


 2953
2953
fpga学徒一枚,会持续分享FPGA学习周报,也欢迎各位小伙伴指正
学习内容
1.面积优化
1.1面积优化:
就是在实现预定功能的情况下,使用更小的面积。通过优化,可以使设计能够运行在资源较少的平台上,节约成本,也可以为其他设计提供面积资源。
1.2逻辑优化
使用优化后的逻辑进行设计,可以明显减少资源的占用
1.3卷起流水管道
卷起流水管道与展开循环来提高吞吐量以实现最大性能的操作相反。当需要展开循环来创建管道时,我们需要更多的资源来保存中间值和负值需要并行运算的计算结构,从而增加了面积。相反,当我们想要最小化设计的面积时,我们必要反过来执行这些操作,卷起流水管道可以重用逻辑资源。
1.4基于控制的逻辑重用
共享逻辑资源通常需要特殊的控制电路来确定哪些元素被输入到特定的结构中。在上一节中,我们描述了一个乘法器,它只是移动每个寄存器的位,其中每个寄存器总是专用于正在运行的加法器的特定输入。这有一个自然的数据流,可以很好地进行逻辑重用。在其他应用程序中,资源的输入通常有更复杂的变化,并且可能需要某些控制来重用逻辑。
2.速度优化
2.1速度有三种基本定义:
2.1.1流量(吞吐量): 定义为每个时钟周期处理的数据量。流量的通常度量是每秒的位数。(b/s)
2.1.2时滞: 定义为数据输入与处理的数据输出之间的时间。时滞的一般度量是时间或时钟周期。
2.1.3时序:是指顺序元件之间的逻辑延迟。当我们说设计不“满足时序”时,我们的意思是关键路径的延迟,即触发器之间的最大延迟(由组合延迟、时钟到输出延迟、路由延迟、设置时序、时钟偏差等组成)大于目标时钟周期。时序的标准度量是时钟周期和频率。
2.2高吞吐量
高吞吐量设计关注的是稳定的数据速率,但不太关注任何特定数据块在设计中传播所需的时间(延迟)。
高吞吐量设计的想法和福特大批量生产汽车的想法是一样的:一条装配线。在处理数据的数字设计领域,我们用一个更抽象的术语来指代它:管道(流水线)。
流水线设计在概念上非常类似于装配线,因为原材料或数据输入进入前端,经过各种操作和处理阶段,然后作为成品或数据输出退出。流水线设计的美妙之处在于,新数据可以在之前的数据完成之前开始处理,就像汽车在装配线上被处理一样。管道几乎用于所有非常高性能的设备,并且各种特定架构是无限的。
2.3低延时
低延迟设计是通过最小化中间处理延迟,尽可能快地将数据从输入传递到输出,但可能会降低设计中的吞吐量或最大时钟速度。
2.4时序
时序是指设计的时钟速度。设计中任意两个元件之间的最大延迟将决定最大时钟速度。时序越好,表示可以运行更大的时钟频率。
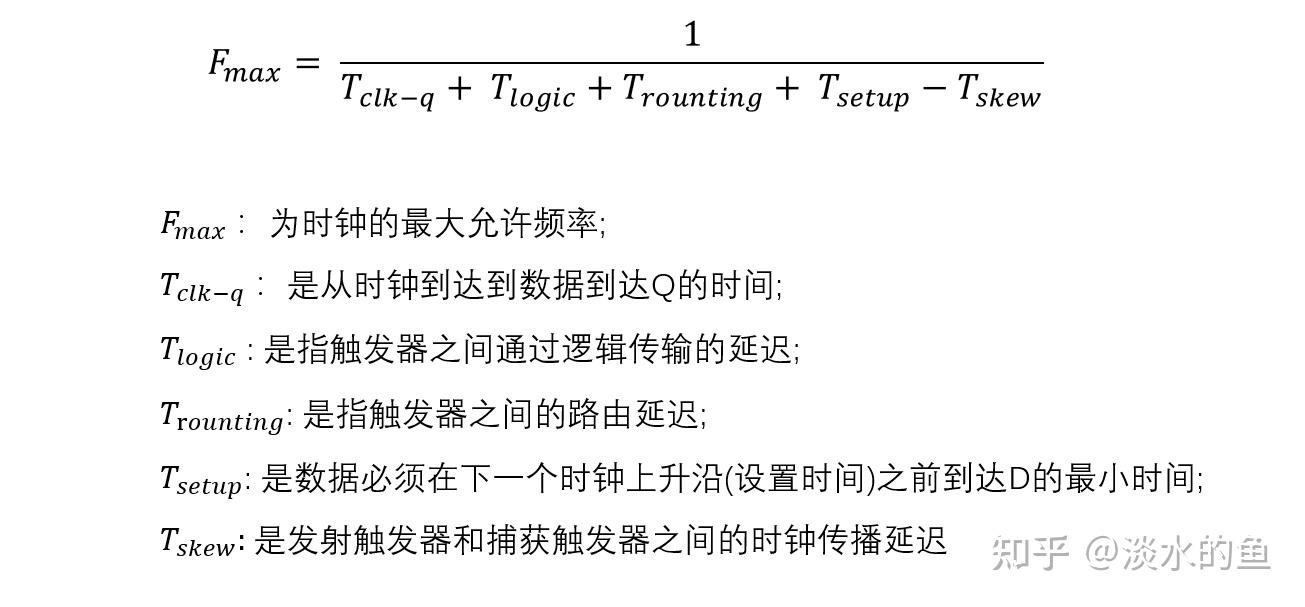
2.5改善时序1:添加寄存器层级
时序改进的第一个策略是向关键路径添加寄存器的中间层。这种技术应该用于高度流水线化的设计中,其中额外的时钟周期延迟不会违反设计规范,并且整体功能不会受到进一步添加寄存器的影响。
2.6改善时序2:并行架构
时序改进的第二个策略是重新组织关键路径,以便并行实现逻辑结构。只要串行逻辑求值的函数可以分解 成并行求值,就应该使用这种技术。
2.7改善时序3:展平逻辑结构
时序改进的第三个策略是展平逻辑结构。这与前面定义的并行结构的概念密切相关,但特别适用于优先级编码的逻辑。通常情况下,合成和布局工具足够聪明,可以复制逻辑以减少扇出,但它们无法分解以串行方式编码的逻辑结构。
2.8改善时序4:寄存器平衡
第四种策略称为寄存器平衡。从概念上讲,其思想是在寄存器之间均匀地重新分配逻辑,以最小化任意两个寄存器之间的最坏情况延迟。只要关键路径和相邻路径之间的逻辑高度不平衡,就应该使用这种技术。由于时钟速度仅受最坏情况路径的限制,因此可能只需要一个小的更改就可以成功地重新平衡关键逻辑。
2.9改善时序5:重新排序的路径
第五种策略是重新排序数据流中的路径,以最小化关键路径。每当多个路径与关键路径组合时,都应该使用此技术,并且可以对组合路径进行重新排序,以便将关键路径移动到更靠近目标寄存器的位置。使用这种策略,我们将只关心任意给定寄存器集之间的逻辑路径。
2.10总结
- 高吞吐量架构是指一种设计可以最大限度地提高每秒可以处理的比特数。
- 展开迭代循环可以增加吞吐量。
- 展开迭代循环的代价是面积成比例地增加。
- 低延迟架构是将模块输入到输出的延迟最小化的架构。
- 可以通过移除管道寄存器来减少延迟。
- 删除管道寄存器的代价是增加了寄存器之间的组合延迟,时序变差。
- 时序是指设计的时钟速度。
- 当任意两个顺序元件之间的最大延迟小于最小时钟周期时,设计满足时序要求。
- 增加寄存器层通过将关键路径划分为两个延迟较小的路径来改善时序。
- 将一个逻辑函数分成若干个可以并行计算的较小函数,可以减少到子结构中最长的路径延迟。
- 通过删除不需要的优先级编码,逻辑结构变得扁平,并且减少了路径延迟。
- 寄存器平衡通过将组合逻辑从关键路径移动到相邻路径来改善时序。
- 可以通过重新排序与关键路径组合的路径来改进时序,以便将一些关键路径逻辑放置在更靠近目标寄存器的地方
3.功耗优化与其他优化
3.1时钟控制
降低同步数字电路动态功耗的最有效、应用最广泛的技术是在数据流的特定阶段动态禁用不需要激活的特定区域的时钟。由于FPGA中的大多数动态功耗与系统时钟的切换直接相关,因此在设计的非活动区域暂时停止时钟是最小化此类功耗的最直接方法。推荐的实现方法是使用触发器上的时钟使能引脚或使用全局时钟多路复用器(在Xilinx设备中,这是BUFGMUX元件)。
3.2时钟偏斜
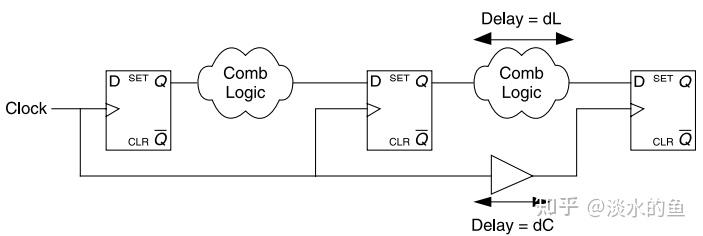
如果通过逻辑延迟(dL)小于时钟线延迟(dC) ,则可能发生第二个触发器传播的信号将在时钟采样之前到达第三级的情况。当时钟采样沿到达时,数据可能已经丢失,这种情况将导致电路的灾难性故障,因此在进行时序分析时必须考虑时钟偏差。同样重要的是要注意,时钟倾斜与时钟速度无关。
3.3约束偏斜
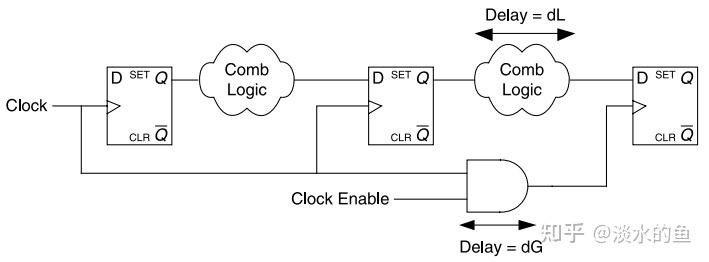
3.4控制输入
3.4.1浮动输入:是欠驱动输入,无法知道它的欠驱动程度,输入信号未确定或处于高阻态的情况,这将对功耗产生灾难性的影响。更糟糕的是,这不会是一个可重复出现的问题。永远不要让FPGA输入缓冲区浮动。
3.4.2浮动输入可能导致以下问题:
功耗增加:由于晶体管进入饱和区并耗散少量电流,浮动输入信号可能导致不必要的功耗增加。
电路不稳定性:浮动输入可能导致电路的不稳定性,因为输入信号的电平无法确定,可能会引入噪声和干扰,影响电路的正确功能。
3.4.3在Verilog中,可以通过以下几种方法来避免出现浮动输入:
初始化输入信号:在设计中,为每个输入信号提供一个默认的初始值。这样,在系统启动或信号未被显式赋值时,输入信号将具有一个确定的初始值,而不是浮动的状态。
使用三态逻辑:如果某个信号需要在多个模块之间进行共享,并且可能有多个驱动器,可以使用三态逻辑来避免浮动输入。三态逻辑使用一个控制信号来控制信号的驱动器是否处于高阻态(浮动状态)。
避免未使用的信号:在设计中,尽量避免定义未使用的信号。未使用的信号可能会导致未初始化或浮动的状态。
使用合适的时序约束:时序约束对于确保信号的稳定性非常重要。通过正确设置时序约束,可以确保信号在时钟边沿到达之前具有足够的时间来稳定,从而避免浮动输入。
3.5总结
- 时钟使能触发器输入或全局时钟多路选择器等时钟控制资源应该在其有效的场合代替直接时钟选通来利用。
- 时钟选通是减少动态功耗直接手段,但是在实现和时序分析中产生困难。
- 对 FPGA设计者,选通时钟引入新的时钟区域,并将产生困难。
- 在 FPGA 中管理不好时钟偏移可能引起突发的故障。
- 时钟选通会引起保持的冲突,可能不被实现工具校正。
- 避免出现输入浮动。
- 动态功耗随着电压的平方减弱,但是降低电压对性能有负面的影响。
- 双沿触发的触发器应该只在他们被提供作为基本元件时才利用。
- 使用更简单或更高效的逻辑表达式、减少信号的扇出、使用更小或更快的逻辑单元、减少互连长度和拥塞等方法来降低功耗。
4.ddr3
4.1 DDR3概述
DDR3全称double-data-rate 3 synchronous dynamic RAM,即第三代双倍速率同步动态随机存储器。 所谓同步,是指DDR3数据的读取写入是按时钟同步的;所谓动态,是指DDR3中的数据掉电无法保存,且需要周期性的刷新,才能保持数据;所谓随机存取,即可以随机操作任一地址的数据;所谓double-data-rate,即时钟的上升沿和下降沿都发生数据传输。
4.2 DDR3功能框图
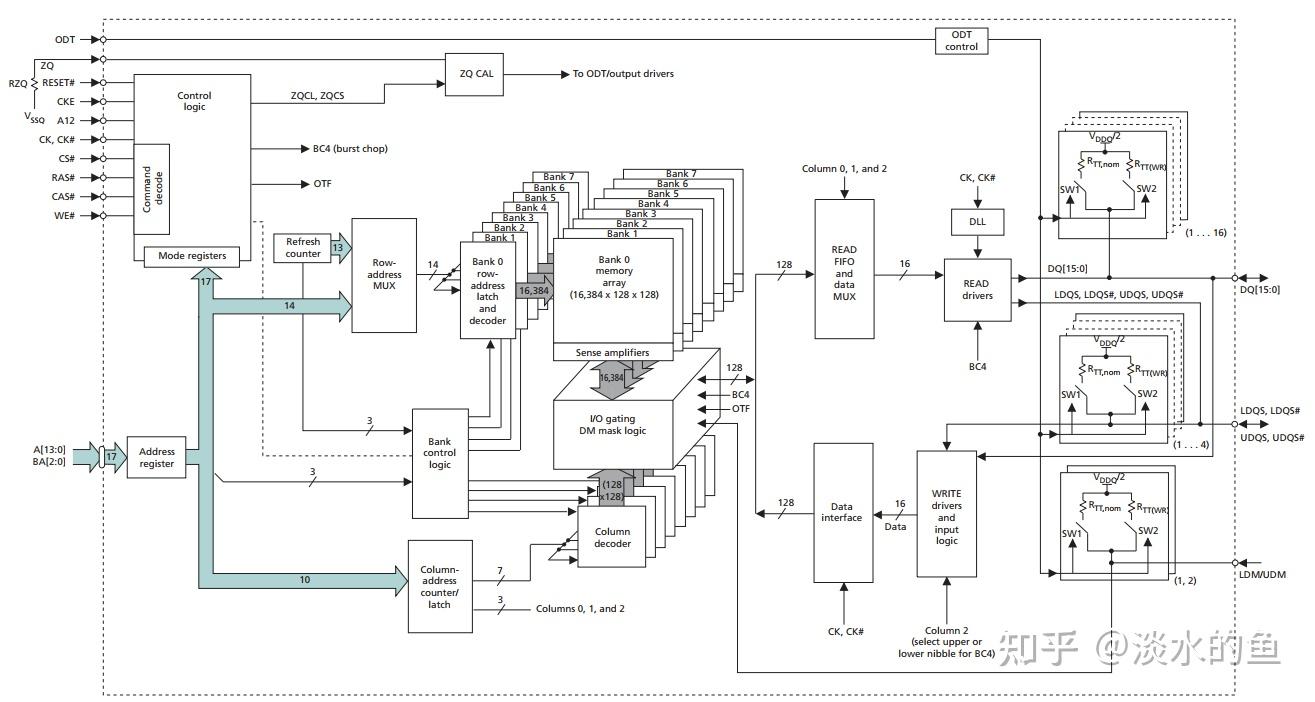
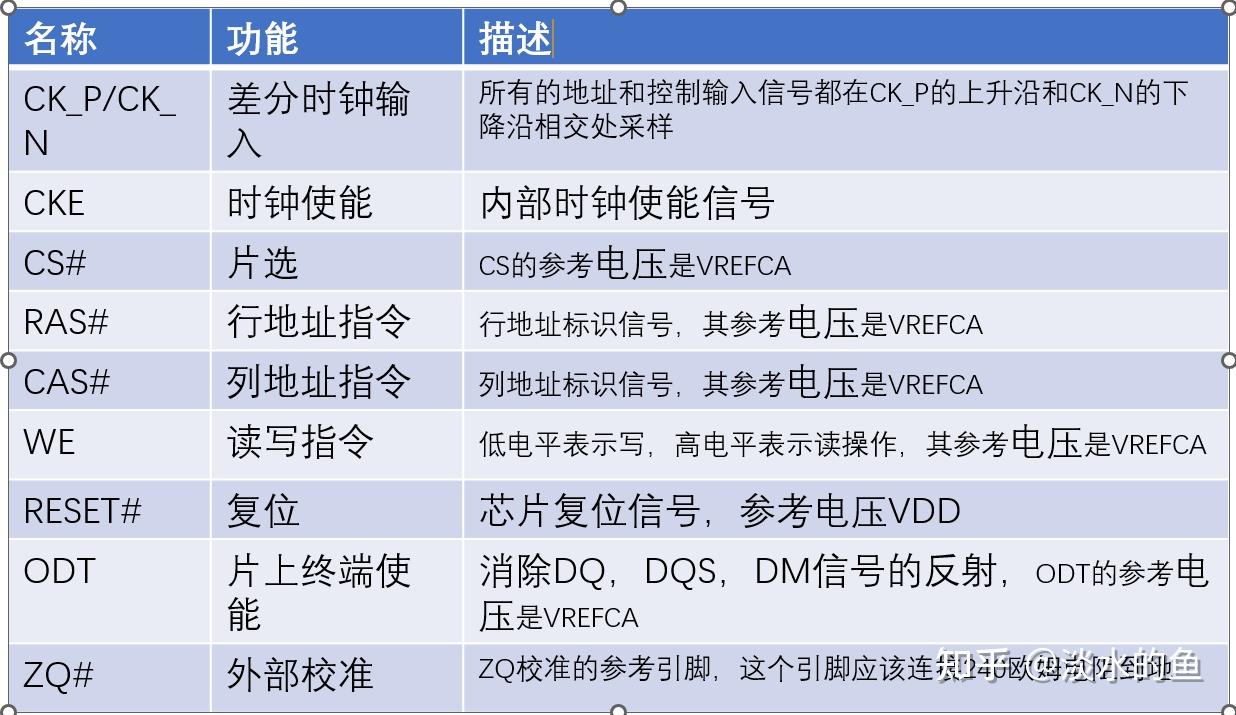


4.3时钟频率与带宽
core freq: 核心频率,用于DDR内部cell(存储单元)的时钟;
clock freq:时钟频率,用于DDR的IO buffer的时钟,同时也是IO接口时钟,是通过核心频率倍频(4)倍得到的;
data rate: 数据速率,单根数据线的数据传送次数;
bandwidth:芯片带宽,数据速率*芯片的数据位宽;
4.4突发长度(Burst Length,BL)
由于DDR3的预取为8bit,所以突发传输周期(Burst Length,BL)也固定为8,而对于DDR2和早期的DDR架构系统,BL=4也是常用的,DDR3为此增加了一个4bit Burst Chop(突发突变)模式,届时可通过地址线A12来控制这一突发模式。
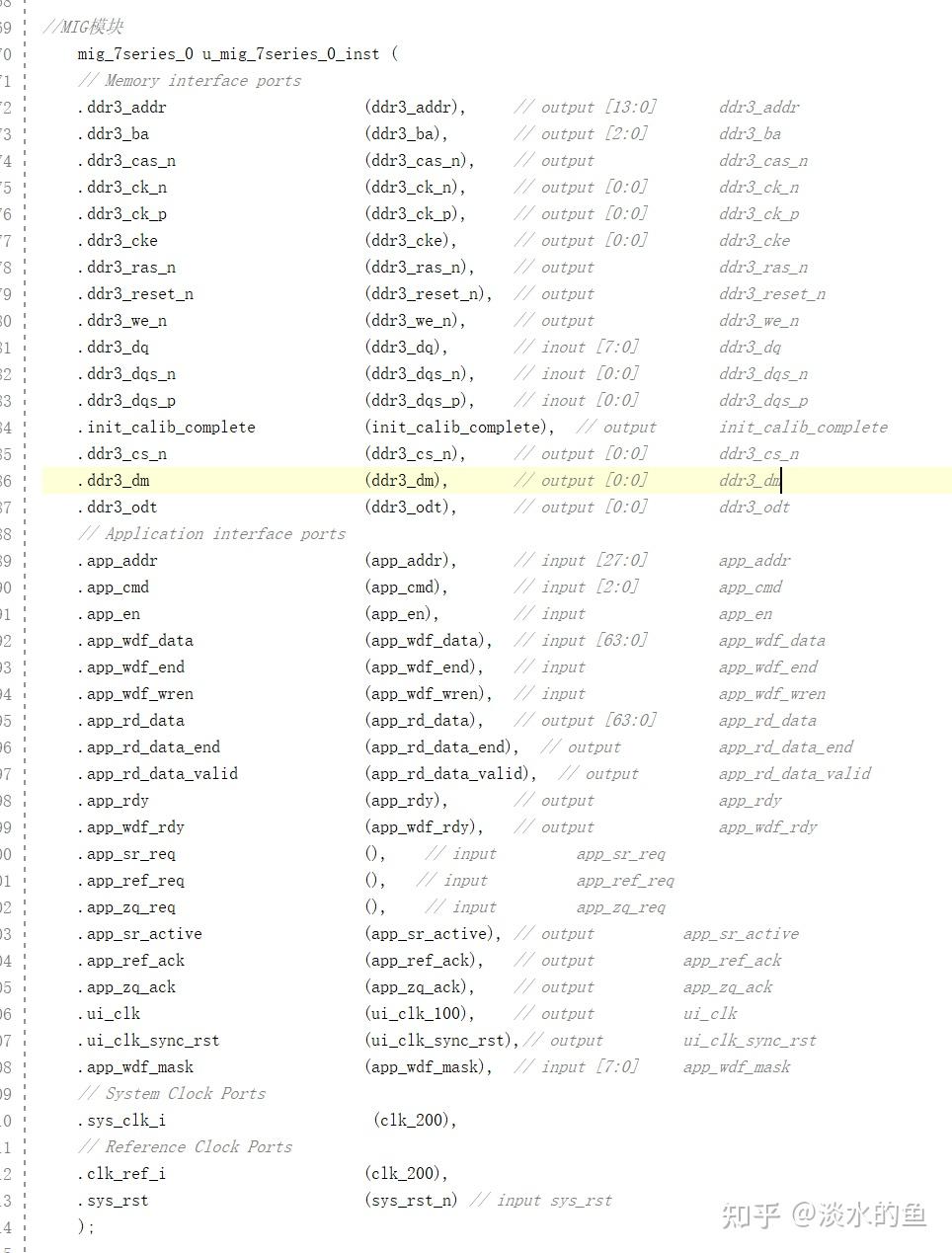
4.5 MIG IP 核结构框图
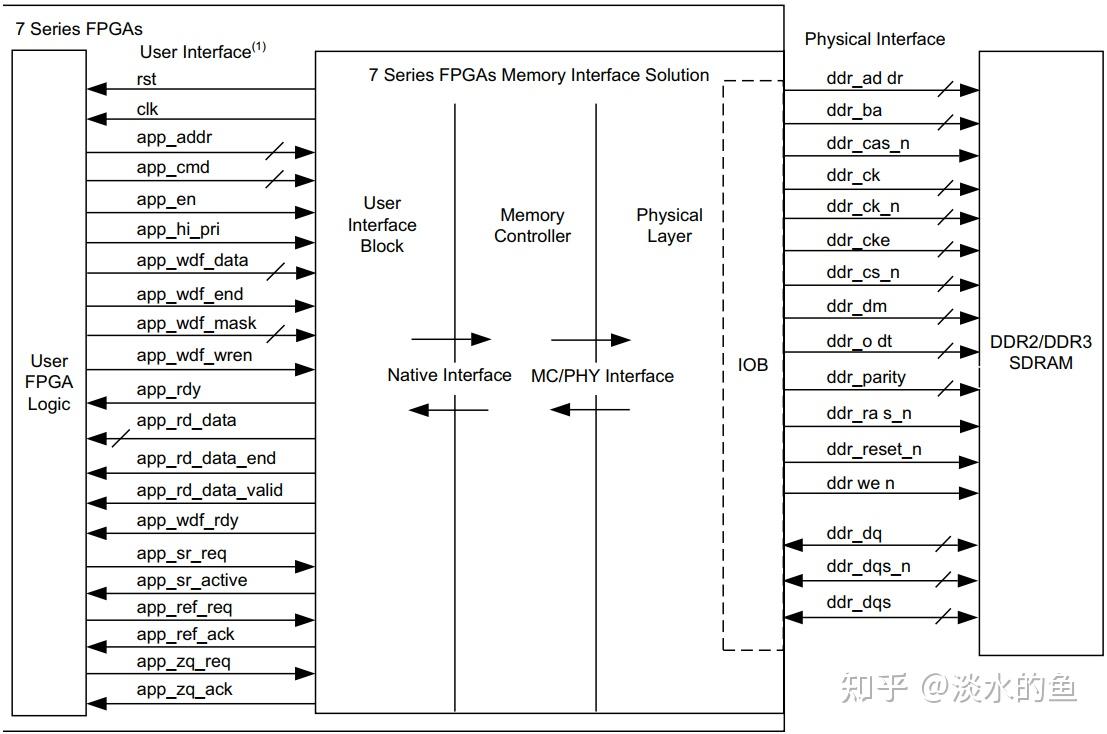
4.6 MIG IP 核信号定义
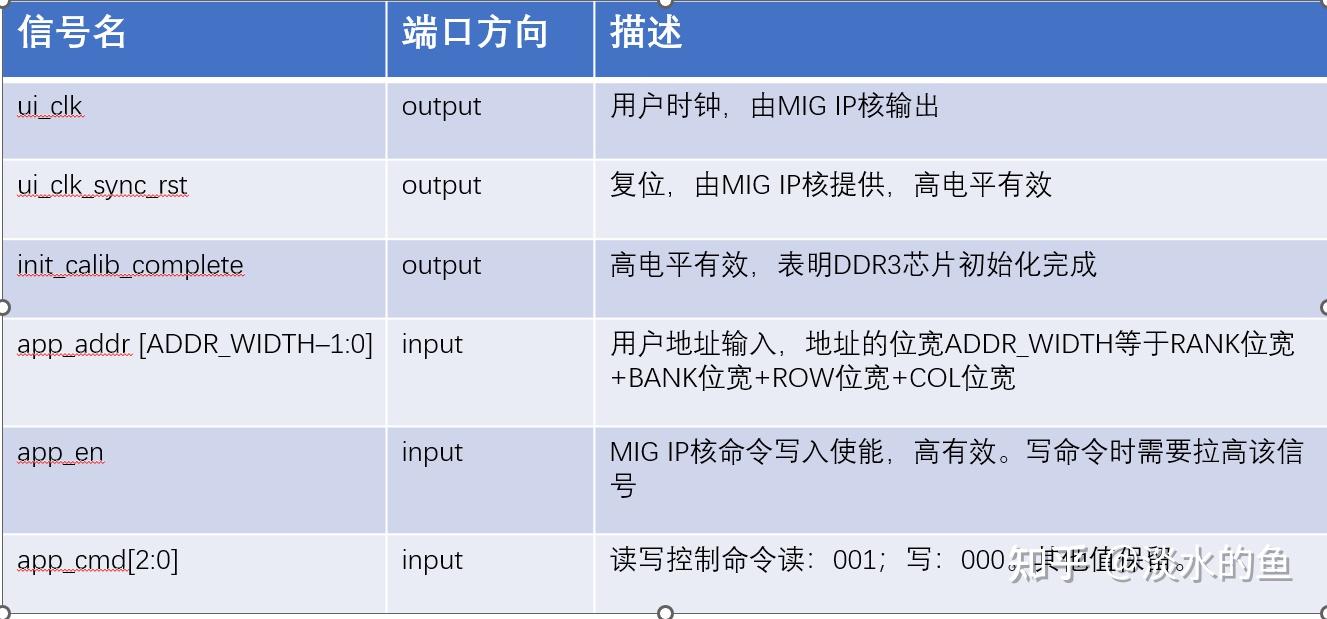
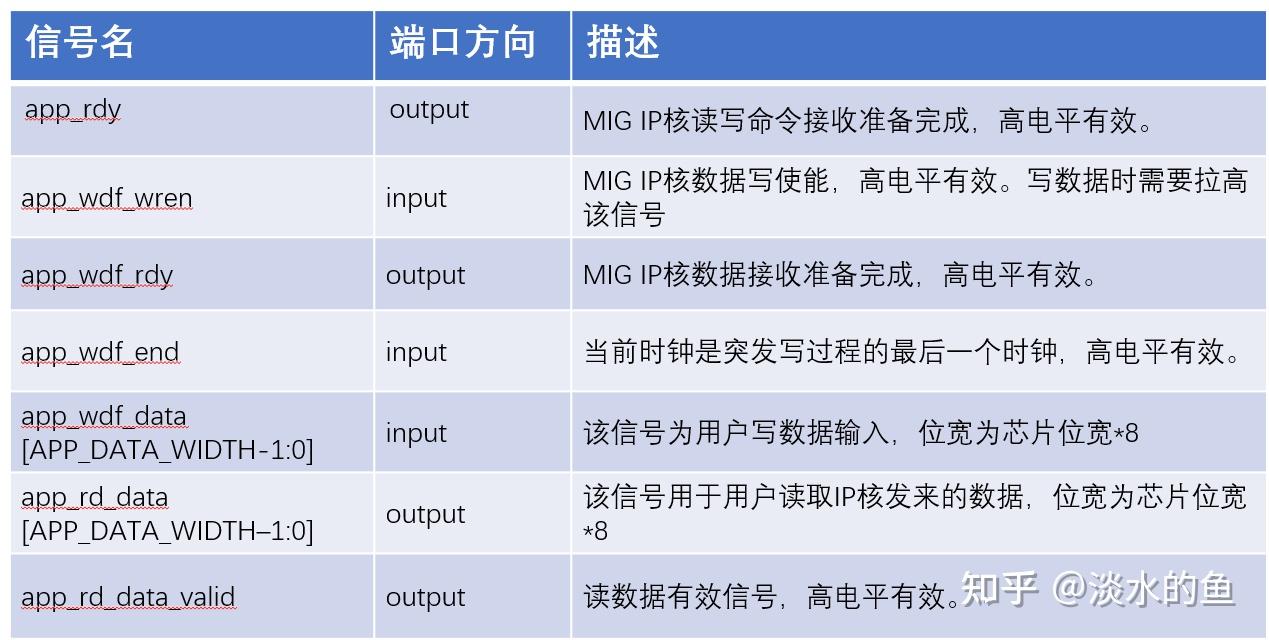
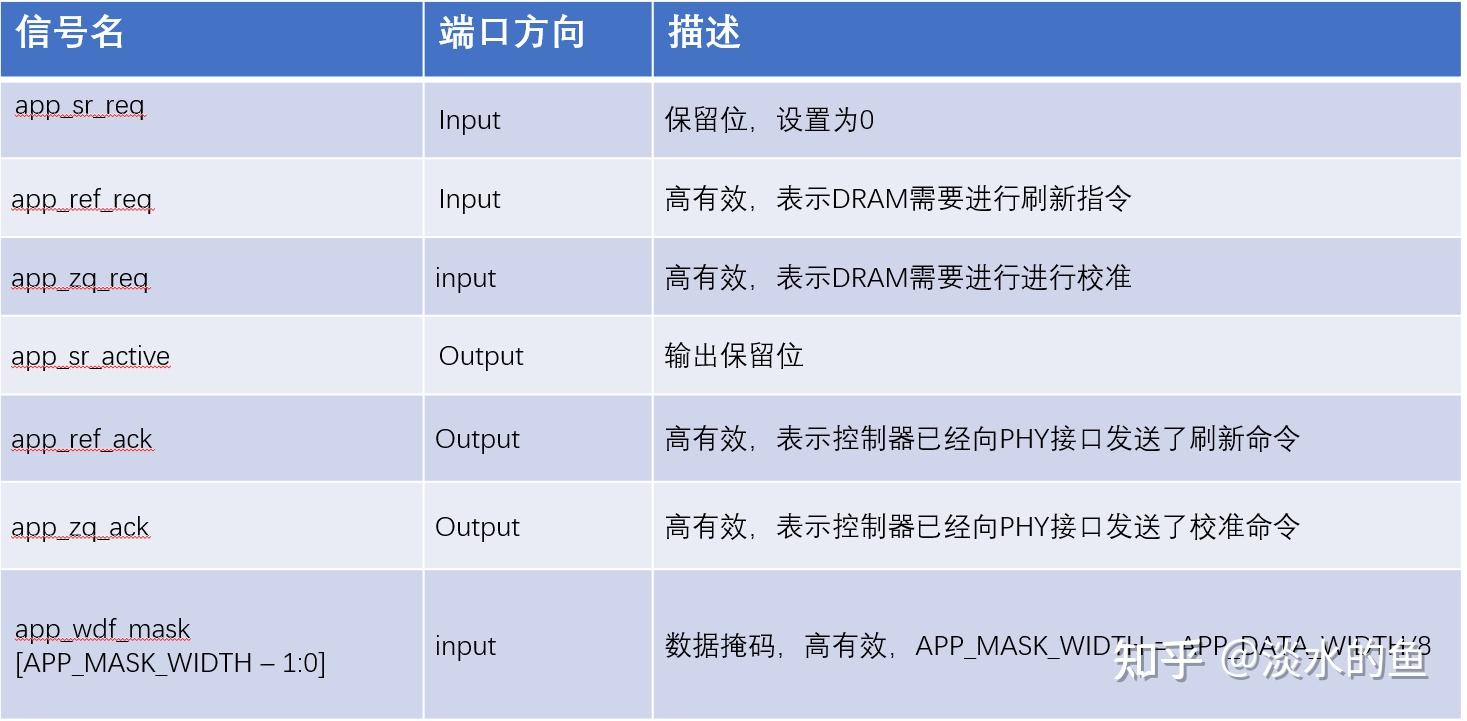
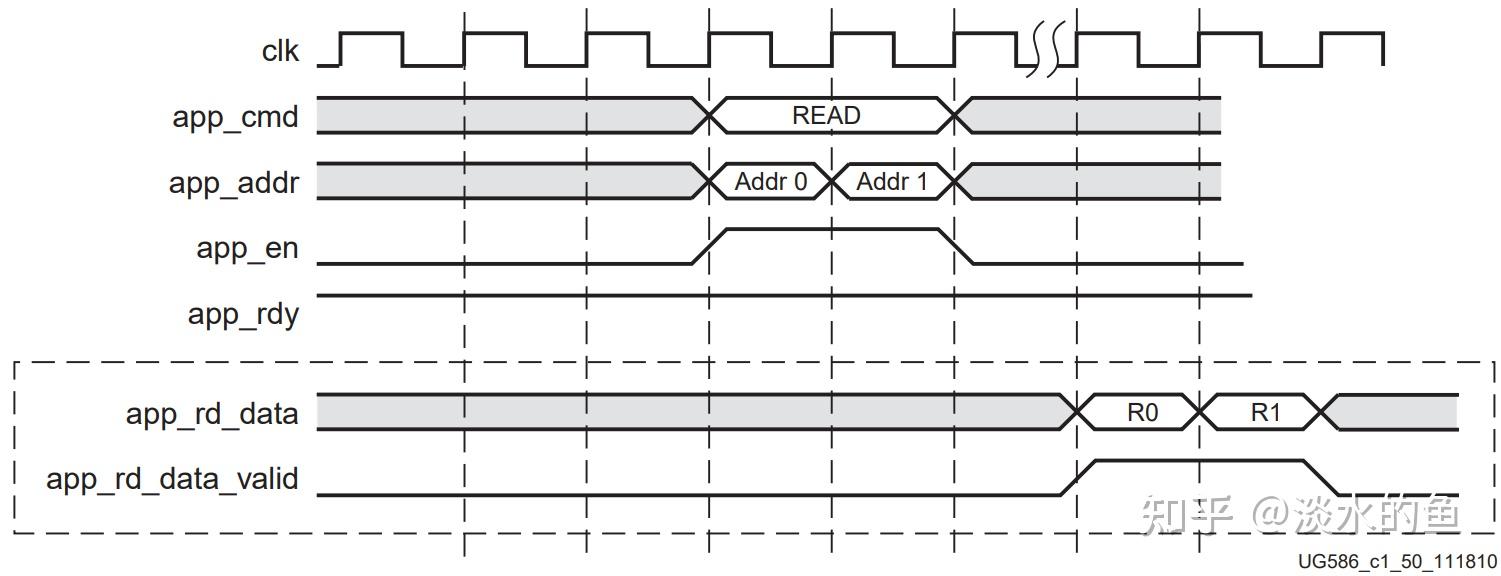
4.7写命令时序
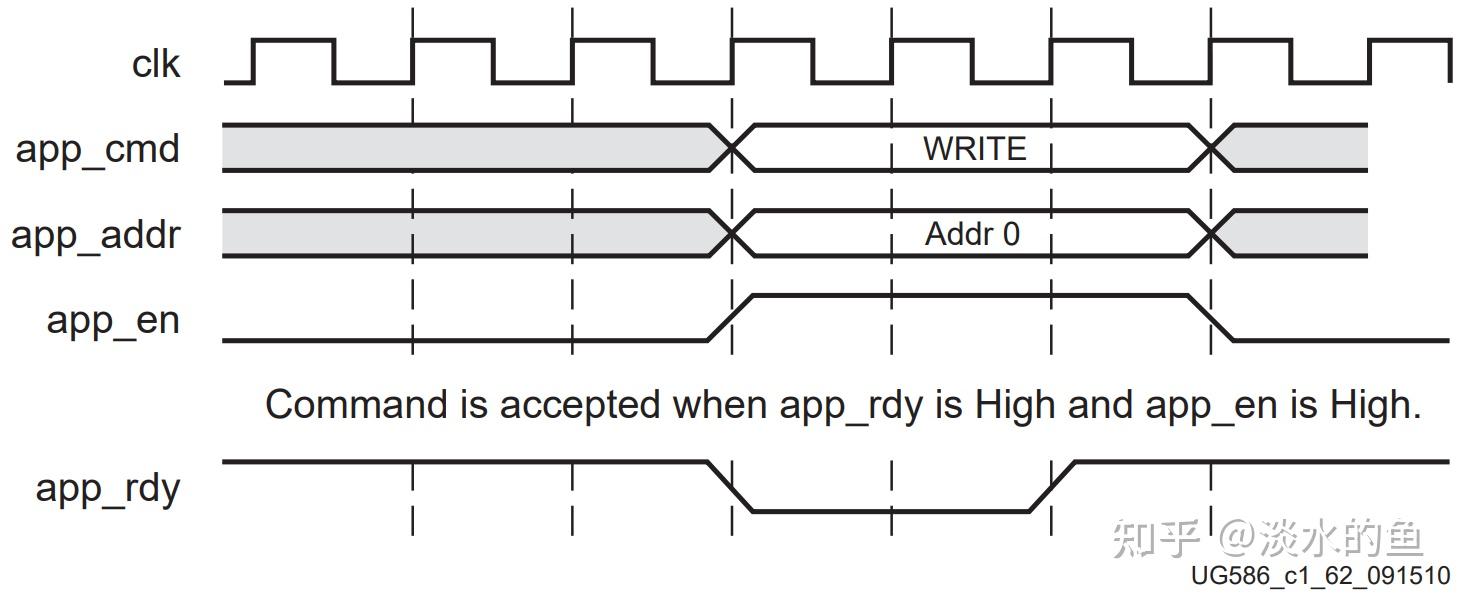
单次读写一个地址的数据
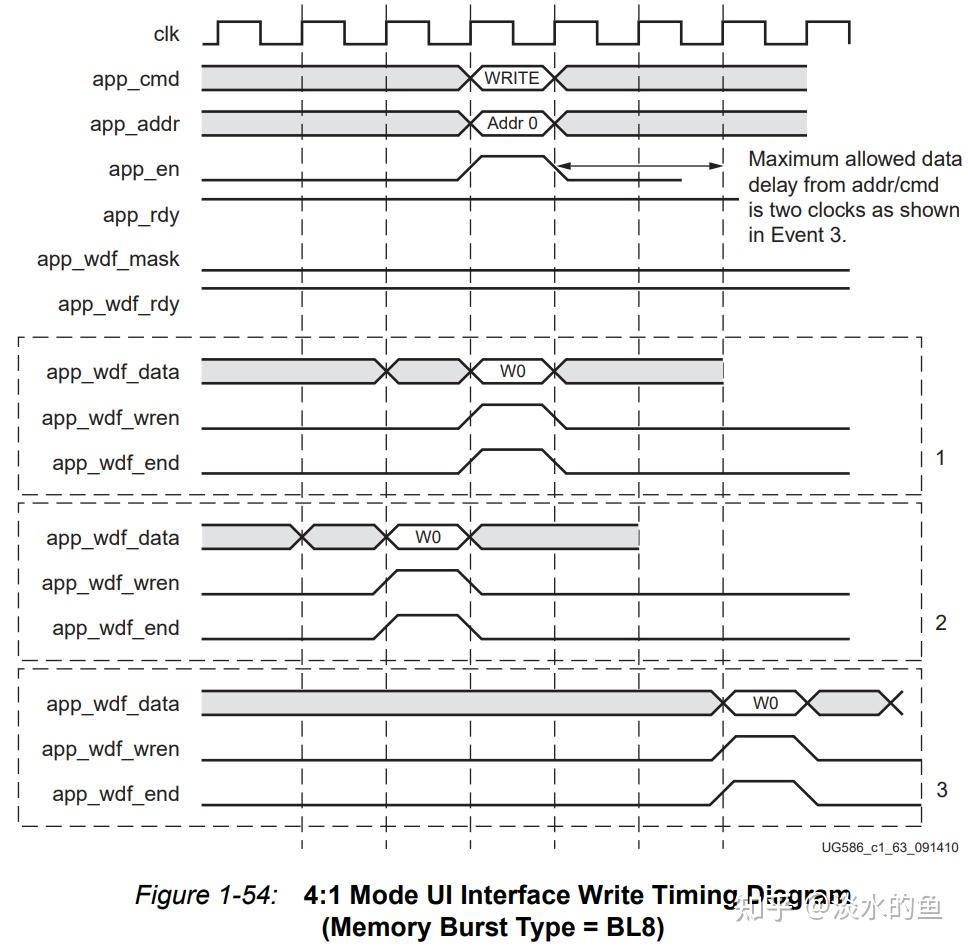
4.8背靠背写数据时序
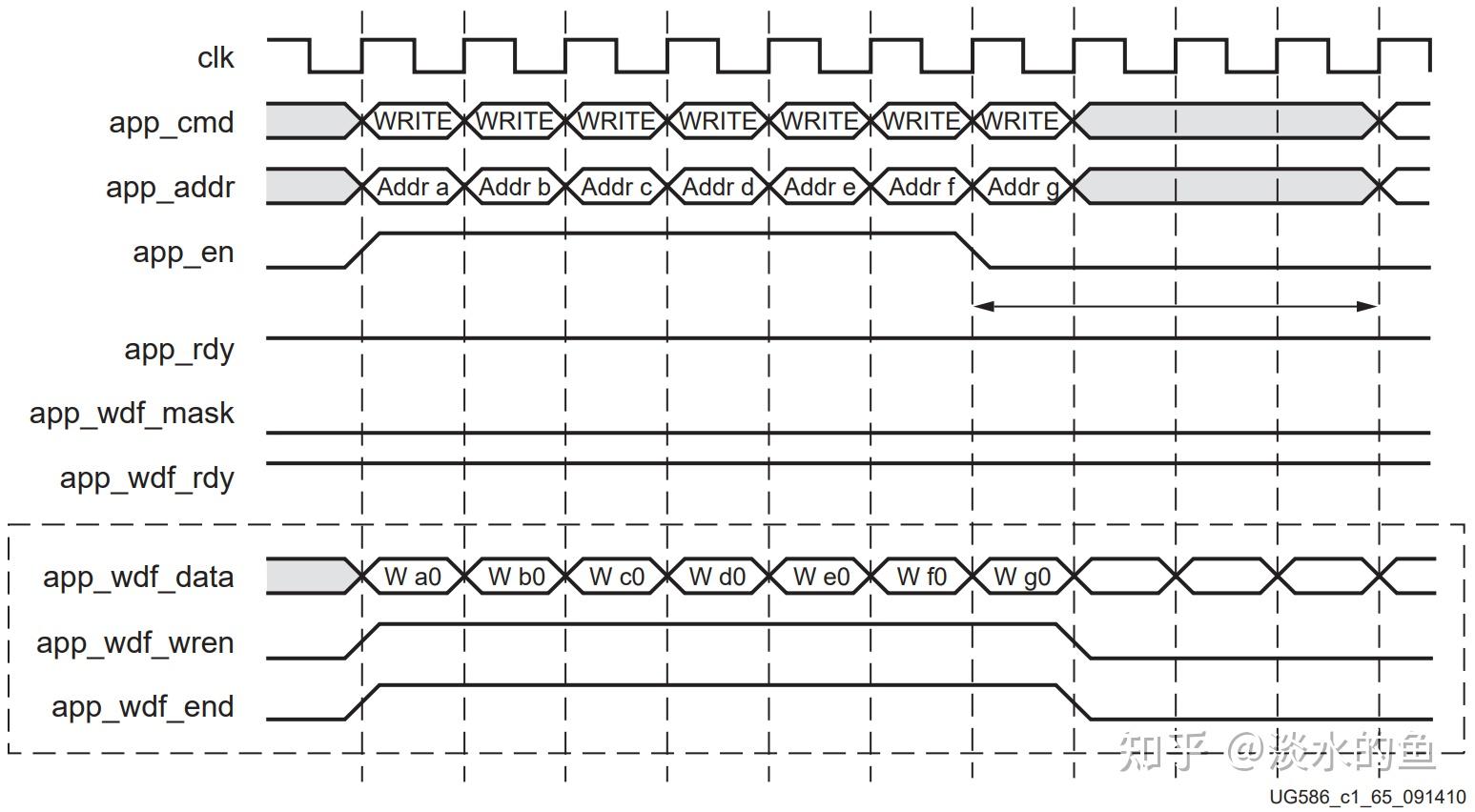
非背靠背读数据时序
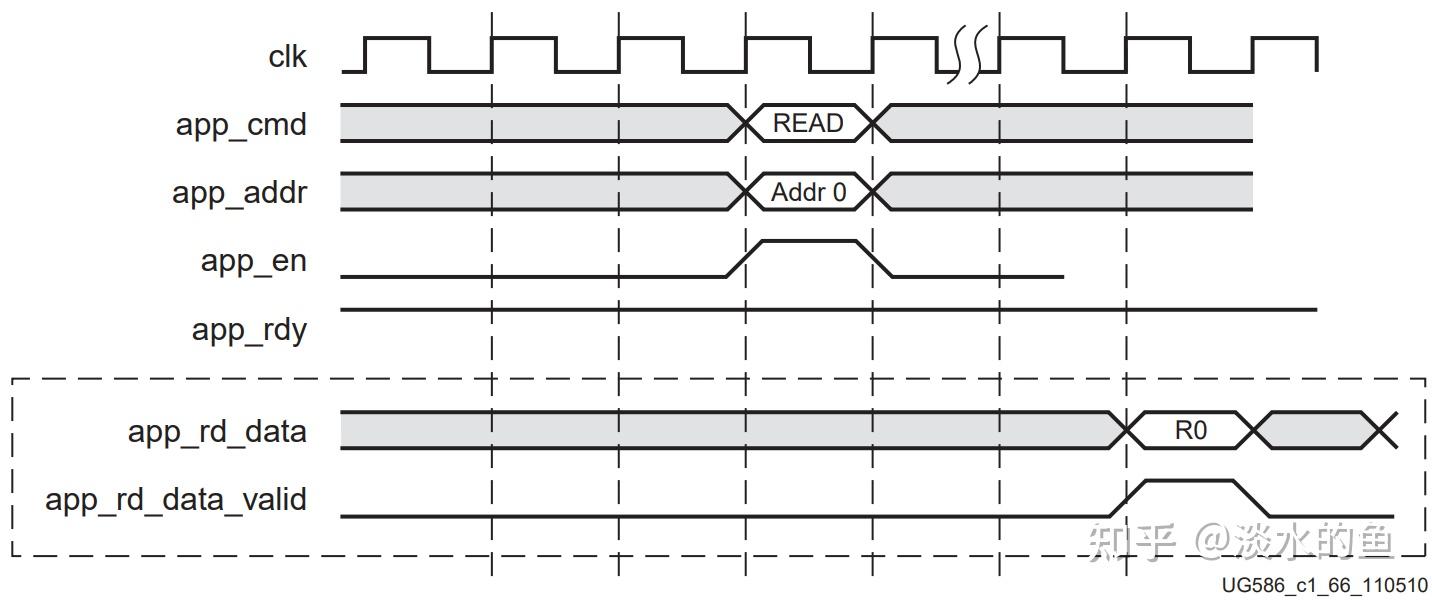
背靠背读数据时序
4.9时钟
系统时钟:MIG IP 核工作时钟,一般命名为 sys_clk。
参考时钟:MIG IP 的参考时钟,必须为 200M,命名为 ref_clk DDR3 芯片工作的时钟:由 FPGA 输入到 DDR3 芯片,为差分时钟
用户端时钟:MIG IP 核输出给用户端的时钟,命名为 ui_clk
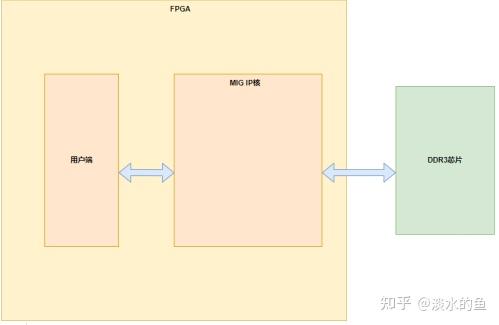
4.10带宽计算
①FPGA 写入数据到 DDR3 芯片的带宽为: 800M × 2 × 16bit
②用户端写入数据到 MIG IP 核的带宽为:200M ×用户端数据位宽,因为 800M × 2 × 16bit = 200M ×用户端数据位宽,所以用户端数据位宽为 128bit
4.11系统时钟 system clock 关于 No Buffer、Single-Ended、Differential 怎么 选择?
系统时钟由内部时钟产生,比如经过 PLL 后产生的 200M 时钟,选择 No buffer。 系统时钟由 FPGA 外部晶振产生,输入到 FPGA 的管脚,再输入到 MIG IP 核,选择 Single-Ended 或者 Differential。外部晶振产生的时钟为单端时钟,选择 Single-Ended;外部晶振产生的时钟为差分时钟,选择 Differential; No Buffer 是什么意思? No Buffer 就是 MIG IP 核内部没有例化 IBUF 原语
二.课后练习
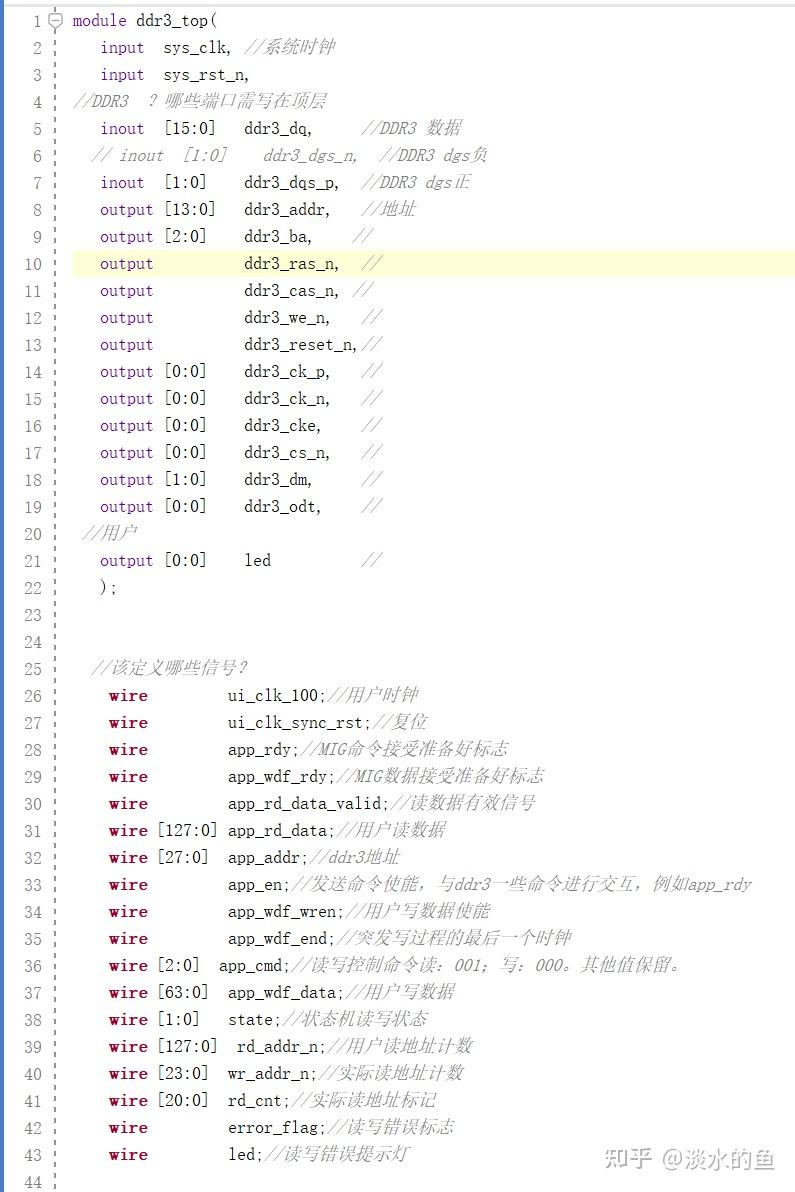
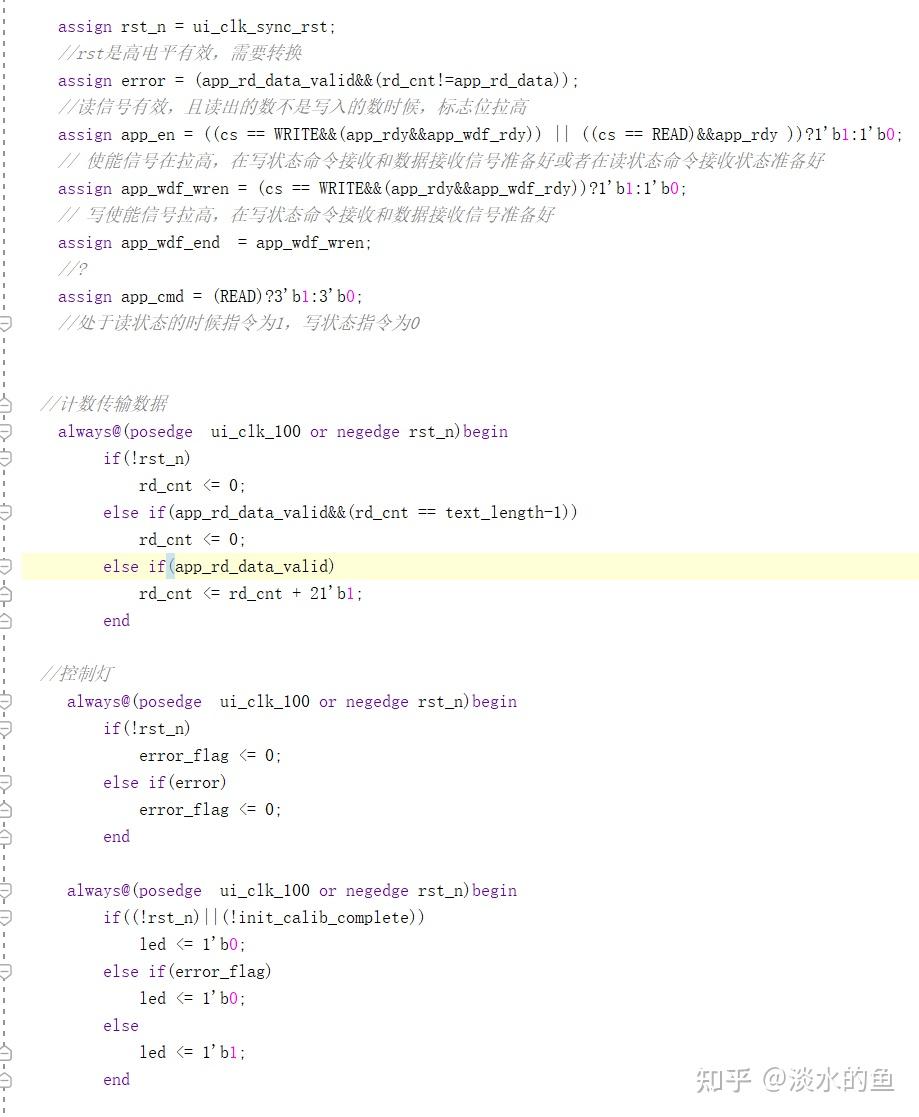
1.实验任务是先向DDR3的存储器中写入1024个数据,写完之后再从存储器中读取相同地址的数据,若初始化成功,则LED0常亮,否则LED0闪烁;读取的值全部正确则LED1灯常亮,否则LED1灯闪烁。





三.学习中遇到的问题
1.对基于控制的逻辑重用不熟悉.
2.对ddr3的结构功能及使用都不清晰,不能正确使用ddr3IP核。
3.对于BROM的数据传给BRAM不清楚具体模块。
四.学习中解决的问题
1.学习了解面积优化,速度优化,功耗优化。
2.了解ddr3的基本结构功能。



