


 3985
3985
英伟达在COMPUTEX上再次展现了“芯基建狂魔”的硬核实力。
集成了256 个 GH200 芯片的 DGX GH200 、提供1 exaflop性能的超级计算机把基建实力拉满。作为AI超算,DGX GH200的技术亮点主要体现在大内存技术、互连技术NVLink、以及针对Transformer大模型的加速优化。英伟达这款产品,也让业界看到了AI大算力系统的升级方向。

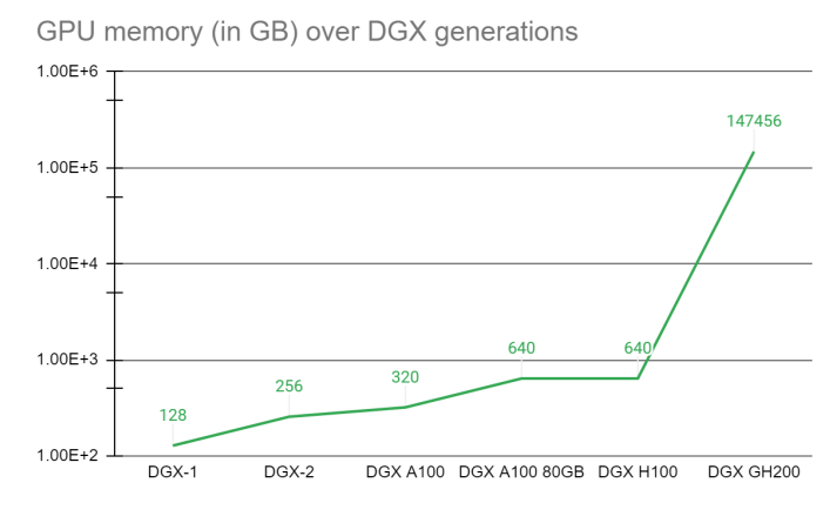
首先要说的是144TB共享内存空间的AI超级计算机,这个内存空间由256个Grace Hopper超级芯片提供,相比于单个NVIDIA DGX A100 320 GB系统,NVIDIA DGX GH200提供了近500倍的内存,形成了一个巨大的数据中心级GPU。超大的内容容量,显然是为了支持更大模型的训练。
这种通过GPU内存的代际跃进,显著提高了AI和HPC应用的性能。许多主流的AI和HPC工作负载可以完全驻留在单个NVIDIA DGX H100的聚合GPU内存中。根据官方给出的对比结果,对于这些工作负载,DGX H100是最高效的解决方案。其他工作负载,如深度学习推荐模型(DLRM)和大数据分析工作负载,使用DGX GH200可以实现4倍到7倍的加速。
其次是超算系统的“黏合剂”,也就是用于互连的NVLink技术。对于大规模的AI扩展,NVLink技术必不可少的。GH200超级芯片使用了NVIDIA NVLink-C2C芯片进行互连,将Grace CPU与H100 Tensor Core GPU整合在一起,从而不再需要传统的CPU至GPU PCIe连接。与最新的PCIe技术相比,这将GPU和CPU之间的带宽提高了7倍,将互连功耗减少了5倍以上,并为DGX GH200超级计算机提供了一个600GB的Hopper架构GPU构建模块。
DGX GH200也是第一款将Grace Hopper超级芯片与NVIDIA NVLink Switch System配对使用的超级计算机,这种新的互连方式,能够使DGX GH200系统中的所有GPU作为一个整体协同运行。
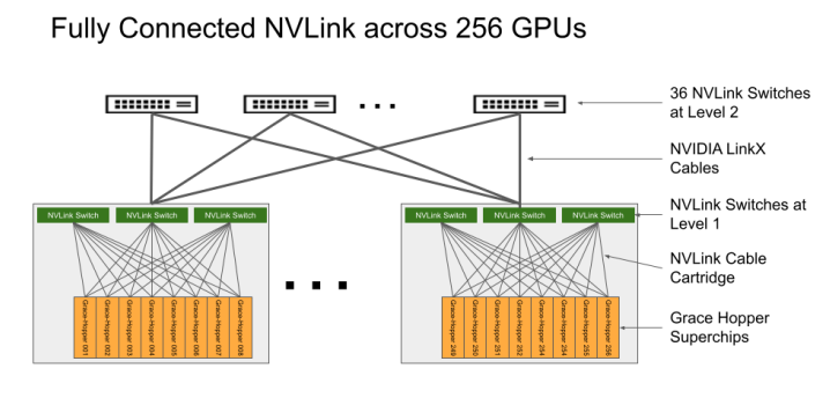
在不影响性能的前提下,上一代系统只能通过NVLink把8个GPU整合成一个GPU。DGX GH200架构相比上一代将NVLink带宽提升了48倍以上,实现在单个GPU上通过简单编程即可提供大型AI超级计算机的能力,由此也体现出了互连技术对于未来超大算力的AI的重要性。
正是通过NVLink互连技术、NVLink Switch System,才能使256个GH200超级芯片相连,使它们能够作为单个GPU运行。
第三是针对Transformer计算的优化,GH200新的 Transformer 引擎与Hopper FP8 张量核心相结合,在大型NLP模型上提供比A100服务器高达9倍的AI训练速度和30倍的AI推理速度。
此外在软件方面,DGX GH200超级计算机包含的NVIDIA软件,可为最大的AI和数据分析工作负载提供一个交钥匙式全栈解决方案。NVIDIA Base Command软件提供AI工作流程管理、企业级集群管理和多个加速计算、存储和网络基础设施的库,以及为运行AI工作负载而优化的系统软件。
还有NVIDIA AI Enterprise,即NVIDIA AI平台的软件层。它提供100多个框架、预训练模型和开发工具,以简化生成式AI、计算机视觉、语音AI等生产AI的开发和部署。
从核心的超级芯片芯片、到互连技术再到算法引擎的优化、以及配套软件的升级,英伟达此次推出的E级AI超算系统再次带给业界惊喜,也清晰展现了软硬件全新升级的优化方向。目前,谷歌云、Meta和微软是首批有望接入DGX GH200来探索其用于生成式AI工作负载的能力的公司。NVIDIA还打算将DGX GH200设计作为蓝图提供给云服务提供商和其他超大规模企业,以便他们能够进一步根据他们自己的基础设施进行定制。
另据透露,基于DGX GH200,英伟达正在打造自己的AI超级计算机NVIDIA Helios,以支持研发团队的工作。NVIDIA Helios超级计算机将配备四个DGX GH200系统,每个都将通过NVIDIA Quantum-2 InfiniBand网络互连,以提高训练大型AI模型的数据吞吐量。Helios将包含1024个Grace Hopper超级芯片,预计将于今年年底上线。

网络定义数据中心的时代到来
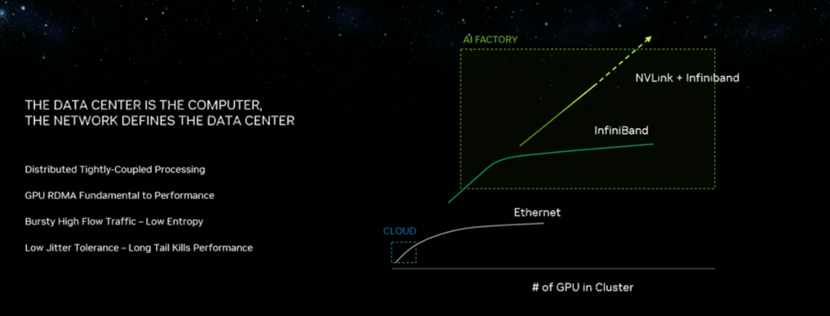
黄仁勋指出,目前主要有两种类型的数据中心。一种是用于超规模的,有各种不同类型的应用程序、工作负载、租户数量非常多,工作量非常异构、工作负载是松散耦合的;另一种则像是超级计算数据中心/AI超算计算机,工作负载紧密耦合,租户数量少,但需要在非常大的计算问题上实现高吞吐量,在整个超级计算机上运行一个工作负载的成本非常昂贵,以至于无法承受网络中的任何损失。
而以太网是基于TCP的通信协议,它很有弹性,每当出现丢失数据包丢失时,它都会重新传输。这也正是当今互联网诞生的原因,它几乎可以从任何地方互连组件,如果它需要太多的协调,这个庞大的网络是不可能实现的。他表示,随着AI的普及,要使世界上任何数据中心都能承载AI工作负载,就必须端到端地了解数据中心,从交换机到软件到任何可能的瓶颈,必须通过自适应路由来协调流量,这样才能处理拥塞控制,避免某个区域的流量过于饱和,从而导致数据包丢失,而这是高吞吐量工作负载所根本负担不起的丢包问题。
基于上述判断,黄仁勋认为,现在的数据中心实则是由计算机网络定义了数据中心的功能。英伟达推出的NVIDIA Spectrum-X 加速网络平台,可以说为新一代AI工作负载扫清障碍。可以提高基于以太网 AI 云的性能与效率,助力数据中心满足超大规模生成式AI工作负载需求。
NVIDIA Spectrum-X是基于网络创新的新成果而构建的,将 NVIDIA Spectrum-4以太网交换机与 NVIDIA BlueField-3 DPU紧密结合,取得了1.7倍的整体AI性能和能效提升,同时可在多租户环境中提供一致、可预测的性能。Spectrum-X 还提供 NVIDIA 加速软件和软件开发套件(SDK),使开发人员能够构建软件定义的云原生AI应用。
首次将高性能计算能力引入以太网市场,英伟达将带来这两大改变:第一,自适应路由基本上是根据通过数据中心的流量来判断,根据交换机的哪个端口过度拥塞,由BlueField-3 DPU发送到另一个端口,另一个端口的BlueField-3 DPU再将数据发送给CPU,这期间无需任何的CPU干预。第二,拥塞控制。某些端口可能会变得严重拥塞,在这种情况下,交换机会根据看到的网络的执行情况,与发送器进行通信(比如提示:不要立即发送更多数据,因为正在拥塞),实际上,拥塞控制的网络基本上需要一个系统来实现,该系统包括软件、与所有端点一起工作的交换机,以全面管理数据中心的拥塞或流量和吞吐量。
这种端到端的功能交付,可以减少基于Transformer的大规模生成式AI模型的运行时间,助力网络工程师、AI数据科学家和云服务商及时取得更好的结果,并更快做出明智的决策。全球头部超大规模云服务商、领先的云创新企业正在采用 NVIDIA Spectrum-X。
据介绍,NVIDIA Spectrum-X 网络平台具有高度的通用性,可用于各种 AI 应用,它采用完全标准的以太网,能够与现有的以太网堆栈实现互通。
作为 NVIDIA Spectrum-X 参考设计的蓝图和测试平台,NVIDIA 正在构建一台超大规模生成式 AI 超级计算机,命名为 Israel-1。它将被部署在 NVIDIA 以色列数据中心,由基于 NVIDIA HGX平台的戴尔 PowerEdge XE9680 服务器, BlueField-3 DPU 和 Spectrum-4 交换机等打造而成。
为系统制造商提供模块化架构,满足多样化加速需求
为了满足全球数据中心多样化的加速计算需求,英伟达还发布了NVIDIA MGX服务器规范,意在为系统制造商提供了一个模块化参考架构,快速、经济高效地制造100多种服务器机型,适配广泛的AI、高性能计算和元宇宙应用。
基于MGX,制造商以一个为加速计算优化的服务器机箱作为基础系统架构入手,然后选择适合自己的GPU、DPU和CPU。不同的设计可以满足特定的工作负载,如HPC、数据科学、大型语言模型、边缘计算、图形和视频、企业AI以及设计与模拟。AI训练和5G等多种任务可以在一台机器上处理,而且可以升级到未来多代硬件。MGX还可以集成到云和企业数据中心。
MGX提供不同的规格尺寸,并兼容当前和未来多代NVIDIA硬件,包括:
机箱:1U、2U、4U(风冷或液冷)
GPU: 完整的NVIDIA GPU产品组合,包括最新的H100、L40、L4
CPU:NVIDIA Grace CPU超级芯片、GH200 Grace Hopper超级芯片、X86 CPU
网络产品:NVIDIA BlueField-3 DPU、ConnectX®-7网卡
据了解,ASRock Rack、ASUS、GIGABYTE、Pegatron、QCT和Supermicro将采用MGX,它可将开发成本削减四分之三,并将开发时间缩短三分之二至仅6个月。
写在最后
在当天的主题演讲中,黄仁勋回溯了从上世纪六十年代到如今的计算变迁。他提到,1964年,IBM推出了360系统,AT&T向世界展示了第一款通过铜线和双绞线编码、压缩流传输图片的手机,时至今日,视频流大约占据了互联网每天65%的流量。
工作负载已经发生了深刻的变化,“每一个数据中心、每一台服务器,都要具备生成式AI负载的能力”,黄仁勋表示。













 [课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
[课程]STM32电机控制软件开发软件X-CUBE-MCSDK 6x介绍
