


 2456
2456
日前,英特尔举办了面向客户和合作伙伴的英特尔on产业创新大会(Intel Vision)。这次大会,英特尔面向生成式AI火力全开,CPU、AI加速器、AI互连网络、AI软件等都有重要升级。
大会期间,中国区几大业务线相关负责人(数据中心、行业云、网络与边缘、软件、大数据等)集体亮相,接受了<与非网>等媒体采访。从这次发言人的阵容,也可管窥英特尔在生成式AI的全栈战略,毕竟未来不是单点技术的比拼,更是全局战略和技术平台的较量。
企业生成式AI——开放平台,互联互通
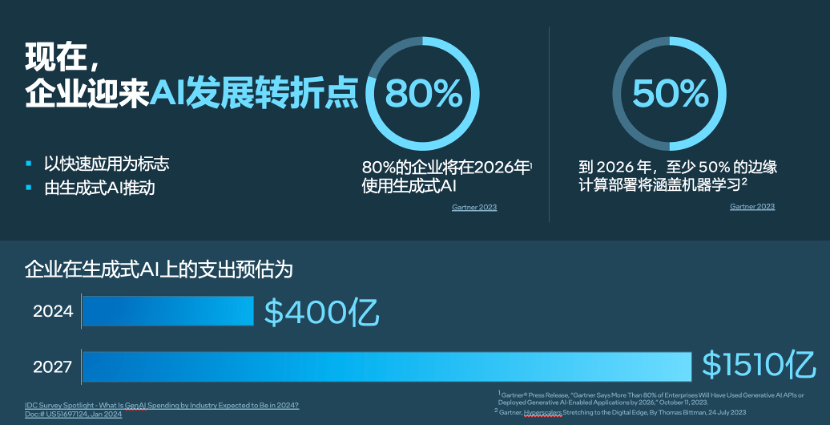
关于生成式AI在企业中的应用,英特尔市场营销集团副总裁、中国区数据中心销售总经理、中国区运营商销售总经理庄秉翰分享了几组数据洞察:预计2026年,80%的企业将会使用生成式AI,50%的企业会在边缘计算部署中涵盖机器学习。而企业在生成式AI的投资,预计今年达到400亿美元规模,2027年则会达到1510亿规模。
在企业生成式AI这个大市场,英特尔首先洞察到了“数据”蕴藏的巨大机遇。Accenture首席AI官Lan Guan在和英特尔CEO帕特·基辛格(Pat Gelsinger)的对谈中,提到了企业部署AI的三个常见挑战:首先是企业难以从AI投资中实现更大价值,即使他们有明确定义的AI KPI,但这些通常只是任务为导向的方法,缺乏整体层面的聚合价值;其次是数据质量不足,大多数都是基于互联网通用数据,而企业的隐私数据和通用模型结合是一个很大的挑战;第三是AI技能缺口,企业需要额外的培训或是专门的人才来构建、运营和管理AI,以便从项目中获取到相关的数据或反馈。
那么,企业究竟该如何部署生成式AI?如何帮助他们释放庞大的、专有的数据集的价值?帕特·基辛格认为,不论是从经济性、即时响应能力还是数据的安全角度,边缘AI都已是大势所趋。
正因如此,英特尔首先希望通过AI帮助企业提升在数据检索和增强生成方面的能力,帮助他们在整个工作流程中顺畅地实施AI。
RAG(检索增强生成)技术——是英特尔最新推出的用于解锁企业数据资产的生成式AI系统。通过联合Anyscale、Articul8、DataStax、Domino、Hugging Face、KX Systems、MariaDB、MinIO、Qdrant、RedHat、Redis、SAP、VMware、Yellowbrick和Zilliz,这一开放的、多供应商的系统,可使企业在标准云基础设施上运行的大量现存专有数据源得到开放大语言模型(LLM)功能的增强。
英特尔院士、大数据技术全球首席技术官、大数据分析和人工智能创新院院长戴金权认为,构建生成式AI应用不仅仅是拥有一个大模型那么简单,实际上涉及创建一个完整的AI系统,其中包括大模型和其他组件,以形成一个工作流。RAG就是一个典型的例子,它解决了如何对大模型进行知识增强的问题,通过结合个人、私有或垂直领域的知识,以及使用增强数据库、知识图谱和规划方法等技术,构建复杂的AI系统。
近期一些新的应用场景,如Copilot,无论是用于编写代码还是个人电脑使用,都体现了生成式AI的实际应用。“在这些复杂的AI系统中,大模型充当着核心控制器或大脑的角色,与个人和私有知识以及其他工具相结合,以解决各种应用场景的问题,这是生成式AI发展的趋势”,戴金权表示。
英特尔公司副总裁、英特尔中国软件和先进技术事业部总经理李映补充,RAG能够对企业内部私有数据和公开的大模型进行整合。通过开放联盟的形式,英特尔旨在建立一个开放平台,促进不同RAG组件之间的互联互通,共同推动企业AI架构的构建和发展。这一战略不仅加强了企业内部数据的利用,还推动了整个AI生态系统的创新和协作。
李映也分享了英特尔的AI软件战略,他表示,未来,英特尔软件业务非常重要的一方面是如何通过软件加速企业AI的发展。而企业AI的软件发展方向集中在如何将传统的云架构与新兴的、基于大数据和大模型的AI架构相融合。
软件在此过程中扮演着加速器的角色,确保无论是CPU还是GPU,硬件性能得到最大化利用,并促进不同硬件架构之间的互操作性。此外,软件还负责在传统架构和AI应用之间进行资源的高效分配和管理。英特尔不仅是AI软件创新的推动者,例如在PyTorch框架中的重要贡献,而且还致力于将最新的技术成果集成到开源框架中,如oneAPI的推广和应用。
算力升级——至强6、Gaudi 3齐开“卷”
至强6品牌焕新
在大模型和生成式AI智力涌现的背后,算力是行业关注的重点。英特尔的至强系列推出第六代产品,不同于以往单一产品的推出,此次是基于两种微架构设计:性能核(P-core)和能效核(E-Core)的产品组合,旨在解决数据中心在性能、功耗和多样化工作负载等方面的挑战。
配备能效核的英特尔至强6处理器(此前代号为Sierra Forest),可将机架密度提高2.7倍;客户能以近3:1的比例替换旧系统,大幅降低能耗,帮助其实现可持续发展目标。这意味着,如果使用第二代至强可扩展处理器需要200个服务器机架的话,转而使用能效核只需要72个服务器机架。这样的改进不仅大幅减少了所需的物理空间,还节省了超过1兆瓦的功耗。
配备性能核的英特尔至强6处理器(此前代号为Granite Rapids),包含了对MXFP4数据格式的软件支持,与使用FP16的第四代至强处理器相比,可将下一个令牌(token)的延迟时间最多缩短6.5倍,能够运行700亿参数的Llama-2模型。
英特尔市场营销集团副总裁、中国区云与行业解决方案部总经理梁雅莉,首先以金山云的合作案例,介绍了至强在提升云服务性能方面的重要作用。通过与金山云的合作,英特尔针对X7云服务器进行了优化,显著提高了Stable Diffusion、Llama2和ChatGLM2等大模型的推理性能,其中Stable Diffusion的性能提升了4.96倍。这种优化不仅使算力更易于获取、具有通用性和可靠性,还简化了部署过程,降低了成本,并允许灵活运行其他负载。
此外,京东云基于搭载至强的基础设施,在智能营销和客服等领域实现了AI的广泛应用,新一代云服务器性能提升23%。
除了云服务,英特尔在智能制造、医疗和教育等多个关键行业在推动AI技术的应用。在智能制造领域,与TCL华星合作提升生产效率、降低成本;在医疗领域,与英矽智能共同利用AI加速药物发现过程;在教育领域,与华东师范大学合作开发大模型一体机,提高教师工作效率并支持终身学习。
梁雅莉表示,去年,“百模大战”重点关注AI大模型的训练;而今年,头部互联网和大模型公司面临的挑战是如何将生成式AI落地并变现;其他企业则需要考虑如何选择适合的大模型来融入生产或业务流程中创造价值。
“这要求企业根据具体情况选择最合适的AI策略和基础设施,企业需要考虑如何在确保经济适用性的同时,找到最合适的方案来实现AI的实际价值”,她补充,“英特尔致力于将AI技术落地,为行业带来实际价值。”
用于AI训练和推理的Gaudi 3
再来看最新发布的英特尔Gaudi 3 AI加速器。与上一代产品相比,英特尔Gaudi 3将带来4倍的BF16 AI计算能力提升,以及1.5倍的内存带宽提升。该加速器将为寻求大规模部署生成式AI的企业带来AI训练和推理方面的重大飞跃。

另据英特尔公布的Gaudi 3芯片与英伟达H100芯片的比较,推理能力平均提高50%,能效平均提高40%,运行人工智能模型的速度是H100的1.5倍。
在训练70亿和130亿参数Llama2模型、以及1750亿参数GPT-3模型时,英特尔Gaudi 3可大幅缩短训练时间。此外,在Llama 7B、70B和Falcon 180B大语言模型(LLM)的推理吞吐量和能效方面也展现了出色性能。
值得一提的是,Gaudi 3 AI加速器采用以太网通用标准连接,这一被广泛应用的行业标准有助于单个节点向拥有数千个节点的集群进行扩展,比如在AI系统中连接多达数万个加速器,支持大规模的推理、微调和训练。
英特尔还将首次提供采用PCIe规格的Gaudi 3版本,HL-338卡是一款10.5英寸的全高双槽PCIe卡,提供与OAM Gaudi 3相同的所有硬件,甚至可达到1835 TFLOPS FP8的峰值性能。
AI高速互联,推动开放式以太网网络创新
AI系统目前主要还是基于冯·诺依曼架构,依赖于计算能力和数据传输性能。随着大模型的规模增长至万亿参数,分布式并行系统成为满足推理和训练需求的关键。由于训练过程中产生的大量中间结果需要在多个加速卡之间共享,导致网络流量呈现瞬时并发特征,易造成拥塞,因此解决网络拥塞问题成为提升大模型性能和扩展规模的核心挑战。
当前,在AI大模型系统的互连技术中,主要存在两种方法:纵向(Scale up)和横向(Scale out)。Scale up专注于单个计算节点内部的互连,它主要处理的是节点内部不同加速卡之间的数据传输和通信。在AI应用中,Scale up允许多个处理器或加速器在同一节点内高效地共享数据,这对于保持高性能计算至关重要。例如,在训练大型神经网络时,节点内部的多个GPU需要频繁交换大量数据,Scale up技术能够确保这些交换快速且无缝进行,减少数据瓶颈和延迟。
而Scale out关注的是计算节点之间的互连。这种方法涉及将多个计算节点连接起来,形成一个强大的分布式计算网络。在AI领域,Scale out支持大规模并行处理,使得可以同时在多个节点上运行不同的计算任务。这种方法对于处理庞大的数据集和复杂的AI模型尤为重要,因为它允许系统扩展到更多的硬件资源,从而提高整体的处理能力和效率。
为了支持大规模scale-up和scale-out高速互联,英特尔正在通过超以太网联盟(UEC),驱动面向AI高速互联技术(AI Fabrics)的开放式以太网网络创新,并推出一系列针对AI优化的以太网解决方案。英特尔的产品组合包括英特尔AI网络连接卡(AI NIC)、集成到XPU的AI连接芯粒、基于Gaudi加速器的系统,以及一系列面向英特尔代工的AI互联软硬件参考设计。
英特尔中国网络与边缘事业部首席技术官、英特尔高级首席AI工程师张宇表示,当前在Scale out互连技术领域,InfiniBand较为封闭,而以太网虽然生态庞大、产品多样,但最初设计并未针对复杂应用场景,更适用于互联网这种可容忍数据包丢失的场景。但是在AI大模型训练中,数据包丢失可能导致巨大开销,因此需要一个可靠的网络系统来应对瞬时并发和脉冲式尖峰的网络流量。目前,以太网方案如RoCE V2协议已有所改进,但仍不完善。
超以太网联盟旨在改进以太网技术,创建端到端的协议,以应对大模型中的网络挑战。目前联盟已发布相关白皮书,英特尔在其中做出了贡献,并希望将这些开放协议应用于产品中,实现不同厂商和合作伙伴产品的协同工作,构建完整网络。“开放的好处在于提供更多选择,能够降低成本,历史已多次证明这一点”,张宇强调。
今年下半年,英特尔将推出第一代基于ASIC IPU的产品,也就是基础架构处理器产品。它能够提供200GB/s的速度,同时能够提供灵活的包处理能力,满足大模型时代的网络要求。
另据透露,AI NIC会有两种形态:一是独立网卡,可以和不同加速器进行对接;另一种是芯粒形态,不同AI加速器甚至可以把AI NIC集成到SoC芯片中,英特尔2026年推出的AI加速器将会集成AI NIC。

写在最后
如果要描述英特尔生成式AI的战略方向,个人认为“开放、生态、系统化”比较有代表性。面对生成式AI对更高、更强算力的狂热追求,英特尔更加注重发挥开放平台和强大生态的力量,并且正在通过旗下的全栈技术去形成更有竞争力的系统化方案。
帕特·基辛格演讲中的一张图令人印象深刻,针对企业AI,英特尔联合了近20家公司去构建了一个开放平台。
生成式AI趋势下,开放、开源、闭源技术在并行演进,玩家越来越多,在这个自然演变的过程中,难以预测谁是未来的大赢家,也正是如此,这个联盟初次亮相就有如此丰富的阵容。而包括英特尔在内的联盟成员,如何推动标准框架的演进,融入更多、更开放的玩家,保证产业进程整体的发展方向,将是一场谁都不能丢棒的接力赛。

来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1685580.html

 下载ECAD模型
下载ECAD模型

