


 1728
1728
视觉应用作为人工智能最普及的基础设施层,重要性却不言而喻。它可以说是人工智能机器的‘眼睛’,赋予它感知的能力,使它能够‘看懂’这个世界。而计算机视觉中的深度神经网络(DNN)架构则是这双眼睛的‘视网膜’,赋予了它可视的源泉。
CNN横空出世
2012年,一个名为AlexNet的CNN算法赢得了年度计算机视觉竞赛——ImageNet大规模视觉识别挑战赛(ILSVRC)的冠军。该竞赛的任务是让机器进行学习并基于ImageNet数据集‘分类’1000个不同的图像,AlexNet实现了15.3%的top-5错误率。而往届基于传统编程模型的获胜者,它们实现的top-5错误率大约为26%,至此,CNN横空出世。
CNN(Convolutional Neural Network)即卷积神经网络,它是一种前馈神经网络,也是计算机视觉中最主要和最经常使用的DNN架构。CNN在大型图像处理方面表现出色,可以说它的出现在图像分类领域具有革命性意义。
在CNN出现前,图像识别和分类对于人工智能来说是一个难题,原因有二,一是图像需要处理的数据量很大,导致成本高、效率低;二是,图像在数字化过程中很难保留其原有特征,导致图像处理的准确率不高。
而CNN的出现很好解决了上述两大难题。CNN主要由三个部分构成,卷积层、池化层和全连接层。卷积层负责提取图像特征,将大量的图像数据‘大事化小’,即将图像的大量参数降维为少量参数,再做处理,而池化层则对提取的图像特征进行降维及防止过拟合,保留图像的原始特征,最后通过全连接层输出结果。
随着CNN模型的不断完善,在2016年和2017年的ILSVRC挑战赛上,获胜的CNN甚至实现了比人类更高的图像分类准确度。这也让CNN在诸多视觉领域得到广泛应用,如目标检测、场景分割和全景分割等。
但CNN是一种只关注局部信息的网络结构,将它使用在图像特征提取上或许还可以,但它在文本信息处理上则难以捕捉和存储长距离的依赖信息。
Transformer应运而生
2017年,Google Brain在题为《Attention is all you need》的论文中首次详细介绍了Transformer(转换器)模型,该模型最初是为执行自然语言处理(NLP)任务而设计的,具体应用包括翻译、问答以及对话式AI等。目前大火的ChatGPT的GPT-3训练模型就是Transformer模型的一种。
而后在2021年,Google Brain又尝试将Transformer模型应用于图像分类,取得了令人惊讶的结果。通常Transformer模型在执行NLP任务时,需要处理的是一连串单词和符号,Google Brain将其应用于图像分类时,则是将图像切分成一个个小块,然后将这些小块图像中的像素放入矢量中,再将这些矢量传送至Transformer中进行处理,最后得到的分类准确率甚至比当时最先进的CNN还高。
Transformer Vs CNN架构对比
那为何Transformer能够挑战在视觉应用领域称霸十几年的CNN呢?这可以从两者的结构和机制对比中窥得一二。
如下图所示的Transformer和CNN(以3X3卷积为例)的架构图可见,Transformer和CNN的架构非常相似,Transformer的Feed Forward层的功能和CNN的1X1卷积层的相同,都使用矩阵乘法对像素中的每个点进行线性变换。
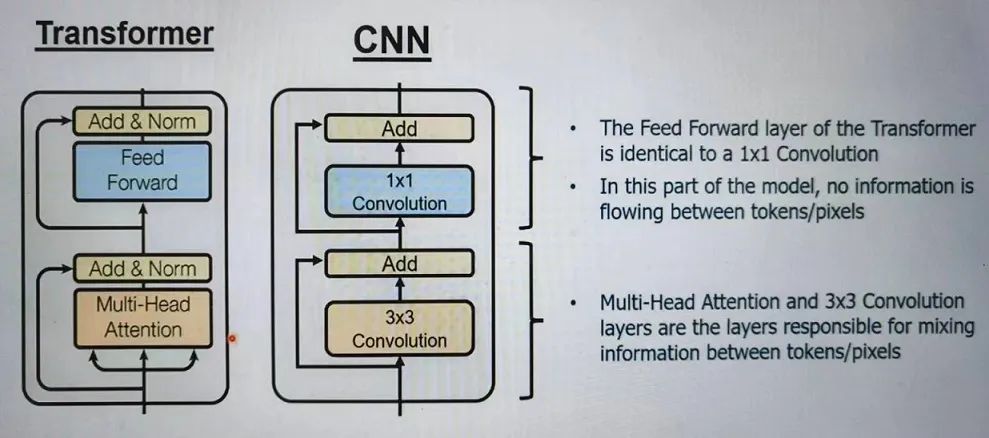
(图源:新思科技)
Transformer和CNN架构最大的不同在于Multi-Head Attention层和3X3卷积层。这两个层的作用都是混合相邻像素之间的信息。但如下图所示,这两个机制混合信息的方式则非常不同。

(图源:新思科技)
以卷积方式混合信息是基于各个像素的固定空间位置,以3X3卷积为例,它只采用相邻像素(即中心像素周围的9个像素)来计算加权和;而Attention混合信息的方式则不是基于固定空间位置的像素,而是更关注于权重。例如,它会学习其它像素的类型,获取其它像素与目标像素之间相似的权重,从而判断出需要混合哪些像素。
所以,相较于卷积,Attention机制具有更强的学习能力和表达更复杂关系的能力。此外,Transformer还有一个CNN没有的特性,即Embedding,它的主要功能是为输入的像素添加位置信息。
从上可以看出,两种架构各有特点。但实时视觉应用不仅需要准确度,还需要更高的性能(fps)、缩小模型尺寸以及功率和面积效率等。Transformer在准确度方面高于CNN,但在fps方面则可能逊色于CNN;Transformer的attention机制可进行全局特征的提取,而CNN在局部建模方面更有效。两者各具特色,在未来的AI应用中,两者不会是替代关系,而更多的是组合应用。
加速器加持
随着人工智能技术的不断发展,不管是基于CNN还是Transformer架构,需要处理的任务都越来越复杂,需要计算的量也将显著增加,从而导致它们的结构越来越庞大。为了加快任务完成的时间和效率,这时,就需要加速器的加持。但目前很多专门为CNN设计的加速器无法兼容有效地执行Transformer。
Synopsys的ARC® NPX6 NPU IP提供了一个两全其美的解决方案,它是可同时应用于CNN和Transformer的AI加速器。NPX6的计算单元中包含卷积加速器(Convolution Accelerator),该加速器旨在处理对CNN和转换器都至关重要的矩阵乘法。此外,张量加速器(Tencor Accelerator)也至关重要,因为它可以处理所有其他非卷积张量算子集架构(TOSA)运算,包括转换器运算。
Transformer跨界之旅不停歇
目前,Transformer架构在不断地被加强和扩展,衍生出很多不同的变种模型,使其应用领域不断扩大,跨界之旅不停歇。
2022年,Google团队提出了Vision Transformer(ViT),直接利用Transformer对图像进行分类,而无需卷积网络。该模型的准确率和识别时间均高于当时最先进的CNN架构。所以,ViT一经发布,就引起了业界轰动,它已经成为了图像分类领域最著名的方法之一。但ViT需要进行的计算量非常大,导致其fps性能降低。
而Swin Transformer则采用了一种新的Attention方式,将Transformer的应用扩展至视频领域。视频相较于图片来说,增加了时间维度,所以需要进行三维计算。SwinTransformer通过将Attention分别应用于时间和空间,可以实现动作识别,被广泛应用于动作分类等领域。
除了基于Transformer进行扩展外,也有AI团队将CNN和Transformer进行组合应用。特斯拉AI团队就使用Transformer对矢量空间进行预测。CNN首先对车身上安装的每个摄像头拍摄的图片进行特征提取,Transformer则基于这些提取特征进行预测。
苹果于2022年初推出的MobileViT也是CNN和Transformer结合应用的案例之一。MobileViT针对移动应用程序的视觉分类创建了轻量级模型。与仅使用CNN的MobileNet相比,MobileViT使相同尺寸的模型(6M系数)的准确度提高了3%。
结语
如前文所述,CNN和Transformer各有各的技术特点,未来很长一段时间内,两者不会是取代和被取代的关系,而是互相融合、取长补短,两者组合应用的案例会越来越多。这种组合或许也会引领新一代AI的发展。
作者: 苏岚





