


 3381
3381
2012年,谷歌团队推出著名的八层卷积神经网络模型AlexNet,在人脸识别方面大幅提升了图像识别准确率,带动了硬件层面卷积的普及。
2017年,谷歌团队又推出基于自注意力机制的模型Transformer,在语义理解方面大幅提升了语音翻译效果,带动了硬件层面GEMM的普及。
2018年,OpenAI团队推出一种预训练语言模型GPT(Generative Pre-trained Transformer),也就是最初代的GPT-1(12层),并通过了图灵测试。
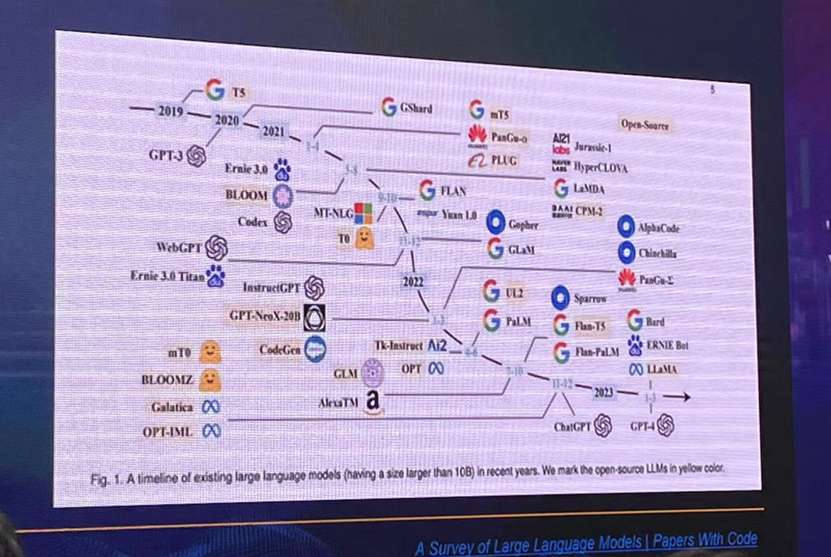
图源:WAIC,天数智芯
也许在GPT-1时代,大众还没有什么感受,但GPT-3、GPT-4架构下的ChatGPT让人工智能成功出圈,并产生了全球性的“大模型和AIGC热”。于是,我们从硬件的角度来看,GPT到底带来了哪些变革?
事实上,算力是关乎大模型产品成功与否的关键,那么大模型需要多少算力呢?天数智芯副总裁邹翾表示:“对于头部企业来讲,预计需要1万张最新的主流GPU卡,而对于追随企业来讲,为了追赶头部企业的步伐,他们在基础设施方面的需求可能更大。”
正是在这样的大算力需求下,市面上英伟达的芯片贵出天际。据悉,国内几家头部互联网厂家都向英伟达下了1.5万-1.6万的A800和H800订单,每家的金额在十几亿美金左右,而这些产能将在2024年得到基本保障。
在这样的大背景下,我们看到新闻,竟然有人开始走私GPU卡,特斯拉CEO马斯克对此表示:“目前,GPU比毒品更难获得”。当然,违法的行为不可取,但我们真切地看到了大模型“算力发动机”的威力。
换言之,大模型对硬件的最大需求就是要有可用的算力,那么这个“可用”到底如何体现呢?通常可以从三个方面来理解:
- 易用
需要利旧现有算法模块,且调优经验可借鉴
- 通用
需要可支持模型的快速变形,快速支持新算子,以及快速支持新通讯(重组)
- 灵活并行
需要满足访存全交换和计算全互联
结合当前市场上的可用产品,主要包括GPU和ASIC芯片。然而,相比于ASIC芯片,GPGPU具有更强的通用性,所以在主流的AI加速芯片市场上,GPGPU占到了90%的市场份额。
此外,虽然说大模型不像中、小模型那样依赖CUDA生态,看上去GPGPU和ASIC在大模型上的差距没有那么大,但不管是模型的训练还是部署,大模型早期的开放框架都是基于GPGPU架构实现的,因此GPGPU的软件生态会更为成熟,而ASIC还处在开局阶段。
对此,邹翾表示:“天数智芯作为国内第一家实现设计、制造、量产的GPGPU企业,当前已经实现了商业闭环,并在大模型训练领域取得了阶段性进展,完成了百亿级参数大模型训练。”
下图中为天数智芯推出的天垓100加速卡已经支持的模型训练集合:
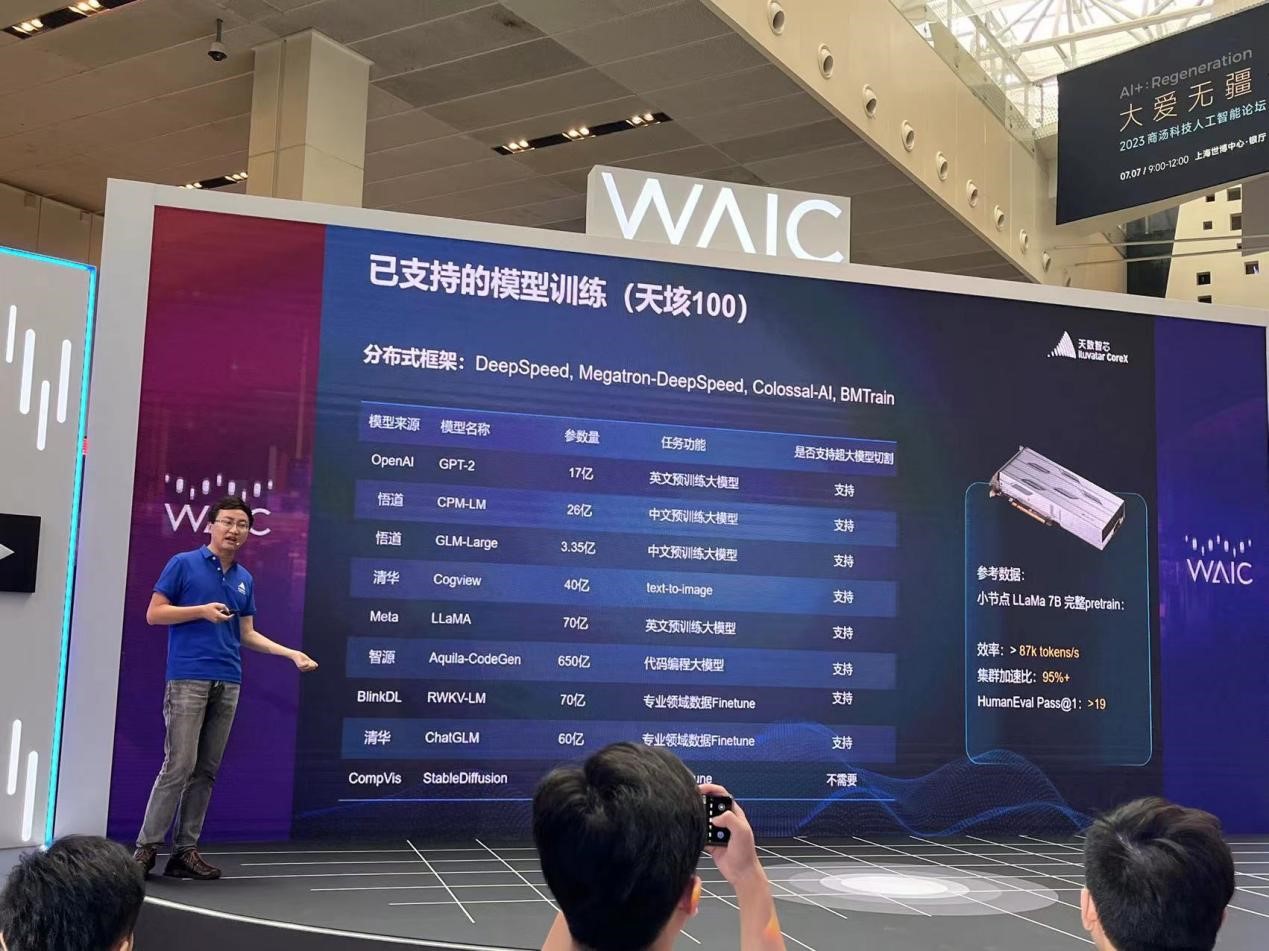
图 | 天垓100已支持百亿级参数大模型训练
从市场方面来看,邹翾认为:“去年还主要是天垓100在出货,而今年天垓100和智铠100一起出货,在整体市场体量方面会更加趋好。”

 下载ECAD模型
下载ECAD模型












 [课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
[课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
