


 2187
2187
2023年,大模型的突破和生成式AI的兴起,正在引领AI产业迈入智能创新的新阶段,同时也将引发算力架构的新变局。
根据最新发布的《2023-2024年中国人工智能计算力发展评估报告》,全球人工智能硬件市场(服务器)规模将从2022年的195亿美元增长到2026年的347亿美元,五年年复合增长率达17.3%;在中国,预计2023年中国人工智能服务器市场规模将达到91亿美元,同比增长82.5%,2027年将达到134 亿美元,五年年复合增长率达21.8%。中国算力市场、特别是智算领域,正在蓬勃发展。
CPU+GPU成为AI异构计算主要方式
大模型时代,构建和调优生成式AI基础模型以满足应用需求,将为整个基础设施市场带来改变和发展机遇。 “以应用为导向、系统为核心”,将是未来算力升级的主要路径。
从技术发展视角来看,异构计算仍然是芯片发展趋势之一。在单一系统中,异构计算通过利用不同类型的处理器(如CPU、GPU、ASIC、FPGA、NPU等)协同工作,执行特定任务,以优化性能和效率,更高效地利用不同类型的计算资源,满足不同的计算需求。比如,通过发挥GPU并行处理能力,可以提高模型,尤其是大模型的训练速度和效率;在数据预处理、模型调优等阶段,可以使用CPU进行计算和决策,或在控制和协调计算资源(如GPU、FPGA等) 的工作过程中使用CPU,以确保计算过程的顺利进行;此外,可通过使用FPGA进行推理加速,从而将模型实现在边缘设备的部署,以开展更快速的实时推理工作。
IDC调查研究显示,截至2023年10月,中国市场普遍认为“CPU+GPU”的异构方式是AI异构计算的主要组合形式。
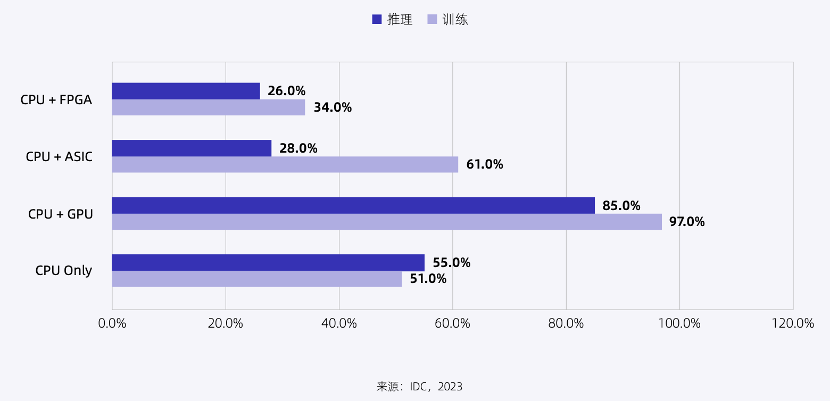
图:人工智能训练和推理工作负载选用的计算架构
(来源:《2023-2024年中国人工智能计算力发展评估报告》)
大模型时代,AI芯片三大挑战
AI算力需求的提升给中国本土芯片厂商的发展提供了较大的空间,带来新的机遇。IDC预计,2023年中国人工智能芯片出货量将达到133.5万片,同比增长 22.5%。
在面临广阔机会的同时,大模型时代,我国AI芯片也面临着新的发展挑战。首先,与国际领先AI芯片差距较大,以英伟达最新发布的H200 GPU为例,性能已经达到其A100 GPU近5倍。而我国AI芯片的大模型集群训练性能,只有个别接近A100/A800,大多数不到其性能的50%,这也意味着,我国AI芯片在大模型训练性能方面,与国际领先水平约是3年的代际差距。
其次,生态方面,英伟达的CUDA经过17年、累计超过100亿美元的资金投入,全球开发者已经超过300万,成为全球AI开发处于垄断地位的基础库。反观国内AI芯片企业,整体市场占有率加起来不超过10%,且各家AI芯片软件各异、生态零碎割裂。
此外,在当前时代背景下,我国AI芯片产能受阻、向高端芯片进阶关键技术受限等,也在一定程度上制约了AI芯片的发展。
破解异构算力三重难题
基于当前现状,北京智源人工智能研究院副院长兼总工程师林咏华提出,大模型时代,我国异构算力主要面临三重束缚。
异构算力束缚一:不一样的算力,不能合池训练
具体而言,当前异构混合分布式训练存在如下挑战:不同架构设备的软硬件栈不兼容,数值精度也可能存在差异;不同架构设备之间很难高效通信;不同设备算力和内存不同,很难进行负载均衡切分。
这些挑战很难一次性解决,目前智源已经尝试在相同架构不同代际设备或者在兼容架构的不同设备上进行异构训练,未来将探索不同架构设备上的异构训练。FlagScale是一个支持多厂商异构算力合池训练的框架,当前实现了异构流水线并行及异构数据并行两种模式。
- 异构流水线并行:在该模式实际训练时,可以跟数据并行、张量并行以及序列并行进行混合来实现高效训练。根据反向传播算法内存使用特点,该模式适合将内存比较大的设备放在流水线并行靠前的阶段,内存小的设备放在流水线并行靠后的阶段,然后根据再设备的算力来分配不同的网络层来实现负载均衡。
- 异构数据并行模式:在该模式实际训练时,可以跟张量并行、流水线并行以及序列并行进行混合来实现大规模高效训练。算力和内存都比较大的设备将处理较大的微批次大小,而算力和内存都比较小的设备将处理较小的微批次大小,从而实现不同设备上的负载均衡。
根据智源所展示的在英伟达和天数智芯集群的三组异构混合训练实验结果,显示异构混合训练收益较好,在三种配置情况下接近甚至超过了性能上限,这说明异构混合训练的效率损耗较低,获得了较好的训练收益。

林咏华介绍,异构算力合池训练框架FlagScale正在实现英伟达算力集群与天数智芯算力集群的异构合池训练,未来将实现更多不同中国厂商算力集群之间的异构合池训练,推动不同厂商异构芯片的通信库标准化,实现高速互通互联。
她表示,在芯片的迭代更新过程中,肯定存在新、旧代际芯片混用的过程,希望继续攻关兼容异构芯片的混合训练技术,也希望在同一个数据中心,各种商业资源可以灵活组合,将性能和效率最大化。
异构算力束缚二:受CUDA制约,算子库在不同硬件上适配难度大
当前,我国AI芯片软件生态薄弱,主流AI框架以支持英伟达芯片为主。对于国产AI芯片来说,需要适配多款框架,每次AI框架版本升级,需要重复适配;同时,各AI芯片厂商有自己的底层软件栈,彼此不兼容。
在大模型需求下,上述问题带来三大影响:第一,针对大模型需要的算子及优化方法缺失,导致模型无法运行或者运行效率低;第二,会出现因为芯片架构和配套的软件实现差异而带来的精度误差问题;第三,要在国产AI芯片上实现大模型训练,需要大量移植工作,适配迁移成本很高。
对此,林咏华认为,构建公共的AI芯片开放软件生态非常关键,结合大模型研究和发展需求,基础架构层面要构建基于下一代开放、中立的AI编译器中间层,并且要适配PyTorch框架,支持开源编程语言及编译器扩展。下一步,要继续探索最大化硬件基础架构性能和利用率的共性核心技术,对典型和复杂算子的软硬件协同极限优化,使得成果开源开放,高效支撑大模型训练。
异构算力束缚三:芯片架构、软件各异,评测难度大,影响落地进展
当前,AI芯片企业众多,各自架构和开发工具链不同,且AI框架众多,再加上层出不穷的场景和复杂多变的模型,导致适配工作量大、开发复杂度高、评测标准难统一,影响了产品的落地和规模化应用。
林咏华认为,AI异构芯片的评测,对行业生态有重要价值。当前,业界缺少被广泛认可的、中立的、开源开放的、针对异构芯片的评测体系。应该建立开源的AI芯片评测项目,具体包括基础环境、异构芯片基础软件、测试集等,对模型运行的支持情况、芯片的训练时间和计算吞吐量、芯片和服务器其他零部件的使用情况、芯片对不同框架和软件生态的支持能力等方面,进行全方位评测。
写在最后
AI大模型的发展提升了智能算力的需求。IDC数据显示,2022-2027年,我国智能算力规模年复合增长率达33.9%,超越同期通用算力规模16.6%的年复合增长率。
本土AI芯片厂商正面临着新的机遇和挑战。针对单芯片算力的瓶颈问题、多芯片异构合池训练难题,以全局思维打造算力基础设施平台成为未来的关键。特别是在构建与硬件匹配的软件生态,包括操作系统、中间件和工具链等方面,随着大模型从基础研发走向应用落地,软件基础设施的重要性和价值将会进一步凸显。 这也是大模型在完成了“从0到1”的预训练之后,在通往“从1到100”的应用和大规模落地过程中,AI芯片作为核心基础环节必须完成的修炼,也将给中国AI芯片产业带来深远的影响。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1645668.html

 下载ECAD模型
下载ECAD模型
