
|
1210| 0
|
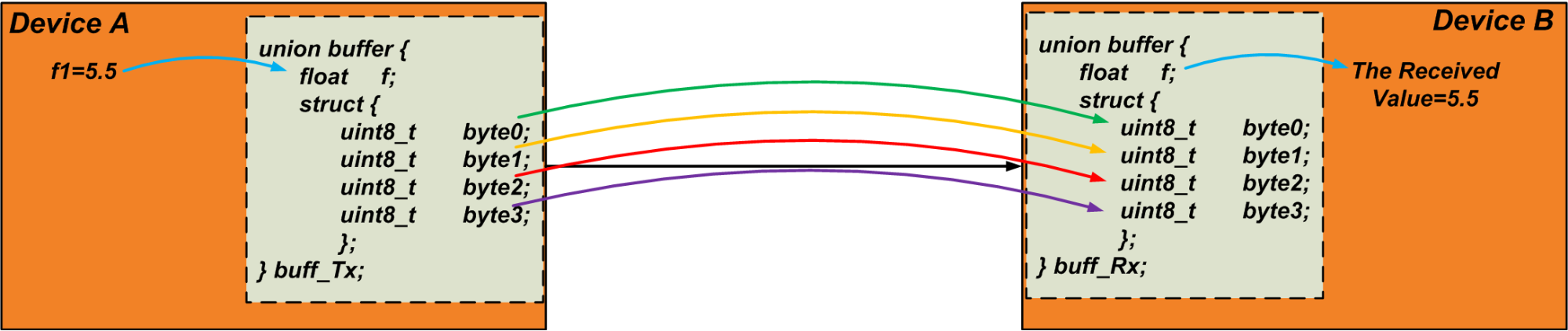
[经验] C语言union用于打包和拆包数据 |

 发表于 2020-12-1 20:16:09
发表于 2020-12-1 20:16:09
关闭
站长推荐
站长推荐 /3
/3 

ICP经营许可证 苏B2-20140176 苏ICP备14012660号-2 苏州灵动帧格网络科技有限公司 版权所有.

Powered by Discuz! X3.4
Copyright © 2001-2024, Tencent Cloud.
|
1210| 0
|
[经验] C语言union用于打包和拆包数据 |
/3
Powered by Discuz! X3.4
Copyright © 2001-2024, Tencent Cloud.