


 943
943
作者:解码工作室
外界常有这样一种错觉,因为英特尔CPU卖的好就将其归于一家成功的硬件公司,而事实上,英特尔统治桌面处理器的功臣是诞生于1978年的X86架构。
同样的错觉在英伟达身上也有。
英伟达之所以能够垄断人工智能训练芯片市场,CUDA架构绝对是幕后功臣之一。
这个诞生于2006年的架构,已经涉及计算机计算的各个领域,几乎被塑造成了英伟达的形状。航空航天、生物科学研究、机械和流体模拟及能源探索等领域的研究,80%在CUDA的基础上进行。
而在最火爆的AI领域,几乎所有的大厂都在准备Plan B:谷歌、亚马逊、华为、微软、OpenAI、百度……谁也不想让自己的未来攥在别人手中。
创业服务咨询机构Dealroom.co公布过一组数据,在这波生成式AI的热浪中,美国获得了全球投融资的89%,而在AI芯片的投融资中,中国AI芯片投融资世界第一,超过美国两倍。
也就是说,尽管中美企业在大模型的发展方式和阶段都存在诸多差异,但在掌控算力这件事,大家却显得格外一致。
1 为什么CUDA有这种魔力?
2003年,英伟达为了与推出4核CPU的英特尔竞争,开始着手发展统一计算设备架构技术,也就是CUDA。
CUDA的初衷是为GPU增加一个易用的编程接口,让开发者无需学习复杂的着色语言或者图形处理原语。英伟达最初的想法是为游戏开发者提供一个图形计算领域的应用,也就是黄仁勋口中的"make graphics programmable"。
不过CUDA推出后一直找不到关键应用,也缺少重要客户支持。而且英伟达还要花费大笔金钱来开发应用、维持服务并推广与行销,到2008年遭遇金融风暴,显卡销售不好的英伟达营收大跌,股价一度跌到只剩1.5美元,比AMD最惨的时候还要惨。
直到2012年,Hinton的两个学生用英伟达的GPU参加了一个叫做ImageNet的图像识别速度比赛。他们使用GTX580显卡,利用CUDA技术进行训练,结果算出的速度超过第二名数十倍,精确度也比第二名高10%以上。
让业内震惊的不只是ImageNet模型本身。这个需要1400万张图片、总计262千万亿次浮点运算训练的神经网络,一个星期的训练过程中仅用了四颗GTX 580。作为参考,谷歌猫用了1000万张图片、16000颗CPU和1000台计算机。
这次比赛不仅是AI的一次历史转折,也为英伟达打开了突破口。英伟达开始与业界合作推动AI生态,推广开源AI框架,并与Google、Facebook等公司合作推动TensorFlow等AI技术发展。
这等于完成了黄仁勋口中的第二步,"open up GPU for programmability for all kinds of things"。
当GPU的算力价值被发现后,大厂也猛然醒悟,英伟达此前数年迭代和铺垫的CUDA,已然成为AI绕不开的一堵高墙。
为了筹建CUDA生态,英伟达为开发者提供了丰富的库和工具,如cuDNN、cuBLAS和TensorRT等,方便开发者进行深度学习、线性代数和推理加速等任务。此外,英伟达还提供包括CUDA编译器和优化器在内的完整开发工具链,使开发者能够更方便地进行GPU编程和性能优化。
与此同时英伟达也与许多流行的深度学习框架(如TensorFlow、PyTorch和MXNet)紧密合作,为CUDA提供了在深度学习任务中的显著优势。
这种“扶上马,送一程”的奉献精神,使英伟达仅用了两年半时间,就将CUDA生态的开发者数量翻了一倍。
这还不够,过去十余年里英伟达将CUDA的教学课程推广到超过350所大学,平台内有专业的开发者和领域专家,他们通过分享经验和解答疑难问题,为CUDA的应用提供了丰富的支持。
更关键的是,英伟达深知硬件作为护城河的缺陷在于没有用户粘性,于是将硬件与软件捆绑,GPU渲染要用CUDA、AI降噪要用OptiX、自动驾驶计算需要CUDA……
尽管英伟达目前凭借GPU+NVlink+CUDA垄断了AI算力90%的市场,但帝国的裂缝已经不止一条了。
2 一条条裂缝
AI厂商苦CUDA久矣,并不是危言耸听。
CUDA的神奇之处就在于它处在软硬结合的关键位置,对软件来说它是整个生态的基石,竞争对手难以绕过CUDA去兼容英伟达的生态;对硬件来说,CUDA的设计基本就是英伟达硬件形态的软件抽象,基本每个核心概念都和GPU的硬件概念相对应。
那么对于竞争对手来说,就只剩两个选择:
1 绕开CUDA,重建一套软件生态,这就要直面英伟达用户粘性的巨大挑战;
2 兼容CUDA,但也要面临两个问题,一是如果你的硬件路线和英伟达不一致,那么就有可能实现的低效且难受,二是CUDA会跟随英伟达硬件特性演进,兼容这也只能选择跟随。
但为了摆脱英伟达的钳制,两种选择都有人尝试。
2016年,AMD推出的基于开源项目的GPU生态系统ROCm,提供HIP工具完全兼容CUDA,就是一种跟随路线。
但因为工具链库资源匮乏、开发和迭代兼容性代价较大等掣肘,使ROCm生态难以壮大。在Github上,贡献CUDA软件包仓库的开发者超过32600位,而 ROCm只有不到600个。
走兼容英伟达CUDA路线的难点在于,其更新迭代速度永远跟不上CUDA并且很难做到完全兼容:
1 迭代永远慢一步:英伟达GPU在微架构和指令集上迭代很快,上层软件堆栈的很多地方也要做相应的功能更新。但AMD不可能知道英伟达的产品路线图,软件更新永远会慢英伟达一步。例如AMD有可能刚宣布支持了CUDA11,但是英伟达已经推出CUDA12了。
2 难以完全兼容反而会增加开发者的工作量:像CUDA这样的大型软件本身架构很复杂,AMD需要投入大量人力物力用几年甚至十几年才能追赶上。因为难免存在功能差异,如果兼容做不好反而会影响性能(虽然99%相似了,但是解决剩下来的1%不同之处可能会消耗开发者99%的时间)。
也有公司选择绕开CUDA,比如2022年1月成立的Modular。
Modular的思路是尽可能降低门槛,但更像是一种奇袭。它提出“用于提高人工智能模型性能”的AI引擎,通过“模块化”方式解决“当前AI应用栈常与特定硬件和软件耦合”的问题。
为了配合这个AI引擎,Modular还开发了开源编程语言Mojo。你可以把它想象成一个“专为AI而生”的编程语言,Modular用它开发各种工具整合到前面提到的AI引擎里,同时又可以无缝衔接上Python,降低学习成本。
但Modular的问题在于,其所设想的“全平台开发工具”太过理想化。
虽然顶着“超越Python”的头衔,又有Chris Lattner名声作为背书,但Mojo作为一种新语言,在推广上还需要经过众多开发者的考验。
而AI引擎要面临的问题就更多,不仅需要与众多硬件公司之间达成协议,还要考虑各平台之间的兼容。这些都是需要长时间的打磨才能完成的工作,到时候的英伟达会进化成什么样子,恐怕没人会知道。
3 挑战者华为
10月17日,美国更新了针对AI芯片的出口管制规定,阻止英伟达等公司向中国出口先进的AI芯片。根据最新的规则,英伟达包括A800和H800在内的芯片对华出口都将受到影响。
此前英伟达A100及H100两款型号限制出口中国后,为中国专供的“阉割版”A800和H800就是为了符合规定。英特尔同样也针对中国市场,推出了AI芯片Gaudi2。如今看来,企业们又要在新一轮出口禁令下再进行调整应对。
今年8月,搭载华为自研麒麟9000S芯片的Mate60Pro突然开售,瞬间引发了巨大舆论浪潮,使得几乎同一时间的另外一条新闻很快被淹没。
科大讯飞董事长刘庆峰在一个公开活动上罕见表态,称华为GPU可对标英伟达A100,但前提是华为派出专门工作组在讯飞成立专班工作优化的背景下。
这种突然的表态往往都有深层次的意图,虽然没有预知能力但其效用仍是为了应对两个月后的芯片禁令。
华为GPU,也就是昇腾AI全栈软硬件平台,全栈包括5层,自底向上为Atlas系列硬件、异构计算架构、AI框架、应用使能、行业应用。
基本上可以理解为华为针对英伟达做了一套平替,芯片层是昇腾910和昇腾310,异构计算架构(CANN)对标英伟达CUDA + CuDNN核心软件层。
当然差距不可能没有,有相关从业者总结了两点:
1 单卡性能落后,昇腾910与A100还有差距,但胜在价格便宜可以堆量,达到集群规模后整体差距不大;
2 生态劣势的确存在,但华为也在努力追赶,比如经过PyTorch社区与昇腾的合作,PyTorch 2.1版本已同步支持昇腾NPU,意味着开发者可直接在PyTorch 2.1上基于昇腾进行模型开发。
目前华为昇腾主要还是运行华为自家闭环的大模型产品,任何公开模型都必须经过华为的深度优化才能在华为的平台上运行,而这部分优化工作严重依赖于华为。
而在当前背景下,昇腾又具有特殊的重要意义。
今年5月,华为昇腾计算业务总裁张迪煊就已透露,“昇腾AI”基础软硬件平台已孵化和适配了30多个主流大模型,我国一半以上的原生大模型是基于“昇腾AI”基础软硬件平台打造,包括鹏程系列、紫东系列、华为云盘古系列等。今年8月,百度也官宣了推进在昇腾AI上与飞桨+文心大模型的适配。
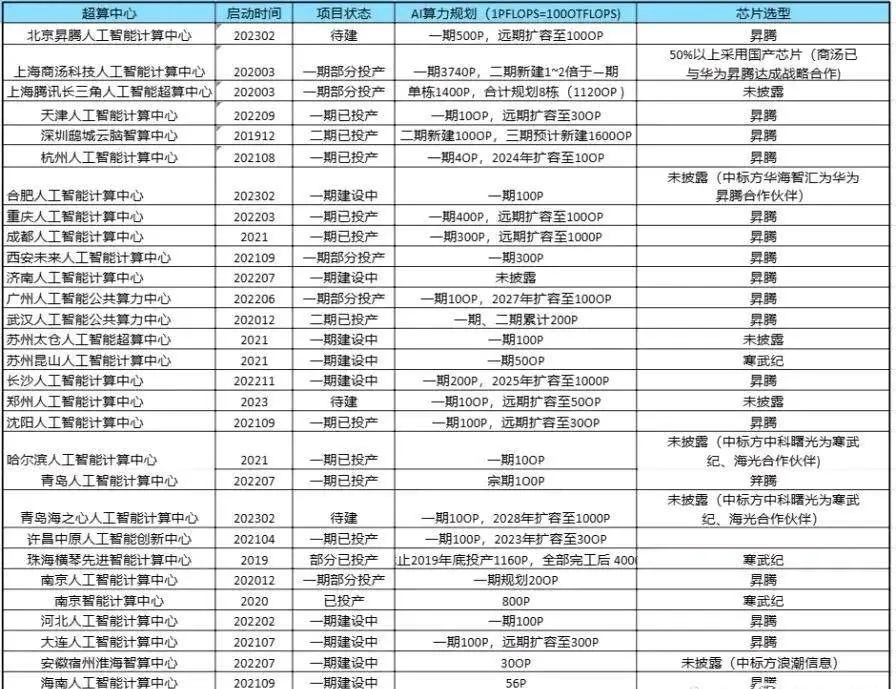
并且根据网络上流传的一张图片显示,中国人工智能超算中心除了未披露,基本都是昇腾,据称在新一轮芯片限令后,华为30-40%的芯片产能要留给昇腾集群,其余是Kirin。
4 尾声
在英伟达展开宏大叙事的2006年,没有人认为CUDA会是一个革命性的产品,黄仁勋要苦口婆心的说服董事会每年投入5亿美金,来赌一个回报期超过10年的未知,而当年英伟达的营收也不过30亿美金而已。
但在所有以技术和创新作为关键词的商业故事里,总有人因为对长远目标的持久坚持而收获巨大的成功,英伟达和华为都是其中的佼佼者。
参考资料
[1] 英伟达的「镰刀」,不是AI芯片,硅基研究室
[2] 为了成为“英伟达平替”,大模型厂商开卷了,小饭桌创服
[3] 成立仅1年,这家AI明星创企,想挑战英伟达,镁客网
[4] 英伟达帝国的一道裂缝,远川研究所
[5] 美计划加紧对华芯片出口,华为领衔演绎国产崛起,华西证券
[6] AIGC行业深度报告(11):华为算力分拆:全球AI算力的第二极,华西证券
[7] 2023年AIGC行业专题报告:AI 芯片四大技术路线,寒武纪复制英伟达,申万宏源
[8] CUDA如何成就NVIDIA:AI领域的巨大突破,腾讯云社区
免责声明:本文基于已公开的资料信息或受访人提供的信息撰写,但解码Decode及文章作者不保证该等信息资料的完整性、准确性。在任何情况下,本文中的信息或所表述的意见均不构成对任何人的投资建议。

 下载ECAD模型
下载ECAD模型





