


 立即注册,领取新人专属福利!
立即注册,领取新人专属福利! 1072
1072
大会中推出了很多新项目,在整个战略中Amazon Redshift处于“核心C位”,在存储、查询和分析中都发挥重要价值,而今年Redshift新发布的功能特性也有点多得数不过来,这些功能特性有一个核心目标就是化繁为简。在经过了从0到1的技术突破和从1到100的规模化后,亚马逊云科技正在努力尝试着做从1到0的事情,这里的从1到0是面向客户的,衡量的是客户的复杂任务。即使是从100的手动操作到1的自动化仍然不够,目标是从1到0,消除这些琐碎和不应该困扰的工作,实现像Serverless一样的目标,让客户全身心投入到业务中去。
更优雅的数据分享
从Redshift到Redshifts
Redshift用户通常都拥有不止一个集群(或者Serverless),那它们之间是怎么进行有效地协作呢?答案是Data Sharing。Redshift的Data Sharing功能从推出到现在已经快一年半时间了,客户将它用在组织内实现不同的数据架构,如Data Mesh等。Data Sharing功能使用起来非常方便,并且支持跨账号、跨区域以及跨集群和Serverless模式,这过程中数据并没有任何移动,是通过Zero Copy的方式实现(又一个从1到0的故事)。
一个生产者对应一个消费者的情况非常容易理解并进行管理,但是企业面临的往往是数十个甚至成百上千的不同数据之间需要相互共享,记录并维护这些相互交错的数据共享就变得十分困难,这时候企业尤其需要一个能集中管理跨不同组织和部门的数据共享权限工具,Lake Formation再次出场。
Lake Formation服务的目标就是为了简化数据的集中管理,此前Lake Formation基于独特的集中权限模型(数据目录资源和基于标签的授权模式),可以对数据湖的数据进行细粒度的集中访问控制(数据表、行、列等),并且可以很方便地与其他服务如Athena、QuickSight,当然还有Redshift的集成。这一次,Lake Formation和Redshift的集成再一次加强了,提供了集中管理Redshift Data Sharing的能力,客户可以使用统一的Lake Formation集中查看和管理Redshift Data Sharing,也可以让数据消费者发现和使用这些Redshift Data Sharing,并继续沿用经过验证的细粒度权限机制,保障数据使用的安全性。
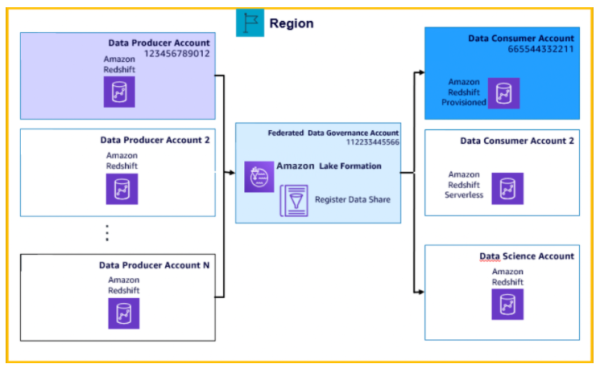
另外,可以根据自己的实际情况,使用Lake Formation集中地、安全地管理Redshift的大规模数据共享,或许用来构建按需自主使用的、面向领域的、数据即服务的数据架构。
Amazon DataZone是数据治理方向的一大惊喜。即使有Lake Formation带飞,企业中的数据使用者仍然很难找到合适的业务数据,尤其是数据还分散在不同的国家、地区、部分以及各种数据账户中。即使数据使用方找到数据,往往也不了解其中数据的真实含义,需要自己对其进行一系列的摸索,当然,这些都是通过了数据访问控制的难关之后。
数据工程师、数据科学家和数据分析师如何能一起愉快地协作,而不是各个团队做着重复的技术工作,没有带出真实的业务价值输出,这始终是一个企业需要不断思考的问题。Amazon DataZone给出了一个选项,目标是打通业务数据通道,实现从一开始就能反映业务领域属性的数据架构设计,再配合发布/订阅和事件驱动的模式,一切都是为了简化数据的使用,让数据发挥真正的价值。
当然,DataZone和本文主角Redshift的集成是无缝衔接的,Redshift数仓既可以是数据生产者也可以是数据消费者。
稳定、可靠、合规
居家旅行必备
上述强大的功能全速推进着Redshift向前发展,但同时它也需要一个稳定的基座。今年re:Invent发布的其他几项更新同样发挥着重要作用。
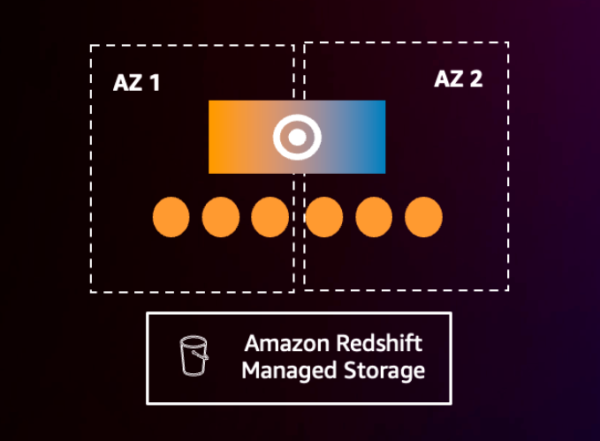
首先是多AZ部署(没错,Redshift原来是单AZ模式,但是不用担心,RA3节点类型集群的数据是持久化在S3中的),像其他多AZ部署服务一样(例如RDS),客户可以选择在多个可用区部署Redshift实现提高可用性。多AZ部署通过自动恢复的能力来缩短恢复时间,特别适用于关键的业务分析场景,可以保证RPO=0、RTO<1分钟的数据恢复。
数据备份集中管理服务Amazon Backup新补充了对Redshift的支持,可以集中地管理备份策略,进一步保护Redshift的数据。另外,对于许多国内出海的用户,他们尤其需要关注GDPR等隐私法规,所以新功能动态数据屏蔽千万不能错过,它可以用来保护Redshift中的敏感数据信息,并且在不用为不同用户创建不同数据拷贝的前提下完成。




.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)

.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)








 [下载]LAT1440 如何在特定串口工具上以不同颜色显示信息
[下载]LAT1440 如何在特定串口工具上以不同颜色显示信息
