


 2721
2721
探索FPGA加速语言模型如何通过更快的推理、更低的延迟和更好的语言理解来重塑生成式人工智能
简介:大语言模型
近年来,大型语言模型(Large Language Models,LLM)彻底改变了自然语言处理领域,使机器能够生成类似人类的文本并进行有意义的对话。这些模型,例如OpenAI的GPT,拥有惊人的语言理解和生成能力。它们可以被用于广泛的自然语言处理任务,包括文本生成、翻译、自动摘要、情绪分析等。
大语言模型通常是基于深度学习技术来构建,特别是广泛使用了transformer架构。Transformer是一类神经网络模型,擅长捕捉语言序列中的远关联关系,这使得它们非常适合于语言理解和生成任务。训练一种大语言模型的方法是将模型
暴露给大量文本数据中,这些文本数据通常来源于书籍、网站和其它文本资源。该模型学会了预测句子中的下一个单词,或者根据它所看到的上下文填充缺失的单词。通过这个过程,它获得了关于语法、句法的知识,甚至是一定程度的世界知识。
与大语言模型相关的主要挑战之一是其巨大的计算和内存需求。这些模型由数十亿个参数组成,需要强大的硬件和大量的计算资源来有效地训练和部署它们,正如Nishant Thakur在2023年3月于领英发布的文章《ChatGPT背后令人难以置信的处理能力和成本:构建终极AI聊天机器人需要什么?》中所讨论的。资源有限的组织机构和研究人员在充分利用这些模型的潜力方面经常遇到瓶颈,因为云端需要大量的处理能力或资金。此外,在生成响应时,为创建适当的符号、单词或单词子部分,上下文长度会急剧增长,对内存和计算资源产生更多的需求。
这些计算挑战导致更高的延迟,这使得大语言模型的采用变得更加困难,并且不是实时的,因此不那么自然。在这篇博客中,我们将深入研究大语言模型遇到的困难,并探索潜在的解决方案,这些解决方案可以为其增强的可用性和可靠性铺平道路。
大语言模型的加速
大语言模型的构建通常需要一个大规模的系统来执行该模型,这个模型会持续变大,在其发展到一定程度后,仅靠在CPU上的运行就不再具有成本、功耗或延迟的优势了。使用GPU或FPGA这样的加速器可显著提高计算能效、大幅降低系统延迟,并以更小的规模实现更高的计算水平。虽然GPU无疑正在成为硬件
加速的标准选择,主要是因为它具有的可访问性和易于编程特性;实际上,在低延迟方面,FPGA架构比GPU有更卓越的性能。
由于本质上GPU是采用扭曲锁定(warp-locked)架构,跨多个内核并行执行超过32个SIMT线程,因此它们通常也需要批量处理大量数据,以尝试和偏移warp-locked架构并保持流水线被充满。这等同于更大的延迟和更多系统内存的需求。同时,FPGA可构建自定义数据路径来同时在多个数据模块上执行多个不同的指令,这意味着它可以非常有效地运行,一直到批量大小为1,这是实时的,延迟要低得多,同时最大限度地减少外部存储器需求。因此,与其他竞争性架构相比,FPGA能够显著提高其TOPs的利用率——随着系统规模扩展到ChatGPT系统大小时,这种性能差距只会继续增加。
当系统规模扩展到需要超过8个处理器件时(GPT3的训练需要使用10,000个GPU),用Achronix的FPGA来执行大语言模型可在吞吐量和延迟方面胜过GPU。如果模型可以使用INT8精度,那么使用GPT-20B作为参考的Achronix FPGA则具有更大的优势,如下表所示。这些数据说明使用FPGA是有优势的,因为GPU需要较长的交付时间(高端GPU超过一年)、得到的用户支持可能也很少,并且比FPGA贵得多(每块GPU的成本可能超过10,000美元)。
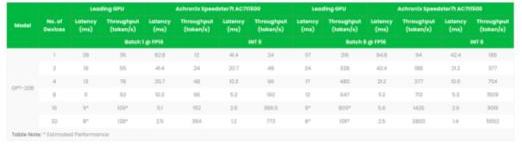
Speedster7t FPGA芯片与GPU的性能比较
将大语言模型映射到Achronix的FPGA加速器上 Achronix的Speedster7t FPGA具有一个独特的架构,使其非常适合这些类型的模型。首先,它有一个硬二维片上网络(2D NoC),解决了整个器件的数据传输以及输入输出。此外,它使用了带有紧耦合RAM的机器学习处理器(MLP),以便在计算之间实现高效的结果重用。最后,与GPU类似但与其他FPGA不同,Achronix的Speedster7t FPGA具有八组高效的GDDR6存储器IP,可支持更高的带宽,并且能够以4 Tbps的速度加载参数。
由于这些系统需要可扩展性,FPGA可以实现各种标准接口,以将加速卡互连在一起,并可实现卡之间无缝地传输数据。Achronix的Speedster7t AC7t1500器件具有32个100 Gbps的SerDes通道,不需要诸如NVLink这样的专有且成本高昂的解决方案。
大语言模型的未来:升级为增强型语言理解方案及领域特定方案
由于这些大语言模型需要巨大的规模才能以最小的延迟影响来执行训练和推理,模型的复杂性将继续增加,这将使得不断发展的语言理解、生成,甚至预测能力具有令人难以置信的准确性。虽然目前许多GPT类模型都是通用的,很可能接下来会出现针对某些领域,如医学、法律、工程或金融等而训练的专用模型。总之,在很长一段时间内,这些系统将协助人类专家处理由人工智能系统处理的更多平凡的任务,并为提供解决方案建议或协助完成创造性的任务。 联系Achronix,了解我们如何帮助您加速这些大语言模型系统。
在即将于9月14-15日在深圳市深圳湾万丽酒店举办的“2023全球AI芯片峰会”(第10号展位)上,Achronix将展出其最新的自动语音识别(Accelerated Automatic Speech Recognition, ASR)加速方案。它具有领先的超低延迟、大并发实时处理的特性,运行在VectorPath加速卡上的Speedster7t FPGA中。作为一种带有外接主机API的完整解决方案,其应用不需要具备RTL或FPGA知识。
Achronix还将介绍针对高带宽、计算密集型和实时处理应用的最新的FPGA和eFPGA IP解决方案,包括Speedster®7t系列FPGA芯片、Speedcore™ eFPGA IP和VectorPath®加速卡。

 下载ECAD模型
下载ECAD模型



.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)


.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)


.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)


%E6%98%AF%E8%A1%8C%E4%B8%9A%E9%80%9A%E7%94%A8%E7%9A%841.6T%E5%B9%B3%E5%8F%B0,%E9%87%87%E7%94%A8%E4%BE%BF%E6%90%BA%E5%BC%8F%E5%8F%B0%E5%BC%8F%E6%9C%BA%E6%88%96%E6%9C%BA%E6%9E%B6%E5%BC%8F%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88.png?x-oss-process=image/resize,m_fill,w_128,h_96)



 [下载]LAT1482 STM32G0单线串口通信帧错误问题解析
[下载]LAT1482 STM32G0单线串口通信帧错误问题解析
