


 1462
1462
最大GPU提供商英伟达,业绩暴涨,市值屡创新高。就在全世界都瞩目英伟达如何继续打造GPU帝国时,英伟达CEO黄仁勋却在刚刚举办的GTC 2024上公开表示:“我们要做AI Foundry,就像台积电在整个半导体供应链所处的位置一样,我们要做整个AI产业的代工厂。”
对标台积电对整个半导体产业的价值逻辑,来看英伟达对整个AI产业的布局,这会开启更广阔的未来吗?
AI代工厂:英伟达的新故事
台积电以芯片代工模式进入全球半导体市场以来,每年以高额资本支出投入研发和先进制程技术。2023年,台积电一举成为全球营收最高的半导体公司,在它身上,充分展现了芯片代工优于对手的显著优势,以及精准业务模式长期做功的影响力。
再来看黄仁勋的最新定位,英伟达两万亿的市值新高度,也需要他继续引领转型和寻求更大的愿景空间。
在黄仁勋的全球媒体会上,<与非网>就“AI代工厂的长期目标和策略”进一步寻求了他的解读。黄仁勋表示:“AI代工厂的目标就是要构建软件AI,而不是把软件当做工具。很久以前,英伟达就创立了两个重要的软件,一个是Optics,也就是后来的RTX;另一个是cuDNN,这是一个AI库。”

黄仁勋提到的这两款软件——RTX奠定了英伟达在专业视觉计算领域的地位,cuDNN(NVIDIA CUDA深度神经网络库)则成为深度学习研究和框架开发实现高性能GPU加速的利器。
作为一家GPU芯片起家的硬件公司,英伟达身上的软件色彩一直很浓厚,多种多样的库(library)造就了英伟达在软件领域的根基。面向未来,黄仁勋又将如何构建软件AI的基础?
黄仁勋认为,“未来的库应该是微服务(Microservice)。因为未来的库不仅用数学描述,还可以用AI来描述。从命名上,过去的库是一系列的CU,比如CuLitho、CuDNN等,未来则会是一系列的NIM,它们是使用NVIDIA库的一种新方法。“
而之所以构建微服务,是因为黄仁勋看到了企业推理业务当前的痛点,以及未来的巨大潜力。
眼下有各种各样的模型:计算机视觉模型、机器人模型以及丰富的开源语言模型等等,这些模型极具开创性,但企业使用起来有难度:如何将模型部署到自己的应用中?模型又该如何封装和运行?
黄仁勋解释说:“推理其实是一种复杂的计算问题,企业该如何优化每一个AI模型?如何充分调度超级计算机的计算资源?如何才能快速高效地部署这些模型?面对这些问题,我们创造了用收发请求来进行软件开发的新方法。它实质上是把软件都集成到一个容器中,这个容器就是NVIDIA推理微服务(NIM)。”
NIM其实是一个经过预训练的AI模型,经过封装和优化,可以在庞大的NVIDIA部署环境中运行。因为模型都是预训练好的,因此知道什么是合理的输出。

进一步拆开NIM来看,如下图,在NVIDIA CUDA的部署环境中,上层还包括开源模型、合作伙伴专用模型以及英伟达所创建的模型,例如NVIDIA MoIMIM。这些模型封装在一起,包括对应版本的CUDA和cuDNN,支持分布式推理的NVIDIA TensorRT LLM,以及NVIDIA Triton推理服务器等。它可以根据实际情况进行优化部署,比如是单卡、多卡还是多节点,最终,都通过简单易用的API来实现调用。
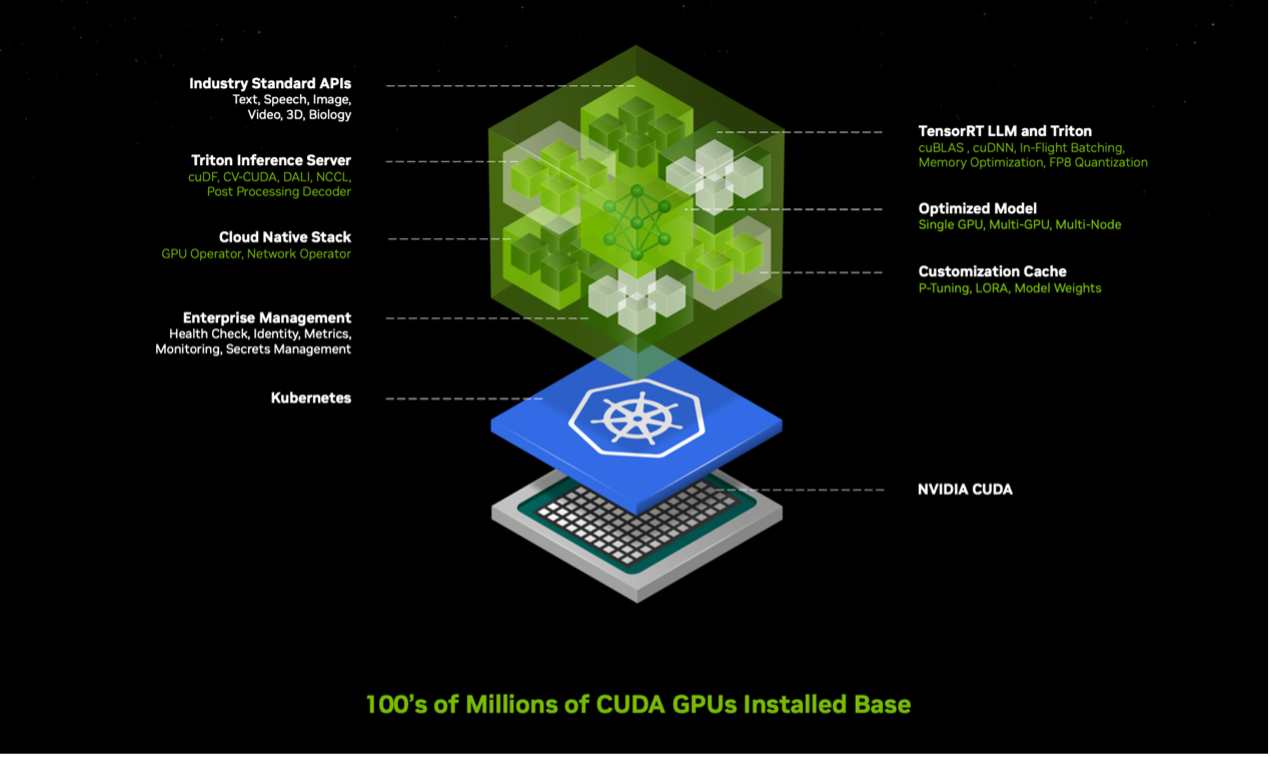
“实际上,我们就是一家‘AI代工厂’,正如台积电为我们制造芯片一样,我们将为整个行业代工生产AI“,黄仁勋提出。
他解释说,作为‘AI代工厂’,英伟达的工作主要有三大块:第一,发明AI模型技术,运行AI模型并对其进行封装,也就是NIM;第二,提供模型定制开发工具,NeMo微服务可以帮助用户整理和准备数据,以便对AI进行初始训练。第三,提供基础设施,便于实现模型的微调和部署,用户可以部署在DGX cloud基础设施上,也可以部署在本地,或是他们需要的任何地方。
黄仁勋透露,英伟达已经在公司内部部署了NIM,创建了各个领域的聊天机器人作为工作助理,其中一个最重要的聊天机器人就用于芯片设计,来帮助英伟达提升芯片设计的效率。
“这些NIM是超级复杂的软件、性能很高。但它具备简单的API调用形式,这个API叫做人类。人们可以访问网站使用,也可以下载到本地电脑、PC,或是在其它云上、工作站、用户自己的数据中心……当运行这些库时,操作系统会进行授权,授权费用为4500美元/GPU/年,用户可以在上面运行任意多的模型”,黄仁勋表示。
事实上,这些微服务相当于为英伟达的全栈计算平台增添了新的一层,连接起了由模型开发人员、平台提供商和企业组成的AI生态系统。通过这些微服务,一方面,企业可以在自己的平台上创建和部署定制应用,同时保留对知识产权的完整所有权和控制权;另一方面,他们能够在CUDA环境中,通过标准化路径运行优化过的定制AI模型。
这就是 “AI代工厂”的精髓:强调专业化支持和资源共享、降低产业门槛、为AI高效率部署提供协助。
生成式AI驱动变革,英伟达重视推理
促使黄仁勋从根本上对未来业务进行梳理和思考的,根源上看应该是数据,是生成式AI的到来,使数据的产生和流转产生了本质的变化。
互联网时代,我们查询或获取数据的方式主要是检索,即:从数据集中检索数据、处理数据、然后传递数据。“未来,越来越多的数据将是基于生成的,而不是检索获得的。这一切其实已经在发生,我们现在打开手机获取到的信息,往往已经是基于推荐系统、以一种有意义的方式组合、处理后呈现出来的信息,这其中用到了大量计算,是与上下文相关的、是智能的”,黄仁勋解释说。
“未来,如果每一个像素、每一次交互都通过生成过程产生,每一次人机交互都是生成式的体验,那么,这将是一个巨大的机遇“,他说道。
这也就不难理解,为什么在今年的GTC上,“推理”被黄仁勋如此高频地提及——发布Blackwell新架构时,花了好几分钟介绍了它的推理表现;发布微服务时,着重介绍了推理微服务。当一家做云端生意的公司,大说特说推理业务时,是时代变了,还是时候到了?
对于企业来说,云端训练是一个烧钱的过程,相当于养娃,各种培训、补习班都是在砸钱。只有云端训练做得差不多了,娃能用学到的技能开始赚钱了,才能慢慢产生收益。对于AI来说,这就是通过推理业务进入市场的过程。
从公开信息来看,Blackwell 在单芯片训练方面的FP8性能是其上一代架构的2.5倍,在推理方面的FP4性能是其上一代架构的5倍。这使得最新的Blackwell 平台,具有对万亿参数大语言模型进行实时生成的能力。
此外,基于Blackwell和NVLink Switch新芯片,英伟达打造了一个多节点、液冷、机架级系统NVIDIA GB200 NVL72 。它能利用 Blackwell为万亿参数模型提供强力计算,在单个机架中可实现720 petaflops的AI训练性能和1.4 exaflops的AI推理性能。
同样以90天训练GPT-MoE-1.8T参数模型为例,Hopper系统需要8000个GPU,能耗15MW;而Blackwell GB200 NVL72系统,仅需要2000个GPU,能耗4MW,GPU数量和能耗约是上一代系统的1/4。


相同训练时间下,Blackwell平台展现了更高能效、可以挑战极限的能力。“我们必须弄清楚物理极限,达到极限,并要超越极限,而能源效率和成本效率是首要任务”,黄仁勋说。
写在最后
从加速计算先驱,到推动生成式AI变革,英伟达现在是一家全栈计算基础设施公司。
正如黄仁勋在采访中所强调,“英伟达的市场机会并不是GPU的机会,而是可以投射到整个数据中心的机会,这是每年2500亿美元的市场,并以每年20%至25%的速度在增长。我对GPU的思考也不是GPU,而是GPU之外的线缆、机架、交换机……我们不只做GPU芯片,我们做的是数据中心需要的一切。”
今年的GTC,也确实呈现出更明确的系统化方向:硬件通过完整的Blackwell平台面向数据中心、超算,软件方面提供一系列的微服务。在“推动全球AI基础设施大规模升级”的目标之下,“AI代工厂”成为英伟达触达用户需求、撬动大规模市场的关键一步。
就像台积电当年首创Foundry模式,半导体产业从IDM(集成设备制造商)逐渐转变为Fabless(无晶圆厂)模式,半导体设计进入空前繁荣期,也向更多中小型企业敞开了大门。生成式AI的未来,也将如此。
“企业IT行业正坐在一座‘金矿’上”,黄仁勋说道,“他们拥有多年来创建的工具和数据。如果他们能把这个‘金矿’变成 AI 助手,就能给用户提供更多可能。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1677405.html

 下载ECAD模型
下载ECAD模型

