


 648
648
在昨日举行的“2022 百度云智峰会·智算峰会”上,NVIDIA解决方案工程中心高级技术经理路川分享了以“应用驱动的数据中心计算架构演进”为题的演讲,探讨GPU数据中心的发展趋势,以及介绍NVIDIA在构建以GPU为基础的数据中心架构方面的实践经验。以下为内容概要。
应用对算力需求的不断增长,以GPU为核心的分布式计算系统已经成为大模型应用重要的一环
数据中心的发展是由应用驱动的。随着AI的兴起、普及,AI大模型训练在各领域的逐步应用,人们对数据中心的GPU算力、GPU集群的需求在飞速增长。传统的以CPU为基础的数据中心架构,已很难满足AI应用的发展需求,NVIDIA也一直在探索如何构建一个高效的以GPU为基础的数据中心架构。
我将从三个方面跟大家一起探讨这个话题:一,应用驱动;二,NVIDIA最新一代GPU SuperPOD的架构设计;三,未来GPU数据中心、GPU集群的发展趋势 。
我们首先看下近几年AI应用的发展趋势。总体上来讲,应用业务对计算的需求是不断飞速增长。我们以目前最流行的三个业务方向为例说明。

第一个应用场景,AI应用。我们可以从最左边的图表中可以看到,近10年CV 和 NLP模型的变化,这两类业务场景是AI领域最流行、最成功,也是应用范围最为广泛的场景。在图表中我们可以看到,CV从2012年的AlexNet 到最新的wav2vec,模型对计算的需求增长了1,000倍。
NLP模型在引入Transformer 结构后,模型规模呈指数级增长,Transformer已成为大模型、大算力的代名词。目前CV类的应用也逐步引入Transformer结构来构建相关的AI模型,不断提升应用性能。数据显示在最近两年内关于Transformer AI模型的论文增长了150倍,而非Transformer结构的AI模型相关论文增长了大概8倍。
我们可以看到人们越来越意识到大模型在AI领域的重要性,和对应用带来的收益。同时大模型也意味着算力的需求的增长,以及对数据中心计算集群需求的增长。
第二个应用场景,数字孪生、虚拟人等模拟场景与AI的结合也是最近两年的应用热点。人们通过数字孪生、虚拟人可以更好地对企业生产流程进行管控,线上虚拟交互有更好的体验,这背后都需要要巨大的算力资源来满足渲染、实时交互等功能。
第三个应用场景,量子计算,也是最近几年我们计算热点的技术。量子计算是利用量子力学,可以比传统的计算机更快地解决复杂的问题。量子计算机的发展还处在非常前期的阶段,相关的量子算法的研究和应用也需要大量的算力做模拟支撑。
前面我们提到了AI大模型的业务应用,为什么要用到大模型,大模型可以给我们带来什么样的收益?
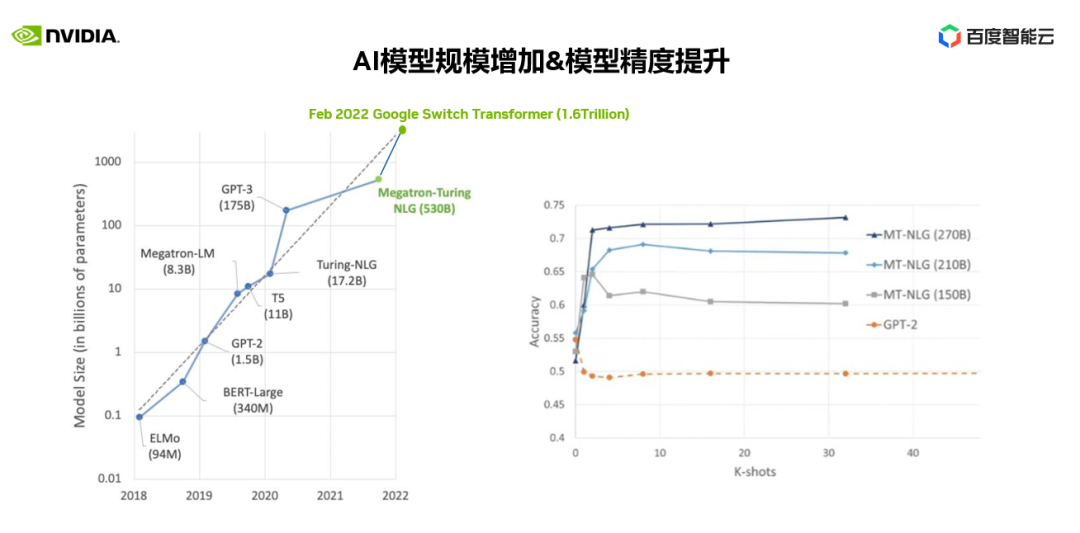
在右图中我们可以看到1.5B GPT-2 和MT-NLG在150B-270B不同参数规模下对应用精度的影响。
我们可以清楚地看到大模型对应用精度的效果,尤其是对复杂、泛化的业务场景的表现尤为突出。同时大模型在预测(inference)端正在快速发展,优化特定场景、特定行业的性能,优化预测端计算资源使用等,相信在不久的将来会有更多像ChatGPT一样令人惊叹的应用在行业落地。这都将会推动大模型基础研究,推动对训练大模型所需算力的建设。一个以GPU为基础的分布式计算系统也是大模型应用所必须的。
AI大模型训练为什么要用到GPU集群,用到更大规模的GPU?它能给我们的训练带来什么样的收益?这边我们用两个实际的例子作为参考。
一个应用是BERT 340M 参数规模,使用Selene A100 SuperPOD集群,训练完成则需要0.2分钟,在使用1/2个集群规模,训练完成需要0.4分钟,使用1/4个集群规模下训练完成则需要0.7分钟。我们可以看到在小参数规模下,使用几十台DGX A100也可以快速完成整个训练任务,对于整个训练的迭代影响并不大。
另一个是Megatron 530B参数规模的NLP大模型,训练这个530B参数的大模型,使用整个Selene SuperPOD集群资源则需要3.5周、近一个月的时间才能完成,而使用1/2、1/4集群节点规模的情况下,则需要数月的训练时间才能完成整个训练,这对于大模型研发人员来说是不可接受的。另外研发人员的时间成本是非常宝贵的,研究到产品化的时间也是非常关键的,我们不可能把时间浪费在训练等待上。
在管理层面,构建一个GPU集群,通过集群的作业调度和管理系统,可以优化调度各种类型、各种需求的GPU任务,使用集群的GPU资源,以最大化利用GPU集群。在Facebook的一篇论文中提到,通过作业调度管理系统,Facebook AI超级计算系统上每天可以承载3.5万个独立的训练任务。
因此,GPU规模和集群管理对于提升分布式任务的运行效率非常关键。
集群的最关键的地方就是通信,集群任务的调试优化重点也是在使用各种并行方式优化通信策略。在GPU集群中,通信主要分为两个部分,一个是节点内通信,一个是节点间通信。

在左图中我们可以看到节点间通信NVLink对于它的重要性。图中示例使用tensor 并行的方式,在节点间分别采用NVLink和采用PCIe 4.0进行通信的对比,我们可以看到,NVLink环境下程序的通信时间仅需70ms(毫秒),而PCIe环境下通信时间则需要656ms,当用多个节点组成的集群环境下差距会更加明显。
在右图中,我们使用7.5B 的AI模型,采用TPS=4,PPS=1,数据并行DPS=64的情况下,在32个集群的节点规模下,不同网卡对分布式训练任务的影响。紫色部分代表了通信占比,绿色代表计算时间占比。我们可以清晰地看到网卡数量、网络带宽对分布式应用的性能的影响。
GPU集群应用于AI训练也是最近几年才逐步在客户中开始应用。在AI发展的早期,模型较小,大部分采单机多卡或是多机数据并行的方式进行训练,所以对GPU集群的要求并不是很高。2018年11月,NVIDIA第一次推出基于DGX-2的SuperPOD架构,也是看到AI发展的趋势,看到了AI应用对GPU分布式集群在AI训练中的需求。
SuperPOD的架构也在不断地演进和优化。通过NVIDIA实战经验和性能优化验证,SuperPOD可以帮助客户迅速构建起属于自己的高性能GPU分布式集群。
NVIDIA最新一代Hopper GPU架构下SuperPod的集群拓扑
下面我来简单介绍下,最新一代Hopper GPU架构下SuperPOD的集群拓扑。
计算节点采用Hopper最新的GPU,相比较与Ampere GPU性能提升2~3倍。计算性能的提升需要更强的网络带宽来支撑,所以外部的网络也由原来的200Gb升级为400Gb,400Gb的网络交换机可以最多支撑到64个400Gb网口,所以每个计算POD由原来的20个变为32个。更高的计算密度,在一个POD内GPU直接的通信效率要更高。
NDR Infiniband 网络、AR、SHARP、SHIELD等新的特性,在路由交换效率、聚合通信加速、网络稳定性等方面有了进一步的提升,可以更好的支持分布式大规模GPU集群计算性能和稳定性。在存储和管理网络方面,增加了智能网卡的支持,可以提供更多的管理功能,适应不同客户的需求。
未来数据中心GPU集群架构的发展趋势:计算、互联、软件
下面,站在NVIDIA的角度,我们再来探讨一下,未来数据中心GPU集群的架构发展趋势。整个GPU的集群主要有三个关键因素,分别是:计算、互联和软件。

一,计算。集群的架构设计中,单节点计算性能越高,越有优势,所以在GPU选择上我们会采用最新的GPU架构,这样会带来更强的GPU算力。
在未来两年,Hopper将成为GPU分布式计算集群的主力GPU。Hopper GPU我相信大家已经很了解,相关特性我在这就不在赘述。我只强调一个功能,Transformer引擎。
在上文应用的发展趋势里,我们也提到了以Transformer为基础的AI大模型的研究。Transformer 也是大模型分布式计算的代名词,在Hopper架构里新增加了Transformer 引擎,就是专门为Transformer结构而设计的GPU加速单元,这会极大地加速基于Transformer结构的大模型训练效率。
二,互联。GPU是CPU的加速器,集群计算的另外一个重要组成部分是CPU。NVIDIA会在2023年发布基于Arm 72核、专为高性能设计的Grace CPU,配置500GB/s LPDDR5X 内存,900GB/s NVLink, 可以跟GPU更好地配合,输出强大的计算性能。
基于Grace CPU,会有两种形态的超级芯片,一是Grace+Hopper,二是Grace+Grace。
Grace+Hopper,我们知道GPU作为CPU加速器,并不是所有应用任务都适用于GPU来加速,其中很关键的一个点就是GPU和CPU之间的存储带宽的瓶颈,Grace+Hopper超级芯片就是解决此类问题。
在Grace Hopper超级芯片架构下,GPU可以通过高速的NVLink直接访问到CPU显存。对于大模型计算,更多应用迁移到GPU上加速都有极大的帮助。
Grace+Grace ,是在一个模组上可以提供高达144 CPU核,1 TB/s LPDDR5X的高速存储,给集群节点提供了强劲的单节点的CPU计算性能,从而提升整个集群效率。

之前我们所熟知的NVLink,都是应用在节点内GPU和GPU之间的互联。在Grace Hopper集群下,NVLink可以做到节点之间互联,这样节点之间GPU-GPU,或GPU-CPU,或CPU-CPU之间,都可以通过高速的NVLink进行互联,可以更高效地完成大模型的分布式计算。
在未来也许我们可以看到更多业务应用迁移到Grace+Hopper架构下,节点之间的NVLlink高速互联也许会成为一个趋势,更好地支持GPU分布式计算。
智能网卡在集群中的应用,首先智能网卡技术并不是一个新的技术,各家也有各家的方案,传统上我们可以利用智能网卡把云业务场景下的Hypervisor管理、网络功能、存储功能等卸载到智能网卡上进行处理,这样可以给云客户提供一个云生的计算资源环境。NVIDIA智能网卡跟百度也有很深的合作,包括GPU集群裸金属方案也都配置了NVIDIA智能网卡进行管理。
在非GPU的业务场景下,我们看到智能网卡对HPC应用业务的加速,主要是在分子动力学,气象和信号处理应用上,通过对集群中聚合通信的卸载,我们可以看到应用可以获得20%以上的收益。智能网卡技术也在不断更新、升级,业务场景也在不断探索。相信在未来的GPU集群上会有更多的业务或优化加速可以使用到智能网卡技术。
三,软件。数据中心基础设施是基础底座,如何能够更高效、快速、方便地应用到基础架构变革所带来的优势,软件生态的不断完善和优化是关键。
针对不同的业务场景,NVIDIA提供了SuperPOD、OVX 等数据中心基础设施的参考架构,可以帮助用户构建最优的数据中心基础设施架构。
上层提供了各种软件加速库,如cuQuantum 可以帮助客户直接在GPU集群上模拟量子算法计算,Magnum IO用来加速数据中心GPU集群和存储系统的访存IO效率,提升整个集群计算效率。
在未来会有更多的软件工具、行业SDK,来支撑数据中心架构的使用,让各领域的研发人员不需要了解底层细节,更加方便、快速地使用到数据中心GPU集群的的最优性能。






