


 1172
1172
从云端到网络边缘,NVIDIA GH200、H100和L4 GPU以及Jetson Orin模组在运行生产级 AI 时均展现出卓越性能。

NVIDIA GH200 Grace Hopper超级芯片首次亮相 MLPerf 行业基准测试,其运行了所有数据中心推理测试,进一步扩大了NVIDIA H100 Tensor Core GPU的领先优势。
总体测试结果表明,NVIDIA AI 平台无论是在云端还是网络边缘均展现出卓越的性能和通用性。
此外,NVIDIA宣布推出全新推理软件,该软件将为用户带来性能、能效和总体拥有成本的大幅提升。
GH200 超级芯片在 MLPerf 一骑绝尘
GH200将一颗Hopper GPU和一颗Grace CPU连接到一个超级芯片中。这种组合提供了更大内存、更快带宽,能够在CPU和GPU之间自动切换计算所需要的资源,实现性能最优化。
具体而言,内置8颗H100 GPU 的 NVIDIA HGX H100系统,在本轮每项MLPerf推理测试中均实现了最高吞吐量。
Grace Hopper 超级芯片和H100 GPU在所有MLPerf数据中心测试中均处于领先地位,包括针对计算机视觉、语音识别和医学成像的推理,以及应用于生成式AI的推荐系统和大语言模型(LLM) 等对性能要求更高的用例。
总体而言,此次测试结果延续了自2018年MLPerf基准测试推出以来,NVIDIA在每一轮AI训练和推理中都处于领先性能的纪录。
最新一轮MLPerf 测试包括一项更新的推荐系统测试,并新增首个GPT-J上的推理基准测试。GPT-J是一个由60亿个参数组成的大语言模型(LLM),而AI模型的大小通常根据它有多少参数来衡量。
TensorRT-LLM 大幅提升推理能力
为了应对各类复杂的工作负载,NVIDIA开发了一款能够优化推理的生成式AI软件——TensorRT-LLM。该开源库使客户能够在不增加成本的情况下将现有H100 GPU的推理性能提升两倍以上。由于时间原因,TensorRT-LLM没有参加8月的MLPerf提交。
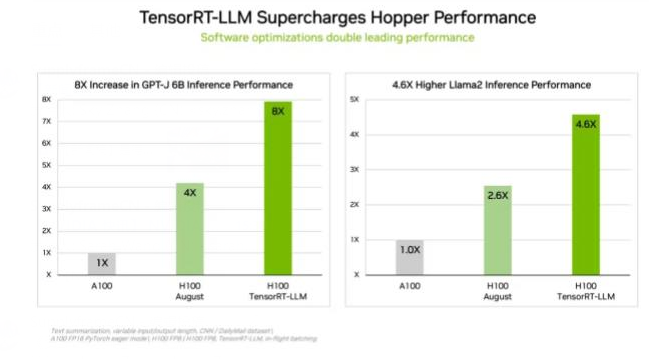
NVIDIA的内部测试表明, 在运行 GPT-J 6B 模型时,相较于没有使用TensorRT-LLM的上一代GPU,在H100 GPU上使用TensorRT-LLM能够实现高达8倍的性能提升。
该软件始于NVIDIA在对Meta、AnyScale、Cohere、Deci、Grammarly、Mistral AI、MosaicML(现为Databricks的一部分)、OctoML、Tabnine和Together AI等领先公司进行加速和优化LLM推理时所做的工作。
MosaicML在TensorRT-LLM 的基础上添加了所需的功能,并将这些功能集成到他们现有的服务堆栈中。Databricks工程副总裁Naveen Rao表示:“这已成为相当轻而易举的事情。”
Rao补充说:“TensorRT-LLM 简单易用、功能丰富且高效。它为正在使用NVIDIA GPU的 LLM服务提供了最先进的性能,并使我们能够将节省的成本回馈给我们的客户。”
TensorRT-LLM 是NVIDIA全栈AI平台持续创新的最新实例。这类持续的软件进步为用户带来了无需额外成本即可实现随着时间不断提升的性能,并且广泛适用于多样化的AI工作负载。
L4为主流服务器增强推理能力 在最新MLPerf基准测试中,NVIDIA L4 GPU 运行了所有工作负载,并全面展现了出色的性能。
例如,在紧凑型72W PCIe 加速器中运行时,L4 GPU的性能比功耗超出其近5倍的CPU提高了6倍。
此外,L4 GPU具有专用媒体引擎,与CUDA软件搭配使用,在NVIDIA的测试中为计算机视觉提供了高达120倍的加速。
谷歌云和许多系统制造商现已支持L4 GPU,为从消费互联网服务到药物研发各行业的客户提供服务。
大幅提升边缘性能
此外,NVIDIA采用了一种全新模型压缩技术来展示在一个L4 GPU上运行BERT LLM的性能提升高达4.7倍。该结果体现在MLPerf的“开放分区”中,这个类别旨在展示新能力。
这项技术有望应用于所有AI工作负载。它尤其适用于在空间和功耗受限的边缘设备上运行模型。
在另一个体现边缘计算领导力的例证中,NVIDIA Jetson Orin模块化系统将边缘AI和机器人应用场景中常见的计算机视觉用例——目标检测的性能比上一轮测试提升高达84%。
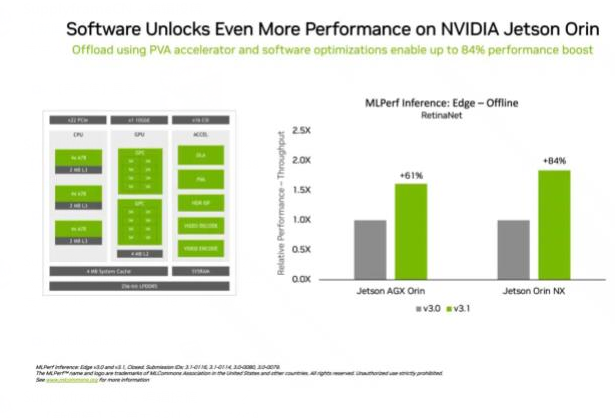
Jetson Orin性能的提升得益于软件可以充分利用该芯片的最新核心,如一个可编程视觉加速器、一颗NVIDIA Ampere架构GPU和一个专用深度学习加速器等。
灵活的性能与庞大的生态
MLPerf基准测试是透明且客观的,因此用户可以根据其结果做出明智的购买决定。该测试还涵盖了丰富的用例和场景,能够让用户获得可靠且可以灵活部署的性能。
本轮提交测试结果的合作伙伴包括微软 Azure和Oracle Cloud Infrastructure 等云服务提供商以及华硕、Connect Tech、戴尔科技、富士通、技嘉、惠与、联想、QCT、超微等系统制造商。
总体而言,MLPerf 已得到70多家机构的支持,包括阿里巴巴、Arm、思科、谷歌、哈佛大学、英特尔、Meta、微软和多伦多大学等。
请阅读技术博客,详细了解我们如何实现这些最新的成果。
NVIDIA在基准测试中使用的所有软件均可从 MLPerf 软件库中获得,因此每个人都能实现全球领先的结果。我们不断将这些优化措施整合到NVIDIA NGC软件中心的容器中供GPU应用使用。

 下载ECAD模型
下载ECAD模型





