、运营和管理AI,才能从项目中获取到相关的数据或反馈。
英伟达CEO黄仁勋在GTC 2024上则指出,推理其实是一种复杂的计算问题。眼下有各种各样的模型:计算机视觉模型、机器人模型以及丰富的开源语言模型等等,这些模型极具开创性,但是对于企业来说,面临着一系列问题:如何将模型部署到自己的应用中?该如何优化每一个AI模型?如何充分调度超级计算机的计算资源?如何才能快速高效地部署这些模型?
英伟达的微服务和英特尔的开放RAG
面向企业在生成式AI方面的瓶颈,英伟达和英特尔已经展开行动,软件AI是一个关键。
在之前的文章《黄仁勋:要成为AI界的“台积电”》中,我们探讨了英伟达最新推出的推理微服务(NIM)。简单说,就是把预训练的AI模型,经过封装和优化后集成在容器中,便于在庞大的英伟达部署环境中运行。
在CUDA环境中,上层还包括开源模型、合作伙伴专用模型以及英伟达所创建的模型,例如NVIDIA MoIMIM。这些模型封装在一起,包括对应版本的CUDA和cuDNN,支持分布式推理的NVIDIA TensorRT LLM,以及NVIDIA Triton推理服务器等。它可以根据实际情况进行优化部署,比如是单卡、多卡还是多节点,最终都通过简单易用的API来实现调用。
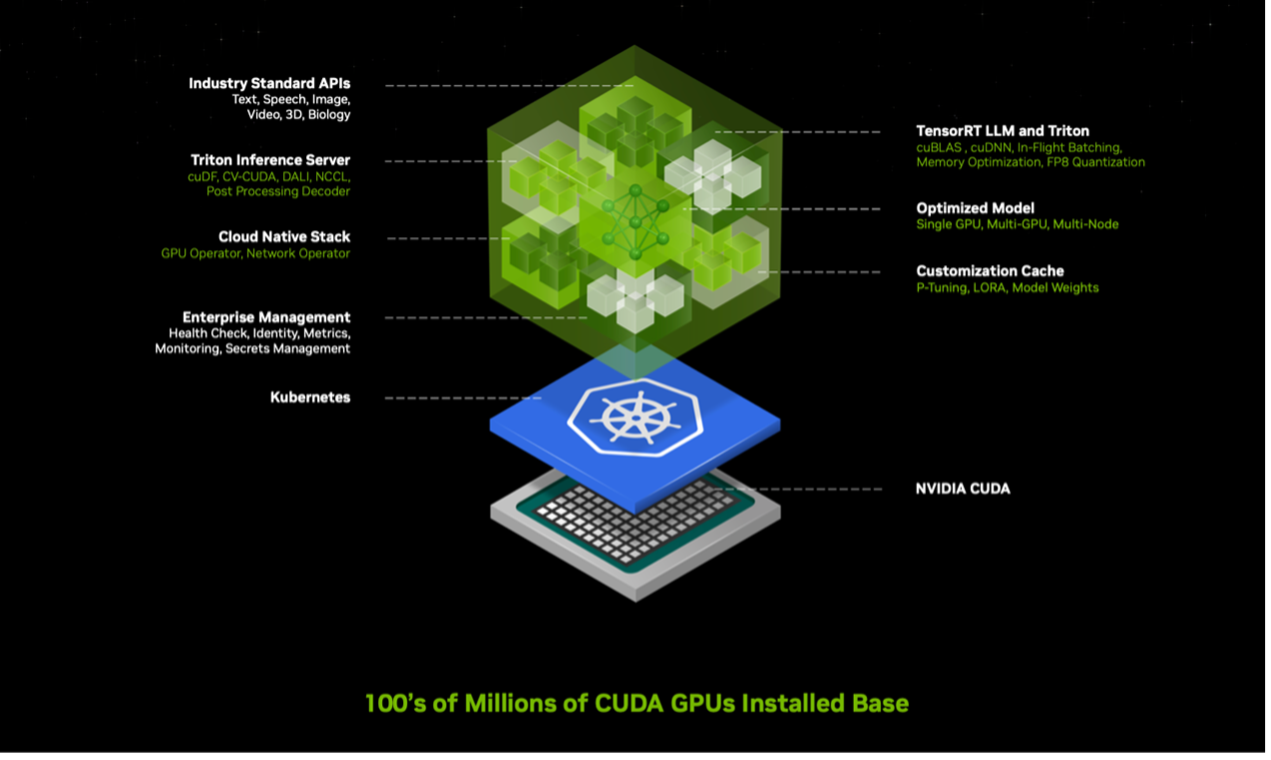
除了推理微服务(NIM),英伟达还提供云原生框架NeMo,它包含工具包、预训练模型等,可以帮助企业整理、准备数据,或是进行模型定制开发。此外还有DGX cloud基础设施,便于企业进行模型的微调和部署。
通过推理微服务+开发工具+基础设施,英伟达一如既往地通过全栈的方式来布局企业AI推理业务。
英特尔则洞察到了通过AI帮助企业提升数据检索和增强生成方面的机遇,并且正在通过RAG(检索增强生成),打造一个开放的、多供应商的系统。首批公布的联盟成员包括Anyscale、Deloitte、Hugging Face、RedHat、SAP、VMware等,涵盖供应链多个环节近20家企业。

RAG其实是结合了基于检索的模型和生成模型的能力,用来提高生成文本的质量和相关性。该方法能够让语言模型(LM)获取到内化知识之外的信息,并允许LM在专业知识库的基础上,以更准确的方式回答问题。在大模型时代,它成为了解决模型的幻觉问题、知识时效问题、超长文本问题等各种大模型本身制约或不足的必要技术。
关于RAG,英特尔院士、大数据技术全球首席技术官、大数据分析和人工智能创新院院长戴金权认为,构建生成式AI应用不仅仅是拥有一个大模型那么简单,实际上涉及创建一个完整的AI系统。RAG就是这方面的一个典型例子,它解决了如何对大模型进行知识增强的问题,通过结合个人、私有或垂直领域的知识,以及使用增强数据库、知识图谱和规划方法等技术,来构建复杂的AI系统,这也是生成式AI发展的一个趋势。
英特尔公司副总裁、英特尔中国软件和先进技术事业部总经理李映补充,RAG能够对企业内部私有数据和公开的大模型进行整合。通过开放联盟的形式,英特尔希望建立开放平台,促进不同RAG组件之间的互联互通。
AI高速互联——“封闭”和“开放”之争
随着大模型的规模增长至万亿参数,分布式并行系统成为满足推理和训练需求的关键。由于训练过程中产生的大量中间结果需要在多个加速卡之间共享,导致网络流量呈现瞬时并发特征,因此解决网络拥塞问题成为提升大模型性能和扩展规模的核心挑战。
当前,在AI大模型系统的互连技术中,主要存在两种方法:纵向(Scale up)和横向(Scale out)。Scale up专注于单个计算节点内部的互连,它主要处理的是节点内部不同加速卡之间的数据传输和通信。在AI应用中,Scale up允许多个处理器或加速器在同一节点内高效地共享数据,这对于保持高性能计算至关重要。例如,在训练大型神经网络时,节点内部的多个GPU需要频繁交换大量数据,Scale up技术能够确保这些交换快速且无缝进行,减少数据瓶颈和延迟。
而Scale out关注的是计算节点之间的互连。这种方法涉及将多个计算节点连接起来,形成一个强大的分布式计算网络。Scale out支持大规模并行处理,使得可以同时在多个节点上运行不同的计算任务。这种方法对于处理庞大的数据集和复杂的AI模型尤为重要,因为它允许系统扩展到更多的硬件资源,从而提高整体的处理能力和效率。
对于生成式AI所需的大规模计算集群来说,Scale out的能力尤为关键。这方面的玩家,当前以英伟达和超以太网联盟(UEC)为主要代表,该联盟的创始成员包括AMD、Arista、Broadcom、Cisco、Eviden(Atos 公司)、HPE、Intel、Meta 和 Microsoft,今年3月,联盟成员已增至55家。在之前的一篇文章《英伟达和AMD,GPU之外的下一个竞争高地》,对于大规模AI网络方案也有过详细的探讨。
针对高速互联当前存在的问题,英特尔中国网络与边缘事业部首席技术官、英特尔高级首席AI工程师张宇表示,InfiniBand封闭,而以太网虽然生态庞大、产品多样,但最初设计并未针对复杂应用场景,更适用于互联网这种可容忍数据包丢失的场景。但是在AI大模型训练中,数据包丢失可能导致巨大开销,因此需要一个可靠的网络系统来应对瞬时并发和脉冲式尖峰的网络流量。目前,以太网方案如RoCE V2协议已有所改进,但仍不完善。超以太网联盟正在改进以太网技术,创建端到端的协议,以应对大模型中的网络挑战。“开放的好处在于提供更多选择,能够降低成本,历史已多次证明这一点”,他强调。
事实上,英伟达在其AI加速网络中已经注意到了以太网的重要性。除了用InfiniBand 网络满足极低延迟和高吞吐量的HPC和AI工作负载,还针对以太网推出Spectrum-X,以提供更为广泛的连接选项。不久前的GTC上,英伟达宣布了Quantum-X800 InfiniBand 网络和Spectrum-X800 以太网络构成的X800系列的最新进展,据称端到端吞吐量已达到800Gb/s。
在<与非网>对英伟达网络亚太区高级总监宋庆春的采访中,他曾提到,数据中心的网络已经成为一个非常重要的计算单元,其中既包括计算能力,也包括通信能力,而更重要的是如何让计算和通信更好地得到融合,这是英伟达不断进行端到端优化的原因。
写在最后
由于生成式AI,训练的规模增大了很多。而企业对于生成式AI的大量推理运用,正导致AI应用处于拐点。
双“英”在全栈创新和生态打造方面,正以各自的方式展开激烈竞争。不论是提高算力利用率,提升卡间互联、多节点间互联水平,还是支持灵活稳定扩展和弹性容错,最终,打造先进的系统能力和广泛的生态水平成为竞争的关键。随着AI推理开启新一轮超级周期,相信接下来的竞争将更具看点。

 下载ECAD模型
下载ECAD模型











 [下载]LAT1482 STM32G0单线串口通信帧错误问题解析
[下载]LAT1482 STM32G0单线串口通信帧错误问题解析
