


 1406
1406
目前,AI模型的主干网络正从CNN转变为Transformer,因为后者具有精度高、全局性特征、多模态和迁移性强的特点。在云端,用Transformer已经可以实现虚拟教师、AI智能对话(例如ChatGPT),代码自动生成等场景,可以用GPU加速计算Transformer,但在端侧——如机器人、智慧教育等场景——目前的处理器在Transformer的加速计算上还面临难题。
视海芯图微电子创始人、董事长许达文解释,终端产品往往采用NPU来加速计算,不同于CNN是以计算为核心的架构,Transformer更多是以数据为中心的计算架构,Embedding、Attention等都是访存密集型算子,这样要么很难映射到NPU上,要么映射利用率很低,需要CPU配合,存在Transformer映射中断的挑战。
这些算力挑战需要创新的处理能力。许达文认为,当前的算力革命就是DRAM存算技术,是Transformer是否能自顶而下,普遍进入广泛AI应用领域的关键。DRAM存算技术结合了3D集成工艺和创新架构,可以有效克服系统访存瓶颈,实现加速Transformer,同时极大减低芯片功耗。在工艺上,3D集成可以把DRAM/内存和计算逻辑进行垂直互联,百倍提高数据互联带宽。在架构上,电路定制、模型并行和数据并行等多种技术可以围绕Transformer结构进行定向加速。
在这个方向上,视海芯图创新性使用DRAM存算技术进行神经网络运算和图像处理加速,解决了其中的存储墙问题,实现了超低功耗的算力芯片。日前,在2023松山湖中国IC创新高峰论坛上,该公司介绍了其最新推出的一款智能视觉SoC SH1580 ,集成了4亿晶体管,采用12nm工艺。
除了3D视觉ISP,4核Arm CPU A53外,该芯片的核心技术是视海芯图自主设计的多态神经网络处理器(PTPU)。该处理器具备4 ToPS算力,不仅能支持善于提取局部特征的CNN,也对Transformer、Bert和点云神经网络等新兴AI模型有针对性加速效果。
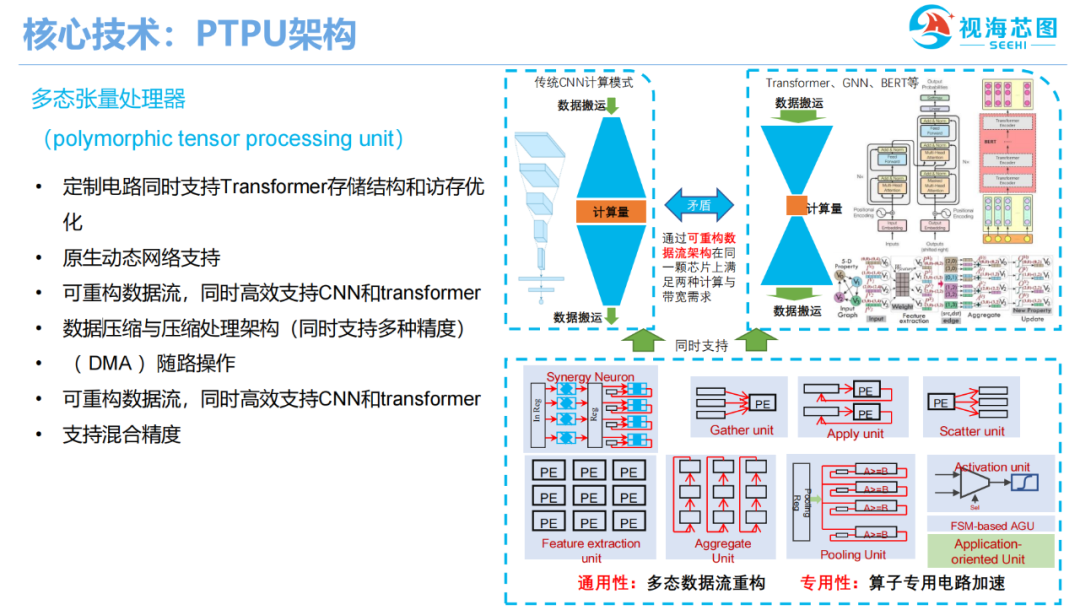
图:SH100核心技术多态神经网络处理器(PTPU)
SH100采用多通道DDR,具备超高数据高带宽,针对新兴AI模型优化的片上存储模块设计,可以为片内计算阵列提供可重构的高速数据流,从而,让视频流AI处理、多模态数据融合和点云神经网络等在AIoT终端落地实现可能,该芯片目标应用集中在智能教育硬件、服务机器人和ADAS等领域。
目前,视海芯图正在和中国科学院计算技术研究所展开合作,并获得舜宇光学、网易有道和虹软科技3家上市公司的战略投资,已经和股东合作,围绕IoT、元宇宙和车载方面的核心图像处理算法进行存算一体加速,研发通用芯片。






