


 1.2万
1.2万
“算力”(Computility,也被称为计算能力或计算力)通常而言是指计算机、服务器、GPU或其他硬件设备执行计算任务的速度和能力。算力的英文名是computility。其中的compu-是计算的词根,表达“算”的含义,-utility是效用、实用的意思。computility用来表达计算的能力,即算力。近年来,“算力”被全社会高度关注,同时对于算力的准确量化描述也非常混乱,例如:
“每秒算力可达116亿亿次”
问题:执行的啥计算任务呀?也没有讲数据类型(整型?浮点数?),也不提精度(整型多少位?双精浮点?单精度浮点?),也不讲是AI算力还是通用算力,等等。
由此,也出现了“已有算力不够用,新建算力用不了”的怪事。本系列文章试图澄清算力的各种信息,并提出算力分层定义的观点,总共分为三层:
- 初级算力:即硬件spec.描述的算力,应该采用FLOPS、TOPS加“计算类型和精度”,加“算力类型”(CPU通用算力,GPU算力,DSA算力)准确描述。该层最重要的是计算芯片架构的设计能力和半导体制造工艺,当下,多数情况描述的算力多么强大都只是指初级算力。(注释:DSA(Domain Specific Architecture,特定领域架构)在本文泛指市面上讲得NPU、TPU、XPU等等专用加速卡。)
- 中级算力:即计算硬件通过基础计算软件层,向算法和应用层提供的实际计算的能力,在实践中初级算力要转换为中级算力面临两个问题:一是是否可行,二是转换效率。基本上,通用算力可以用Linpack等测试基准进行衡量(求解线性方程),AI算力的衡量可以使用AIPerf、MLPerf等衡量。该层最重要的是计算基础软件栈的软件能力,具体指高性能计算库、异构计算框架、领域编译器等。用户只会为有效算力而付费。
- 高级算力:各种算法和应用被封装成领域服务,用户可以直接获得跨领域的具体能力,也许可以叫FAAS,用户为具体服务而付费。该层最重要的是对于领域和应用场景核心算法的大规模并行化算法的构建能力。
对算力分层描述的重要意义在于:
- 更为准确描述一个计算中心执行计算任务的能力。
- 急需提升我国对于计算基础软件层的重视程度。
- 使“算力”从低层次商品向高层次商品发展,促进实现算力商业化。
“初级算力”如何准确描述
关于“算力”的量词介绍
浮点数运算能力通常使用以下单位描述:
- FLOPS(Floating-Point Operations Per Second) - 这是衡量计算机或其他设备执行浮点运算速度的基本单位,表示每秒钟可以执行多少次浮点运算(加、减、乘和除等运算)。FLOPS 以前通常用于衡量大规模科学计算和数值模拟等需要双精度浮点数计算的应用程序,现在也被用于描述AI高精度训练算力。
- 1 GFLOPS(Giga-FLOPS),表示每秒钟执行十亿次浮点运算(10^9)。
- 1 TFLOPS(Tera-FLOPS),表示每秒钟执行1万亿次浮点运算(10^12)。
- 1 PFLOPS(Peta-FLOPS),表示每秒钟执行1千万亿次浮点运算(10^15)。
- 1 EFLOPS(Exa-FLOPS),表示每秒钟执行1百亿亿次浮点运算(10^18)。
- 1 ZFLOPS(Zetta-FLOPS),表示每秒钟执行十亿亿亿次浮点运算(10^21)。
- 1 YFLOPS(Yotta-FLOPS),表示每秒钟执行1万亿亿亿次浮点运算(10^24)。
整型数据运算能力通常使用TOPS(Tera Operations Per Second)来描述,即每秒多少万亿次(10^12)。对于64位CPU处理器,指的就是64位整型数据的处理能力。但在GPU和DSA的领域,描述多少TOPS,可能是INT32,也有可能是INT8,还有可能是INT4。(备注:对于CPU性能的强弱,还有DMIPS(Dhrystone Million Instructions executed Per Second)来描述,即每秒执行多少百万条指令)。
关于“算力”的计算精度
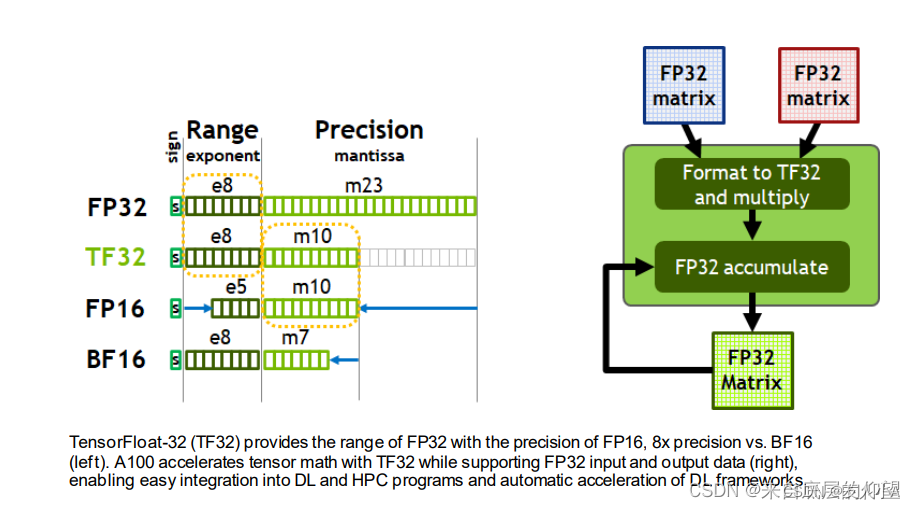
在科学计算领域,?FLOPS以前通常指双精度浮点数(FP64)。现在也被用于人工智能领域,但通常指的是其他精度(FP32/FP16/BF16/INT8等类型),同时还引入了一些新的浮点数格式。下面是一些常见的计算中使用的浮点数格式:
FP64:双精度浮点数,占用64位存储空间,通常用于大规模科学计算、工程计算等需要高精度计算的算法。
FP32:单精度浮点数,占用32位存储空间。与双精度浮点数相比,存储空间较小但精度较低,部分科学计算和工程计算也可以使用FP32,但通常也用于神经网络的前向推理和反向传播计算。
FP16:半精度浮点数,占用16位存储空间。存储空间更小但精度进一步降低,通常用于模型训练过程中参数和梯度的计算。
BF16: 用于半精度矩阵乘法计算(GEMM)的浮点数格式,占用16位存储空间。相对于FP16,在保持存储空间相同的情况下能够提高运算精度和效率。
TF32:TensorFLoat-32,是NVIDIA定义的使用TensorCore的中间计算格式。
INT8:8位整数,用于量化神经网络的计算,由于存储和计算都相对于浮点数更加高效,在低功耗、嵌入式系统和边缘设备等领域有着广泛的应用。用TOPS(Tera Operations Per Second,每秒处理的万亿级别的操作数)作为计算性能的单位。
INT4:4位整数,只能表示-8到7的16个整数。因为新的量化技术出现,追求更低的存储空间,减少计算量和更高的算力密度,而产生的新格式。
其他标准的整数类型,16位整型INT16,32位整型INT32,deng64位整型等。
现在你看到这个计算中心,每秒可以计算多多多少次。就需要留意”计算格式/计算精度”了。另外,引入了POPS这个名词,POPS是神经网络处理器(NNP)性能的单位,全称为“Per Second Operations Per Second”,即每秒钟的计算数量,这个单位似乎使用频率不高。

A800的初级算力规格(图1)
- A100的卡有7项算力规格描述。
- 这里面的计算格式描述就有6种。

intel CPU的初级算力规格(图2)
另外,神经网络处理器(NNP)性能描述虽然引入了POPS作为单位,全称为“Per Second Operations Per Second”,即每秒钟的计算数量。也同样存在类似的问题,也少人使用。
关于通用算力和专用算力有差异!
(图1)NVIDIA A100,硬件算力是9.7TFLOPS
(图2)Intel的i9-12900K,硬件算力才0.8192TFLOPS
硬件算力为啥差一个数量级呀,是intel不要脸了吗?
当然不是,这是因为GPU和CPU的设计目标不同,算力分为通用算里和专用算力(GPU算力、AI算力)。GPU在设计时专注于进行大量并行计算,因此它们采用了更多的小计算单元(即ALU)和更多的流处理器,这使得它们能够在单位时间内完成更多的计算。而CPU则更加注重单线程处理能力和数据缓存,具有更多指令集条数、更高效的缓存和更快的时钟速度,每个计算单元大,但数量相对较少。这就是为什么GPU的算力可以达到数以TFLOPS级别,而CPU通常只能达到数百GFLOPS的原因。这也是通用算力和AI算力的根本性差异。
CPU堆核心数和GPU堆核心数也不是一个概念。
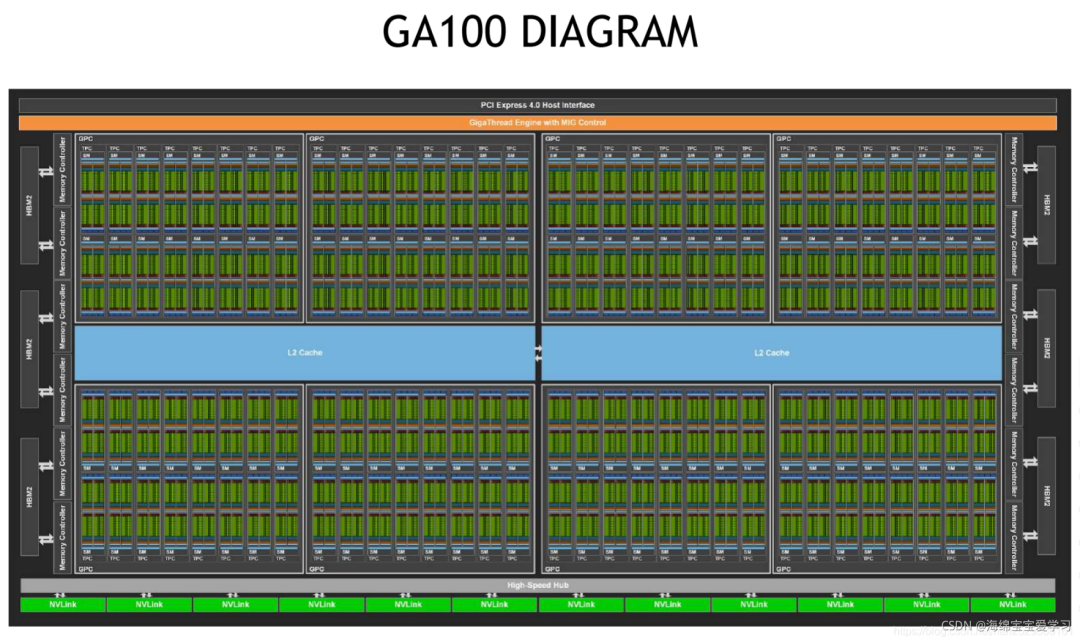
A100有了6912个FP32 CUDA Core
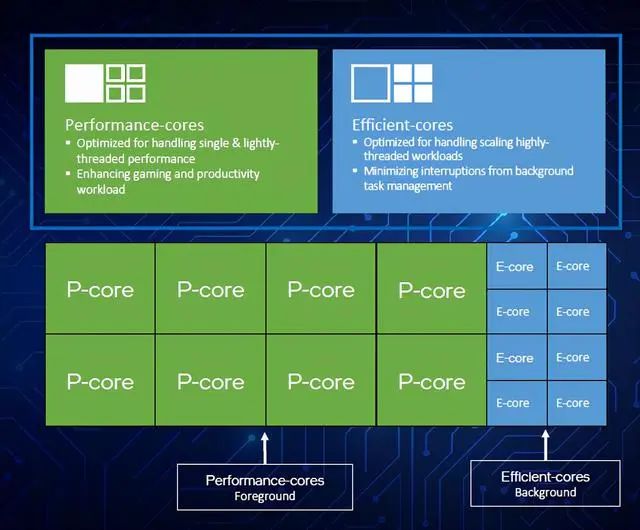
i9-12900K有8个性能核加8个能效核
展开一点点,GPU和CPU的核心虽然都是进行运算的单元(ALU)。CPU的设计目标是满足各种可能的应用,强调通用性,例如各种办公软件,网络服务,用户交互软件等等。GPU和DSA强调某一些领域和算法的大规模并行计算,例如图像渲染,深度学习等;
关于超算、智算、超脑等
超级计算机的TOP500排名的性能指标,包括Rmax(最大性能)和Rpeak(理论性能)。Rmax是指超级计算机在实际运行中所能达到的最大计算性能,即每秒钟所能计算的浮点数的数量(FLOPS)。而Rpeak是指超级计算机按照其设计时理论上所能达到的最大计算性能,实际上Rmax值往往会低于Rpeak值。排名靠前的超级计算机通常具备更高的计算性能、更强的可扩展性和更高的能效比。尽管TOP500排行榜的排名主要依据性能指标,但也会考虑其他因素,如超级计算机应用领域、处理器类型、计算节点数量等。相对比较严谨。
世界第一台E级超算是美国橡树岭国家实验室(ORNL)的Frontier,在2022 年 6 月高性能计算的TOP500 榜单中,Frontier 位列第一名,速度为 1.685 EFLOPS。(题外话:有新闻说该超算出现大量故障,机器甚至于无法完整运行一整天。不知现在怎样了?)
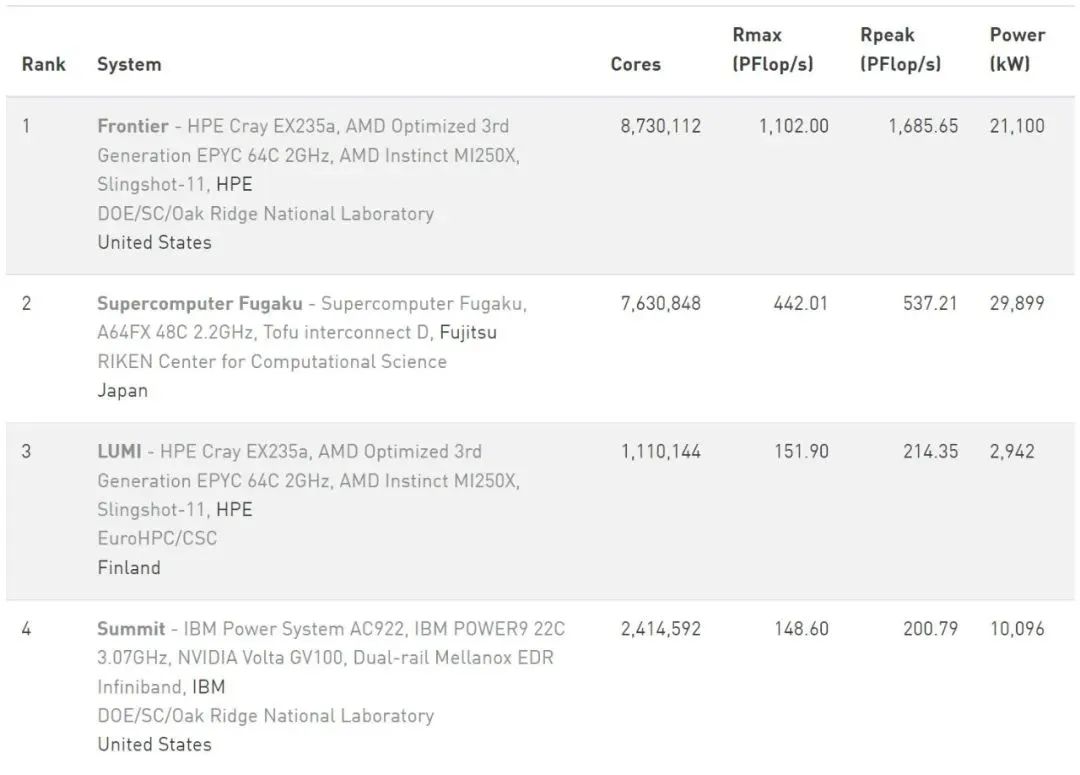
世界TOP 500超级计算机排行榜
现在,您应该知道“每秒算力可达116亿亿次”的算力中心,通常只是混淆描述算力规模,根本无法和TOP500的超算1.685 EFLOPS类比了吧!这些算力中心基本无法进行科学计算,甚至于在运行类似ChatGPT这种AI大模型实际能效比也不高。
所以,对于描述算力中心的描述,我国还出现的“智算”、“超级大脑”等名词。如果基础软件不行,也就徒剩“初级算力”的spec参数和猛力造词,比气势!
智算出处:《后汉书·荀彧传论》:“常以为中贤以下,道无求备,智筭有所研疎,原始未必要末,斯理之不可全诘者也。”
最后,以澎峰科技与西研院联合研发的RISC-V高性能通用计算型服务器为例,HS-S1-2服务器描述的算力为4TFlops(FP64)的初级算力,已然挤进来了国产处理器的第一梯队,但计算软件栈仍有许多工作要展开。目前已经开放预定。我们期待RISC-V高性能服务器不单能满足国内自主可控的需求,最终还能卷向全球!


 下载ECAD模型
下载ECAD模型


