


 2344
2344
从时间维度上看,BEVFormer已是历史产物,或许几个月、最多一两年后,一个真正的“王炸”会出现。
2021年7月,特斯拉展示了基于BEV+Transformer(BEVFormer)的自动驾驶感知新范式,在取得了惊艳的效果后,国内也掀起“跟风潮”。
近期,理想、蔚来、小鹏、小马智行、百度等多家主流车企、自动驾驶方案解决商推出相关量产方案。
一时间,BEV越发“火”了起来。
这背后逻辑也很好理解。一方面,BEV技术已经日渐成熟,从预研阶段基本走到了量产落地阶段;另外一方面,今年可能会是从高速NOA走向城区NOA量产的元年,在更加复杂的智驾场景下,BEV所带来的优势能更好地得到体现。
与此同时,在智能驾驶商业化进展不及预期的大背景下,BEV也可以作为相关企业难得的“技术卖点”。
因此,在这个时间节点,我们试图按照What-Why-Who-How的逻辑,对BEV+Transformer技术本身,以及背后的商业价值可能性进行探讨。
What:什么是BEV+Transformer
首先解决技术概念问题。
BEV(Bird's-eye-view),即鸟瞰图视角,是自动驾驶跨摄像头和多模态融合背景下的一种视角表达形式。
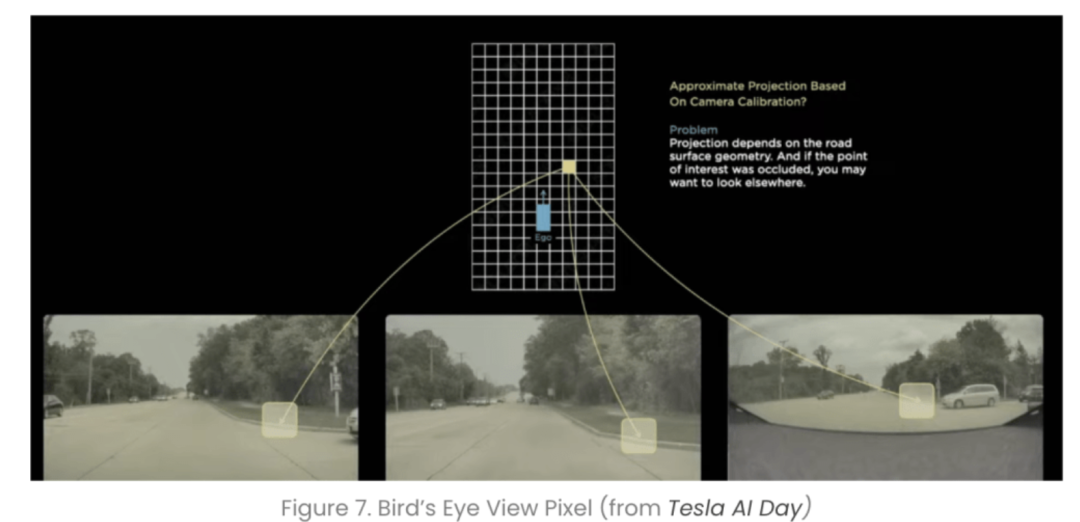
它的核心思想,是将传统自动驾驶2D图像视角(Image View)加测距的感知方式,转换为在鸟瞰图视角下的3D感知。
从实现任务来说,BEV的核心是将2D图像作为输入,最终输出一个3D的框架,在这个过程中,如何将不同传感器的特征(feature)实现最优表达是难点。
目前行业有两种常见的方式,一种是正向思维,采用自底向上、从2D到3D的方式,先在2D视角去每个像素的深度,再通过内外参投影到BEV空间,通过多视角的融合生成BEV特征,但对深度的估计一直都是难点。
另一种方法是逆向思维,采用自顶向下、从3D到2D的方式,先在BEV空间初始化特征,在通过多层transformer与每个图像特征进行交互融合,最终再得到BEV特征。
在第二种方法中,因为Transformer的存在,使得“逆向思维”成为了可能。

Transformer是一种基于注意力机制(Attention)的神经网络模型,由Google在2017年提出。与传统神经网络RNN和CNN不同,Transformer不会按照串行顺序来处理数据,而是通过注意力机制,去挖掘序列中不同元素的联系及相关性,这种机制背后,使得Transformer可以适应不同长度和不同结构的输入。
Transformer问世后,先在自然语言处理NLP领域大放异彩,之后被逐步移植到计算机视觉任务上,也取得了惊人的效果,实现了NLP和CV在建模结构上的大一统,使视觉和语言的联合建模更容易,两个领域的建模和学习经验可以通过深度共享,也加快各自领域进展。
Why:为什么需要基于Transformer的BEV
在厘清技术原理后,其实也就理解了“为什么需要”的问题:识别准,精度高,方便和激光、毫米波雷达做前融合等。
具体延展来看,BEV可以带来四大优势。
第一,BEV视角下的物体,不会出现图像视角下的尺度(scale)和遮挡(occlusion)问题。由于视觉的透视效应,物理世界物体在2D图像中很容易受到其他物体遮挡,2D感知只能感知可见的目标,而在BEV空间内,算法可以基于先验知识,对被遮挡的区域进行预测。
第二,将不同视角在BEV下进行统一表达,能极大方便后续规划和控制任务。主流规划和控制算法,不论上游传感器信息来自什么视角,经过融合之后,都会转换到以自车为中心坐标系中(Vehicle Coordinate System,VCS),对VCS来说,最适合的其实就是BEV视角,也就是BEV感知结果输出的空间是规划和控制任务的标准输入。
第三,BEV能够给系统带来巨大的提升。摄像头感知算法工作在2D空间,而雷达感知算法工作在3D空间,在对2D与3D几何关系融合过程中,会丢失大量的原始信息,采用BEV感知系统中,摄像头、激光雷达、毫米波雷达感知均在BEV空间中进行,融合过程提前。BEV还可以引入过去时间片段中的数据,实现时序融合,最终使感知效果更加稳定、准确。
第四,BEV能够实现端到端优化。感知任务中的识别、跟踪和预测本质是一个串行系统,系统上游误差会传递在下游误差,在BEV空间内,感知和预测都在同一个空间进行,可以通过神经网络做到端到端的优化,输出“并行”结果,而整个感知网络可以以数据驱动方式来自学习,实现快速迭代。
可以理解为,BEV可以实现将360度环视的时间、空间融合,再加上Transformer架构可以输出静态的车道线、红绿灯、道路边缘信息等,以及动态的有行人、两轮车、汽车等,同时还应用了端到端的预测能力,结合时序帧能对周边的车辆做未来3-6秒的轨迹预测。
这也意味着,端到端的算法有了闭环的希望。
Who: 行业最佳实践是特斯拉
特斯拉是第一个在工业界采用BEV+Transformer进行视觉感知任务的企业。
在其感知任务中,首先利用主干网络对各个摄像机进行特征提取,再利用Transformer将多摄像机数据从图像空间转化为BEV空间。
在这个空间里面,通过深度学习去完成一个特征的融合,然后再通过一个3D的解码器,直接端到端输出最后的一个3D检测和道路结构信息,这样下游的规划与控制直接可以在BEV的空间上去进行。
这一次革命,让马斯克可以自信地对外宣称,特斯拉感知不依赖激光雷达和毫米波雷达,依靠纯视觉,也可以得到准确三维世界信息。
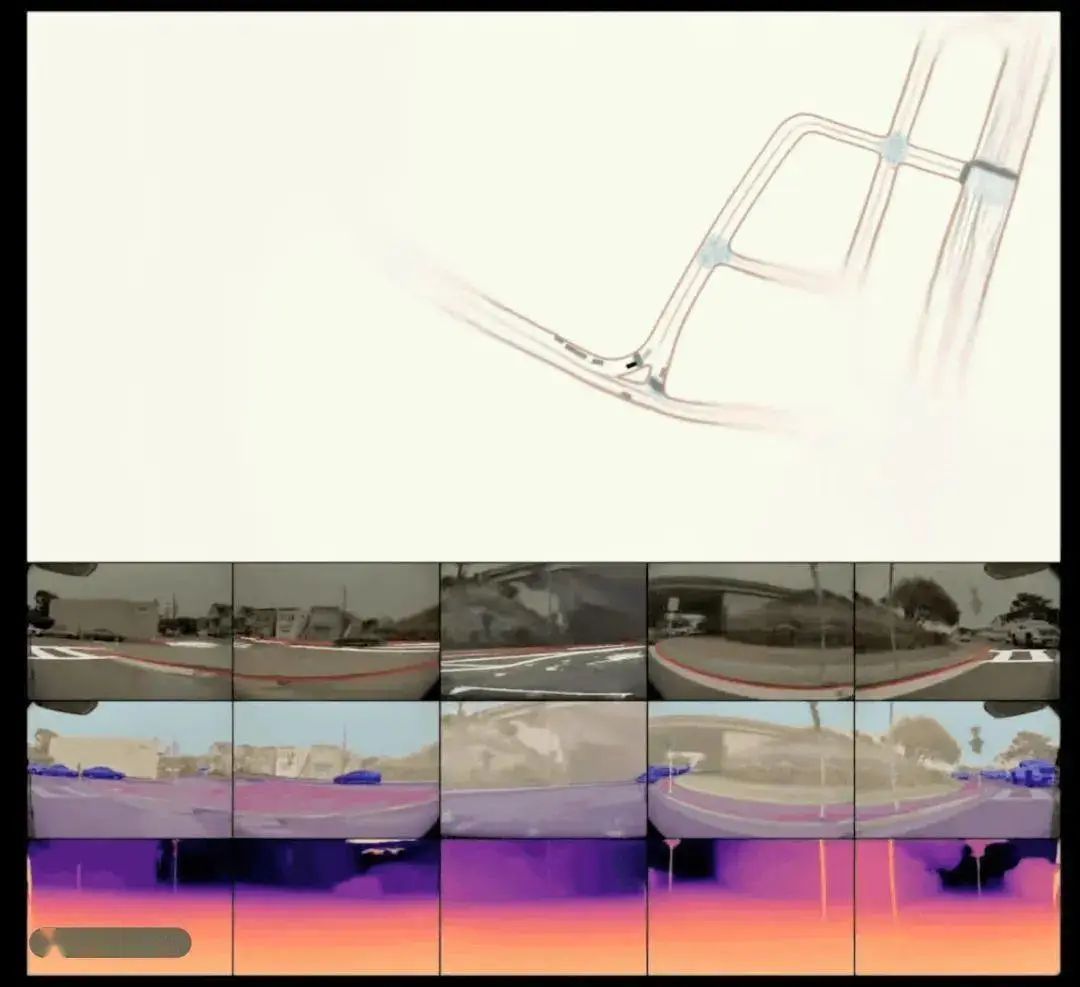
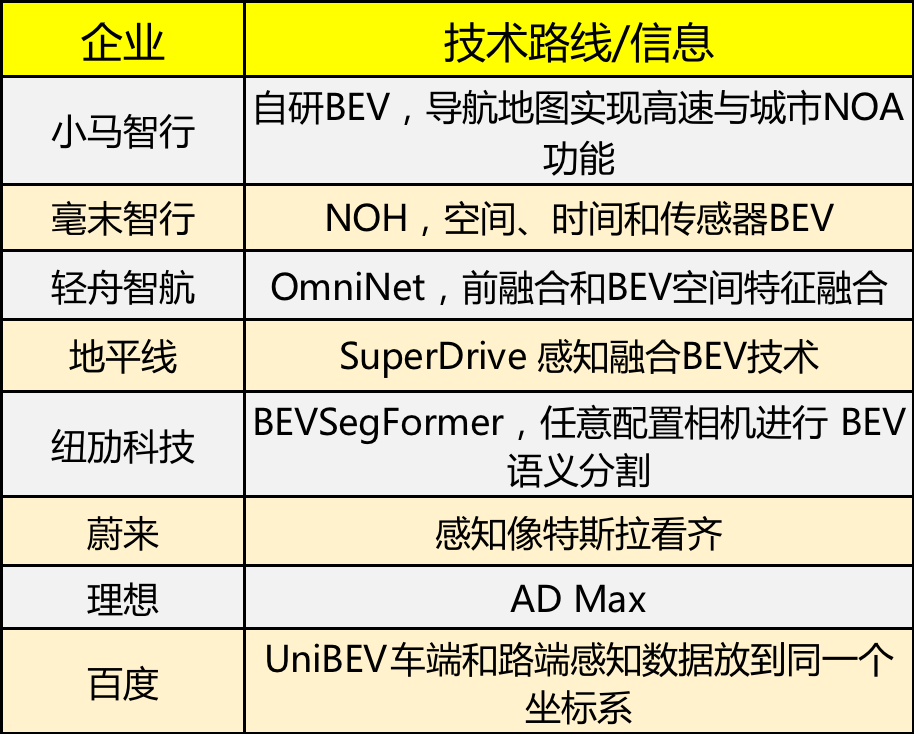
基于以上实践,众多车企以及智驾供应商都开始尝试BEV+transformer,车企里的代表蔚来、理想、小鹏;智驾供应商里面的百度、毫末、地平线、小马、轻舟等等,在具体使用方法上每一家有“微调”,但是整体还是跟随特斯拉的节奏在走。
How:自动驾驶感知的主流范式
未来,BEV+Transformer很有可能会替代之前的2D+CNN,逐步成为自动驾驶感知的主流范式。
这意味着,从硬件芯片开始,到传感器摄像头、软件算法、模型部署、数据采集标定等,都需要有相应的适配和变化。
第一,为了确保视觉感知重叠,对汽车摄像头数量的要求会有所提升,相应地,激光雷达的数量以及在感知中的作用会减少,也就是纯视觉技术路线会受到更多的青睐。
第二,Transformer是暴力美学,模型体量惊人,其运算还会消耗大量的存储及带宽空间,对芯片来说,除了需要进行相应算子适配以及底层软件优化外,在SOC层面需要对缓存和带宽要求进行增加。
第三,Transformer需要海量数据,会使得汽车数据采集、训练、标注的成本大幅度上升。
这些一定程度上,也会使得芯片、摄像头、标注等相关产业厂商受益。
总结
通过对BEV+Transformer的梳理,我主要有以下两点感受。
第一, 为什么BEV+Transformer会成为主流范式,我觉得背后核心还是第一性原理,就是智能驾驶要越来越近“人一样去驾驶”,映射到感知模型本身,BEV是一种更加自然的表达方式,而Transformer实现了CV和NLP的统一。
第二, 随着工业和学术界的研究推进,近段时间BEV+Transformer从普及到走向量产,在当前智能驾驶商业受阻的背景下,或许是一个难得的亮点。但从时间维度上看,BEV+Transformer已是历史产物,占用网络已经来了,大模型也在路上,或许几个月、最多一两年之后,一个真正的“王炸”会出现,会让之前的积累全部推倒重来,我们要对每一波的迭代怀有敬畏之心,先从技术开始,之后就是商业模式的大变革。
有关算法迭代、大模型、Mapless、GPT等是我们近期持续跟进的重点,有兴趣欢迎随时与我沟通交流。
作者 | 汽车人参考






