


















 5716
5716
当GPU以其强大的并行计算能力,登上AI算力王座时,AI芯片领域的竞争在日趋激烈。其中,神经网络处理器(NPU)作为一股重要的力量,也在悄然崛起。
就像GPU从最初的图像渲染和通用并行计算,逐步引入越来越多的神经网络功能(比如 Tensor Cores、Transformer等),NPU 也在“双向奔赴”,在神经网络的基础上,融入越来越强大的通用计算功能。
由于NPU针对神经网络计算进行了专门的优化,在处理复杂神经网络算法时有更高的效率和更低的能耗,特别是在端侧和边缘侧,能够为AI应用提供有力的支撑。从近期的种种市场动态来看,NPU有望开启大规模商用时代。
国产NPU IP持续上量
近年来,国产NPU最显著的应用就是手机,比如华为的麒麟9000处理器,通过对ISP和NPU进行融合,大大提升了数据的缓冲和处理效率;OPPO曾经的自研NPU马里亚纳X,在拍照、拍视频等大数据流场景下实现了更好的运算效率,助OPPO拉开了在高端智能手机领域的体验差距。
随着AI需求逐渐从云端传导到边缘和端侧,端、边市场的AI算力需求在逐渐爆发,推动新一轮本地AI算力的升级潮,而NPU有望成为本地AI任务的算力主力。
芯原近日宣布,集成其NPU IP的AI芯片在全球范围内出货超过1亿颗,已被72家客户用于128款AI芯片中,用于物联网、可穿戴设备、智慧家居、安防监控、汽车电子等10个市场领域。
芯原的NPU基于GPU架构体系进行优化,利用其可编程、可扩展及并行处理能力,为各类主流AI算法提供硬件加速的微处理器技术。最新一代NPU架构包括GPGPU处理模块PPU和AI处理模块Tensore Core,GPGPU支持大规模通用计算和类ChatGPT应用,Tensor Core在处理器架构、AI软件框架及工具、功耗与效能等方面进行创新,在卷积神经网络、高算力低功耗等技术上实现了突破。通过NPU IP架构和GPU的融合,可以支持图形渲染、通用计算以及AI处理。
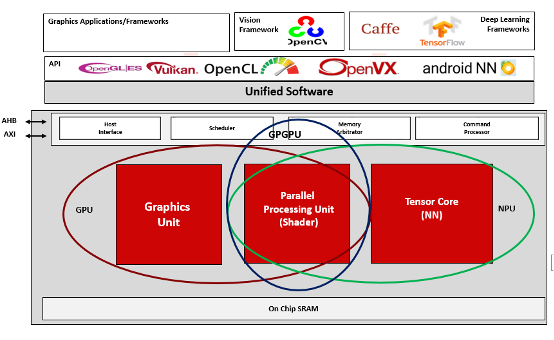
图:芯原 NPU IP+GPU IP融合的计算平台(来源:芯原官微)
芯片IP设计与服务供应商安谋科技,在成立之初即开始自研首款“周易”NPU,目前该产品线已迭代了Z系列和X系列的多款产品,满足各种端侧硬件设备的不同AI计算需求,应用于中高端安防、智能家居、移动设备、物联网、智能座舱、ADAS、边缘服务器等市场。
最新的“周易”NPU采用第三代“周易”架构,在算力、精度、灵活性等方面进行了大幅提升,支持多核Cluster,最高可达320TOPS子系统,并通过TSM任务调度充分发挥计算单元效能以及采用i-Tiling技术大幅减少带宽,支持大模型的基础架构Transformer。

图:新一代“周易”NPU主要功能升级(来源:安谋科技官网)
据了解,在下一代“周易”NPU的设计上,安谋科技将从精度、带宽、调度管理、算子支持等多个方面对主流大模型架构进行迭代优化,为端侧AI落地提供关键性的算力支撑。商业化落地方面,目前“周易”NPU已和全志科技、芯擎科技、芯驰科技等多家本土芯片厂商实现了合作。
巨头纷纷入场,生态快速成长的讯号
随着生成式AI的应用场景不断扩大,NPU能够满足基于Transformer架构的大模型需求,有望在这一趋势下渗透到更多深层场景,进一步拓展产业生态,特别是在巨头的推动下,有望迎来高速增长。
高通最近就提出,通过NPU和异构计算将开启终端侧生成式AI时代。其Hexagon NPU面向低功耗、高性能的AI推理而设计,通过定制设计NPU和控制指令集架构(ISA),能够快速进行设计演进和扩展。
根据官方资料,高通的DSP控制和标量架构奠定了NPU的基础。多年来,通过融入标量、向量和张量加速器以及分组卷积等改进,不断进行了提升。迭代到目前第三代骁龙8中的Hexagon NPU是专门针对终端侧生成式AI大模型推理的最新设计,包括了跨整个NPU的微架构升级、微切片推理升级等,为持续的AI推理实现了98%的性能提升和40%的能效提升。
从架构路线来看,高通认为由DSP架构入手打造NPU是正确选择,因为可以改善可编程性,并能够紧密控制用于AI处理的标量、向量和张量运算。
而除了高通,两大处理器巨头英特尔和AMD也在积极拥抱NPU。
去年12月8日,AMD发布了锐龙8040系列处理器,最核心的变化之一就是新增了AI计算单元。根据AMD的说法,得益于NPU的加入,锐龙8040系列处理器的AI算力从10TOPS提升到了16TOPS,性能提升幅度达到了60%。这让锐龙8040系列处理器在LLM等模型性能更加突出,例如Llama 2大语言模型性能提升40%,视觉模型提升40%。
一周之后,英特尔新一代酷睿Ultra移动处理器正式发布,这是其40年来第一个内建NPU的处理器,用于在PC上带来高能效的AI加速和本地推理体验,这也是英特尔客户端处理器路线图的一个转折点。英特尔将NPU与CPU、GPU共同视作AI PC的三个底层算力引擎。
据其介绍,2024年,将有230多款机型搭载酷睿Ultra。

尽管巨头在NPU的打造路线上各有千秋,但是都无一例外地看准了一个机会——端侧AI,而拥有专门的NPU成为端侧AI的一大特点,NPU正在成为本地运行AI任务的主力。
当前,高通主要以AI手机、XR、AI PC等为主,AMD和英特尔则主要在AI PC布局。
AI手机方面,IDC直接依据NPU算力将其分为两类,一类是已经在市面上销售了近十年的硬件赋能AI手机(≤30NPU TOPS):使用加速器或除主要应用处理器之外的专用处理器,以较低功耗运行端侧的AI。这类手机最近转向使用NPU内核,使用int-8 数据类型,性能达30 TOPS。端侧AI的示例包括自然语言处理(NLP)和计算摄影。
另一类则是最新一代的AI手机(>30 NPU TOPS):这些智能手机使用能够更快、更高效地运行端侧生成式AI模型的SoC,并且使用int-8数据类型的NPU性能至少为30 TOPS。端侧的生成式AI示例包括Stable Diffusion和各种大型语言模型。这类智能手机在2023年下半年首次进入市场。
AI PC方面,目前市场整体处于AI Ready向AI On的过渡阶段。据Canalys预测,兼容AI的个人电脑有望在2025年渗透率达到37%,2027年兼容AI个人电脑约占所有个人电脑出货量的60%,未来AI PC的主要需求来源为商用领域。同时AI PC将会为PC行业发展提供新动能,根据IDC预测,中国PC市场将因AI PC的到来,结束负增长,在未来5年中保持稳定的增长态势。
多模态、轻量化,促进端侧AI算力持续升级
AI一直致力于以技术实现计算机对于人类认知世界方式的高度效仿。而多模态AI的兴起,使得AI系统能够更全面地理解和处理现实世界中的复杂信息。除传统的语言以及图像间的交互作用,其结合声音、触觉以及动作等多维度信息进行深度学习,从而形成更准确、更具表现力的多模态表示。这也是AI模型走向多模态的必然因素:跨模态任务需求+跨模态数据融合+对人类认知能力的模拟。
目前看来,提供自然语音用户界面以提高生产力、同时增强用户体验的个人助手,正在成为流行的AI应用。语音识别、大语言模型和语音模型,将以某种并行方式运行,因此理想的情况是在NPU、GPU、CPU等处理器之间分布处理模型。对于端侧设备来说,比如PC,出于性能和能效考虑,应当尽可能在NPU上运行。
根据Trendforce,微软计划在Windows12为AI PC设置最低门槛,需要至少40TOPS算力和16GB内存。也就是说,PC芯片算力跨越40TOPS门槛将成为首要目标,这也将进一步推进NPU的升级方向,比如:提升算力、提高内存、降低功耗,芯片持续进行架构优化、异构计算优化和内存升级。
此外还有轻量化模型发展趋势,NPU芯片以其低功耗、高效率的特点,成为实现轻量化AI大模型在边缘设备上运行的关键。
自 2023 年起,大模型参数量出现显著分化,轻量化模型的出现逐步推动AI向端侧场景落地。比如最近就有谷歌发布的开源轻量化大模型 Gemma,该模型与多模态大模型Gemini采用相同的研究和技术构建,有2B和7B两个版本,可以直接在笔记本和台式机部署。
由于轻量化模型可以降低在边缘侧部署的成本门槛,使模型的下游应用程序适合于更多的应用程序和用户,因此为大模型推理计算从云端向边缘端转移提供了可能,使AI技术更广泛地应用于各种场景成为可能。
写在最后
在AI从云到边、端的下沉运动中,不论是应用类型的多样化、还是技术本身的突破,或是巨头的大规模开“卷”,都代表着NPU终于迎来重要拐点,有望开启一个大规模商用的全新时代。
从早期主要面向音频和语音AI应用而设计,基于简单的卷积神经网络(CNN)进行标量和向量数学运算;再到拍照和视频AI的兴起,出现了基于Transformer、循环神经网络(RNN)、长短期记忆网络(LSTM)和更高维度的卷积神经网络(CNN)等复杂的全新模型,NPU逐渐增加了张量加速器和卷积加速,处理效率大幅提升。
再到近两年,随着大语言模型(LLM)和大视觉模型(LVM)的爆发,模型的大小提升超过了一个数量级。我们看到,NPU不断在功耗、性能、能效、可编程和面积之间寻求权衡,保持与AI发展方向的一致性,并始终在寻求更大的发展空间。
算力始终是AI应用的基石,考虑到NPU的灵活性和高速的运算效率,它是否有望到达GPU的高度,让业界说一句:无NPU,不AI?

 下载ECAD模型
下载ECAD模型




